
0
Pohledy

Pokud jste se naučili několik počítačových programovacích jazyků, možná jste slyšeli termín, analýza textu. To se používá ke zjednodušení komplexních datových hodnot souboru. Tento článek vám pomůže zjistit, jak analyzovat text pomocí jazyka. Kromě toho, pokud jste se setkali s chybou v analýze textu x, budete v článku vědět, jak chybu analýzy opravit.
Obsah
V tomto článku jsme ukázali úplného průvodce analýzou textu různými způsoby a také stručně uvedli úvod do analýzy textu.
Než se ponoříte, naučte se koncepty analýzy textu pomocí libovolného kódu. Je důležité znát základy jazyka a kódování.
K analýze textu se používá zpracování přirozeného jazyka nebo NLP, což je podpole domény umělé inteligence. K analýze textu se používá jazyk Python, který je jedním z jazyků patřících do této kategorie.
Kódy NLP umožňují počítačům porozumět lidským jazykům a zpracovat je tak, aby byly vhodné pro různé aplikace. Aby bylo možné na jazyk aplikovat techniky ML nebo strojového učení, nestrukturovaná textová data musí být převedena na strukturovaná tabulková data. Pro dokončení analýzy se používá jazyk Python ke změně programových kódů.
Analýza textu jednoduše znamená převod dat z jednoho formátu do jiného formátu. Formát, ve kterém je soubor uložen, musí být analyzován nebo převeden na soubor v jiném formátu, aby jej uživatel mohl používat v různých aplikacích.
Důvody, proč musí být text analyzován, jsou uvedeny v této části a je nezbytnou podmínkou znalosti, než budete vědět, jak text analyzovat.
Třída DataFrame v jazyce Python má všechny požadované funkce pro analýzu textu. Tato vestavěná knihovna obsahuje potřebné kódy pro analýzu dat libovolného formátu do jiného formátu.
Stručné představení třídy DataFrame
DataFrame Class je datová struktura bohatá na funkce, která se používá jako nástroj pro analýzu dat. Jedná se o výkonný nástroj pro analýzu dat, který lze použít k analýze dat s minimálním úsilím.
Pandy jazyka Python pomáhají při provádění operací ve stylu SQL nebo databáze s maximální dokonalostí, aby se zabránilo chybám při analýze textu x. Obsahuje také některé IO nástroje, které pomáhají při analýze souborů CSV, MS Excel, JSON, HDF5 a dalších datových formátů.
Přečtěte si také:Opravte chybu, která se vyskytla při pokusu o proxy požadavek
Proces analýzy textu pomocí třídy DataFrame
Chcete-li vědět, jak analyzovat text, můžete použít standardní proces pomocí třídy DataFrame uvedené v této části.
Poznámka: Psaní kódu na prázdný DataFrame může být zdlouhavé a složité. Pandy umožňují vytvářet data ve třídě DataFrame z těchto datových typů. Data v primitivním datovém typu lze tedy snadno analyzovat na požadovaný datový formát.
Možnost I: Standardní formát
Zde je vysvětlena standardní metoda formátování libovolného souboru s určitým formátem dat, jako je CSV.
Poznámka: Zde je proměnná s názvem res se používá k provedení číst funkce dat v souboru data.txt pomocí dovezených pand pd. Formát dat vstupního textu je uveden v CSV formát.
Níže je uveden příklad kódu pro proces vysvětlený výše a pomůže vám pochopit, jak analyzovat text.
importovat pandy jako pdres = pd.read_csv(‘data.txt’)res
V tomto případě, pokud zadáte hodnoty dat do souboru data.txt jako [1,2,3], bude analyzován a zobrazen jako 1 2 3.
Možnost II: Metoda řetězce
Pokud text zadaný do kódu obsahuje pouze řetězce nebo alfa znaky, lze k oddělení a analýze textu použít speciální znaky v řetězci, jako jsou čárky, mezery atd. Proces je podobný běžným operacím s interními řetězci. Chcete-li zjistit, jak opravit chybu analýzy, musíte sledovat proces analýzy textu pomocí této možnosti, jak je vysvětleno níže.
Například v níže uvedeném kódu speciální znaky v řetězci můj_řetězec, což jsou, ',' a ':“ jsou identifikovány. Tento proces je třeba provést opatrně, aby nedošlo k chybě při analýze textu x.
Řetězec je například rozdělen na hodnoty textových dat na základě speciálních znaků identifikovaných pomocí příkazu split.
Ukázkový kód pro proces vysvětlený výše je uveden níže.
my_string = 'Jména: Technika, počítač'sfinal = [name.strip() pro jméno v my_string.split(‘:’)[1].split(‘,’)]print(“Jména: {}”.format (sfinal))
V tomto případě by se výsledek analyzovaného řetězce zobrazil, jak je uvedeno níže.
Názvy: [‘Tech‘, ‚computer‘]
Chcete-li získat lepší přehlednost a vědět, jak analyzovat text při použití textového řetězce, a pro smyčka a kód je upraven následovně.
my_string = 'Jména: Technika, počítač's1 = muj_string.split(‘:’)s2 = s1[1]s3 = s2.split(‘,’)s4 = [name.strip() pro jméno v s3]pro idx, položka ve výčtu([s1, s2, s3, s4]):print(“Krok {}: {}”.format (idx, item))
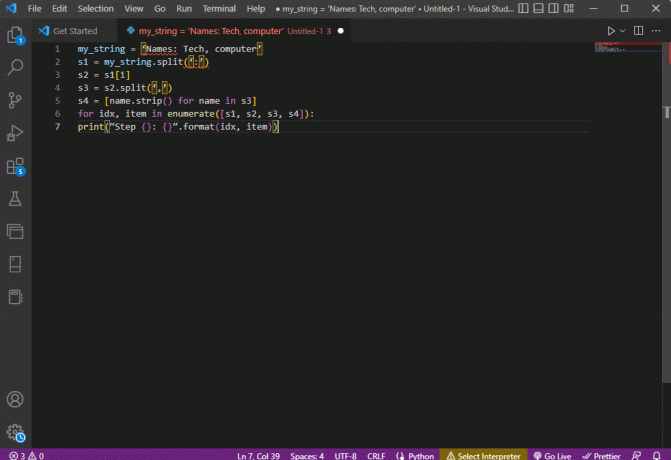
Výsledek analyzovaného textu pro každý z těchto kroků se zobrazí, jak je uvedeno níže. Můžete si všimnout, že v kroku 0 je řetězec oddělen na základě speciálního znaku : a hodnoty textových dat jsou v dalších krocích odděleny na základě znaku.
Krok 0: [‚Jména‘, ‚Tech, počítač‘]Krok 1: Technika, počítačKrok 2: [‘ Tech‘, ‚ computer‘]Krok 3: [‚Tech‘, ‚computer‘]
Možnost III: Analýza komplexního souboru
Ve většině případů data souboru, která je třeba analyzovat, obsahují různé datové typy a datové hodnoty. V tomto případě může být obtížné analyzovat soubor pomocí metod popsaných výše.
Funkce analýzy komplexních dat v souboru spočívá v tom, že se hodnoty dat zobrazí v tabulkovém formátu.
Než se ponoříte do učení, jak analyzovat text touto metodou, je nutné naučit se několik základních pojmů. Analýza hodnot dat se provádí na základě regulárních výrazů nebo Regex.
Regex vzory
Chcete-li vědět, jak opravit chybu analýzy, musíte se ujistit, že vzory regulárních výrazů ve výrazech jsou správné. Kód pro analýzu datových hodnot řetězců by zahrnoval běžné vzory Regex uvedené níže v této části.
Regulární výrazy
Moduly regulárních výrazů jsou hlavní součástí balíku pandas v jazyce Python a nesprávné re může vést k chybě při analýze textu x. Je to malý jazyk vložený do Pythonu pro nalezení vzoru řetězce ve výrazu. Regulární výrazy nebo Regex jsou řetězce se speciální syntaxí. Umožňuje uživateli porovnat vzory v jiných řetězcích na základě hodnot v řetězcích.
Regex je vytvořen na základě datového typu a požadavku na výraz v řetězci, jako je např Řetězec = (.*)\n. Regulární výraz se v každém výrazu používá před vzorem. Symboly používané v regulárních výrazech jsou uvedeny níže a pomohou vám zjistit, jak analyzovat text.
RegexObjects
RegexObject je návratová hodnota pro funkci kompilace a používá se k vrácení objektu MatchObject, pokud výraz odpovídá hodnotě shody.
1. MatchObject
Protože logická hodnota MatchObject je vždy True, můžete použít an -li příkaz k identifikaci pozitivních shod v objektu. V případě použití -li výraz, skupina, na kterou se index odkazuje, se používá ke zjištění shody objektu ve výrazu.
2. Metody MatchObject
Při hledání toho, jak analyzovat text, je důležité vědět, že MatchObject má dvě základní metody, jak jsou uvedeny níže. Pokud je v zadaném výrazu nalezen MatchObject, vrátí svou instanci, jinak vrátí None.
Funkce regulárních výrazů
Funkce regulárního výrazu jsou řádky kódu, které se používají k provedení určité funkce určené uživatelem ze sady pořízených datových hodnot.
Poznámka: K zápisu funkcí se pro regulární výrazy používají nezpracované řetězce, aby se předešlo chybám při analýze textu x. To se provádí přidáním dolního indexu r před každým vzorem ve výrazu.
Níže jsou vysvětleny běžné funkce používané ve výrazech.
1. re.findall()
Tato funkce vrací všechny vzory v řetězci, pokud je nalezena shoda, a vrací prázdný seznam, pokud není nalezena žádná shoda. Například funkce, string = re.findall(‚[aeiou]‘, název_souboru regulárního výrazu) se používá k nalezení výskytu samohlásky v názvu souboru.
2. re.split()
Tato funkce se používá k rozdělení řetězce v případě, že je nalezena shoda se zadaným znakem, jako je mezera. V případě, že není nalezena žádná shoda, vrátí prázdný řetězec.
3. re.sub()
Funkce nahradí odpovídající text obsahem dané proměnné nahradit. Na rozdíl od jiných funkcí, pokud není nalezen žádný vzor, je vrácen původní řetězec.
4. výzkum()
Jednou ze základních funkcí, které vám pomohou naučit se analyzovat text, je funkce vyhledávání. Pomáhá při hledání vzoru v řetězci a vrácení objektu shody. Pokud vyhledávání selže při identifikaci shody, není vrácena žádná hodnota.
5. re.compile (vzor)
Tato funkce se používá ke kompilaci vzorů regulárních výrazů do objektu RegexObject, který byl popsán dříve.
Další požadavky
Uvedené požadavky jsou další funkcí, kterou používají pokročilí programátoři při analýze dat.
Přečtěte si také:Jak nainstalovat NumPy na Windows 10
Proces analýzy textu
Způsob analýzy textu v této složité možnosti je popsán níže.
Příkaz data = pd. DataFrame (data) se používá k vytvoření pandas DataFrame z hodnot dict. Alternativně můžete pro příslušný účel použít následující příkazy, jak je uvedeno níže.
Posledním krokem k tomu, abyste věděli, jak analyzovat text, je otestovat analyzátor pomocí if prohlášení přiřazením hodnot k proměnné data a vytisknout jej pomocí tisknout (data) příkaz.
Příklad kódu pro vysvětlení výše je uveden zde.
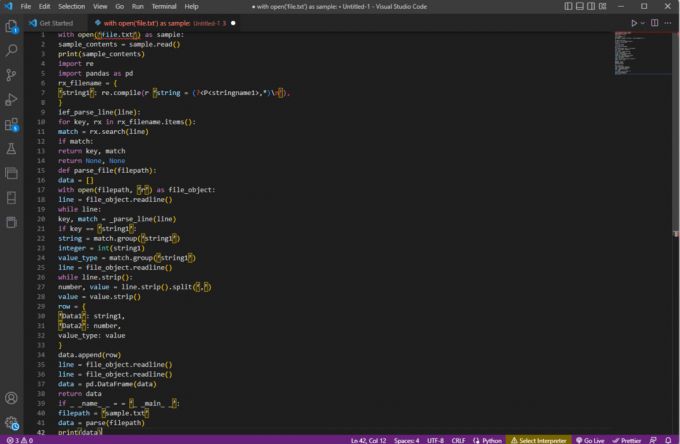
s open('file.txt') jako příklad:sample_contents = sample.read()tisk (sample_contents)import reimportovat pandy jako pdrx_filename = {‘řetězec1’: re.compile (r ‘řetězec = (?,*)\n'),
}ief_parse_line (řádek):pro klíč, rx v rx_filename.items():shoda = rx.search (řádek)pokud se shodují:návratový klíč, zápasreturn None, Nonedef parse_file (cesta k souboru):data = []s open (filepath, ‚r‘) jako file_object:line = file_object.readline()zatímco linka:klíč, shoda = _parse_line (řádek)if key == 'řetězec1':string = match.group(‘řetězec1’)celé číslo = int (řetězec1)value_type = match.group(‘řetězec1’)line = file_object.readline()while line.strip():číslo, hodnota = line.strip().split(‘,’)value = value.strip()řádek = {"Data1": řetězec1,"Data2": číslo,value_type: hodnota}data.append (řádek)line = file_object.readline()line = file_object.readline()data = pd. DataFrame (data)vrátit dataif _ _name_ _ = = „_ _main_ _“:cesta k souboru = ‘sample.txt’data = analyzovat (cesta k souboru)tisknout (data)
Proces převodu textu nebo korpusu na tokeny nebo menší části na základě určitých pravidel se nazývá tokenizace. Chcete-li se naučit, jak opravit chybu analýzy, je důležité analyzovat příkazy tokenizace slova v kódu. Podobně jako u regulárního výrazu lze v této metodě vytvářet vlastní pravidla a pomáhá v úlohách předběžného zpracování textu, jako je mapování slovních druhů. V této metodě se také provádějí činnosti, jako je vyhledávání a přiřazování běžných slov, čištění textu a příprava dat pro pokročilé techniky textové analýzy, jako je analýza sentimentu. Pokud je tokenizace nesprávná, může dojít k chybě při analýze textu x.
Knihovna NLTK
Tento proces využívá populární knihovnu jazykových nástrojů s názvem NLTK, která má bohatou sadu funkcí pro provádění mnoha úloh NLP. Ty lze stáhnout prostřednictvím balíčků Pip nebo Pip Installs. Chcete-li vědět, jak analyzovat text, můžete použít základní balíček distribuce Anaconda, který ve výchozím nastavení obsahuje knihovnu.
Formy tokenizace
Běžnými formami této metody jsou slovní tokenizace a větná tokenizace. Díky tokenu na úrovni slova první vytiskne jedno slovo pouze jednou, zatímco druhý vytiskne slovo na úrovni věty.
Proces analýzy textu
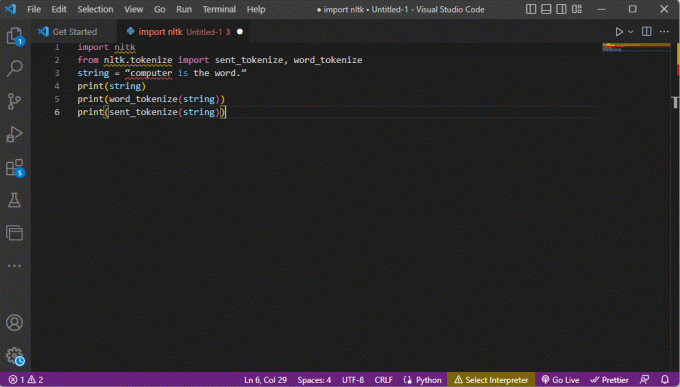
Kód vysvětlující výše uvedené kroky pro tokenizaci je uveden zde.
importovat nltkz nltk.tokenize import send_tokenize, word_tokenizestring = "počítač je to slovo."tisknout (provázek)tisknout (slovo_tokenizace (řetězec))tisknout (sent_tokenize (řetězec))
Přečtěte si také:Jak opravit chybu javascript: void (0).
Podobně jako u třídy DataFrame lze třídu DocParser použít k analýze textu v kódu. Třída vám umožňuje volat funkci parse s cestou k souboru.
Proces analýzy textu
Chcete-li vědět, jak analyzovat text pomocí třídy DocParser, postupujte podle pokynů uvedených níže.
Poznámka: Chcete-li vědět, jak opravit chybu analýzy, musí být tato funkce správně implementována.
Textový nástroj Parse se používá k extrahování konkrétních dat z proměnných a jejich mapování na jiné proměnné. To je nezávislé na jakýchkoli jiných nástrojích používaných v úloze a nástroj BPA Platform se používá ke konzumaci a výstupu proměnných. Pro přístup použijte zde uvedený odkaz Nástroj pro analýzu textu online a použijte dříve uvedené odpovědi o tom, jak analyzovat text.

TextFieldParser využíval objekty k analýze a zpracování velmi velkých souborů, které jsou strukturované a oddělené. V této metodě lze použít šířku a sloupec textu, jako jsou soubory protokolu nebo starší databázové informace. Metoda analýzy je podobná iteraci kódu přes textový soubor a používá se hlavně k extrahování polí textu podobných metodám manipulace s řetězci. To se provádí za účelem tokenizace oddělených řetězců a polí různých šířek pomocí definovaného oddělovače, jako je čárka nebo tabulátor.
Funkce pro analýzu textu
K analýze textu v této metodě lze použít následující funkce.
Metody k nalezení MatchObject
Existují dva základní způsoby, jak najít MatchObject v kódu nebo v analyzovaném textu.
V obou případech, pokud pole při provádění analýzy nebo hledání způsobu analýzy textu neodpovídá zadanému formátu, a MalformedLineException je vrácena výjimka.
Jako konečnou a jednoduchou metodu analýzy textu můžete použít MS Excel aplikace jako analyzátor k vytváření souborů oddělených tabulátory a čárkami. To by pomohlo při křížové kontrole s vaším analyzovaným výsledkem a pomohlo by to najít, jak opravit chybu analýzy.
1. Vyberte datové hodnoty ve zdrojovém souboru a stiskněte klávesy Ctrl + C společně zkopírujte soubor.
2. Otevři Vynikat aplikace pomocí vyhledávacího panelu systému Windows.

3. Klikněte na A1 a stiskněte tlačítko klávesy Ctrl + V současně vložit zkopírovaný text.
4. Vybrat A1 přejděte na Data a klikněte na Text do sloupců možnost v Datové nástroje sekce.
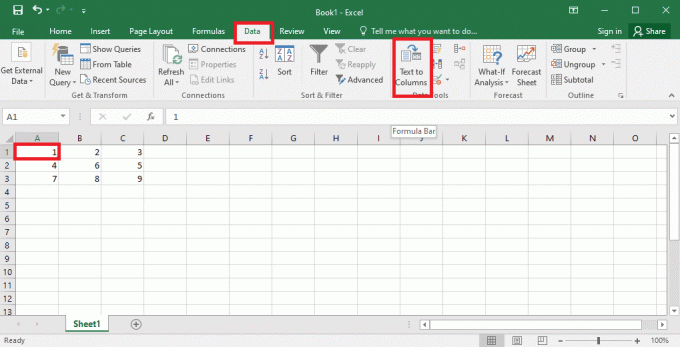
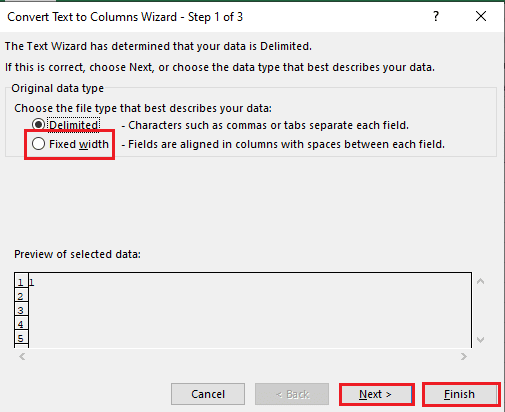
5A. Vybrat Vymezené možnost, pokud a čárka nebo tab jako oddělovač se použije mezera a klikněte na další a Dokončit tlačítka.

5B. Vybrat Pevná šířka možnost, přiřaďte hodnotu pro oddělovač a klikněte na další a Dokončit tlačítka.
Přečtěte si také:Jak opravit chybu Move Excel Column Error
Chyba při analýze textu x může nastat na zařízeních Android jako: Chyba analýzy: Při analýze balíčku došlo k problému. K tomu obvykle dochází, když se aplikace nepodaří nainstalovat z Obchodu Google Play nebo když je spuštěna aplikace třetí strany.
Chybový text x se může objevit, pokud je seznam znakových vektorů zacyklen a ostatní funkce tvoří lineární model pro výpočet hodnot dat. Chybová zpráva je Error in parse (text = x, keep.source = FALSE):
Článek si můžete přečíst na jak opravit chybu analýzy na Androidu zjistit příčiny a metody opravy chyby.
Kromě řešení v průvodci můžete vyzkoušet následující opravy.
Doporučeno:
Článek pomáhá při výuce jak analyzovat text a naučit se, jak opravit chybu analýzy. Dejte nám vědět, která metoda pomohla opravit chybu v analýze textu x a která metoda analýzy je upřednostňována. Podělte se o své návrhy a dotazy v sekci komentářů níže.

