
0
Visninger

Hvis du har lært et par computerprogrammeringssprog, har du måske hørt udtrykket, parsing af tekst. Dette bruges til at forenkle de komplekse dataværdier i filen. Artiklen hjælper dig med at vide, hvordan du analyserer tekst ved hjælp af sproget. Ud over dette, hvis du har stået over for fejl i parse tekst x, vil du vide, hvordan du retter parse fejl i artiklen.
Indholdsfortegnelse
I denne artikel har vi vist en komplet guide til at analysere tekst på forskellige måder og også kort givet en introduktion til at analysere tekst.
Før du dykker ned for at lære begreberne at analysere tekst ved hjælp af en hvilken som helst kode. Det er vigtigt at kende til det grundlæggende i sproget og kodningen.
For at parse tekst bruges Natural Language Processing eller NLP, som er et underfelt af Artificial Intelligence-domænet. Python-sprog, som er et af de sprog, der hører til kategorien, bruges til at parse tekst.
NLP-koderne gør det muligt for computere at forstå og behandle menneskelige sprog for at gøre dem egnede til forskellige applikationer. For at anvende ML- eller Machine Learning-teknikker på sproget, skal de ustrukturerede tekstdata konverteres til strukturerede tabeldata. For at fuldføre parsingsaktiviteten bruges Python-sproget til at ændre programkoderne.
At analysere tekst betyder simpelthen at konvertere data fra et format til et andet format. Formatet, som filen er gemt i, skal parses eller konverteres til en fil i et andet format for at gøre det muligt for brugeren at bruge den i forskellige applikationer.
Årsagerne til, at teksten skal parses, er givet i dette afsnit, og det er en forudsætning for viden, før man ved, hvordan man analyserer tekst.
DataFrame-klassen i Python-sproget har alle de nødvendige funktioner til at parse tekst. Dette indbyggede bibliotek rummer de nødvendige koder til at parse data af ethvert format til et andet format.
Kort introduktion til DataFrame Class
DataFrame Class er en funktionsrig datastruktur, som bruges som et dataanalyseværktøj. Dette er et kraftfuldt dataanalyseværktøj, der kan bruges til at analysere data med minimal indsats.
Python-sprogets pandaer hjælper med at udføre SQL- eller databaselignende operationer med den største perfektion for at undgå fejl i parse tekst x. Den indeholder også nogle IO-værktøjer, der hjælper med at analysere filerne i CSV, MS Excel, JSON, HDF5 og andre dataformater.
Læs også:Ret fejl, der opstod under forsøg på at proxy-anmodning
Proces med at analysere tekst ved hjælp af DataFrame Class
For at vide, hvordan man parser tekst, kan du bruge standardprocessen ved hjælp af DataFrame Class givet i dette afsnit.
Bemærk: At skrive koden på en tom DataFrame kan være kedeligt og komplekst. Pandaerne tillader at skabe data på DataFrame-klassen fra disse datatyper. Derfor kan dataene i den primitive datatype let parses til det krævede dataformat.
Mulighed I: Standardformat
Standardmetoden til at formatere enhver fil med et bestemt dataformat, såsom CSV, er forklaret her.
Bemærk: Her hedder variablen res bruges til at udføre Læs funktion af dataene i filen data.txt ved hjælp af pandaerne importeret i pd. Dataformatet for inputteksten er angivet i CSV format.
Et eksempel på en kode for processen forklaret ovenfor er givet nedenfor og vil hjælpe med at forstå, hvordan man analyserer tekst.
importer pandaer som pdres = pd.read_csv(‘data.txt’)res
I dette tilfælde, hvis du indtaster dataværdierne i filen data.txt såsom [1,2,3], ville det blive parset og vist som 1 2 3.
Mulighed II: Strengmetode
Hvis teksten givet til koden kun indeholder strenge eller alfategn, kan specialtegnene i strengen såsom kommaer, mellemrum osv. bruges til at adskille og parse teksten. Processen ligner de almindelige interne strengoperationer. For at finde ud af, hvordan du løser parse-fejl, skal du følge processen med at analysere teksten ved at bruge denne mulighed, som er forklaret nedenfor.
For eksempel i koden nedenfor, specialtegnene i strengen min_streng, som er, ',' og ':’ er identificeret. Denne proces skal udføres omhyggeligt for at undgå fejl i parse tekst x.
For eksempel er strengen opdelt i tekstdataværdier baseret på de specialtegn, der identificeres ved hjælp af split-kommandoen.
Eksempelkoden for processen forklaret ovenfor er givet nedenfor.
my_string = 'Navne: Teknik, computer'sfinal = [name.strip() for navn i my_string.split(':')[1].split(',')]print("Navne: {}".format (sfinal))
I dette tilfælde vil resultatet af den parsede streng blive vist som vist nedenfor.
Navne: ['Tech', 'computer']
For at få bedre klarhed og vide, hvordan man analyserer tekst, mens du bruger strengteksten, a til loop anvendes, og koden ændres som følger.
my_string = 'Navne: Teknik, computer's1 = min_streng.split(':')s2 = s1[1]s3 = s2.split(‘,’)s4 = [name.strip() for navn i s3]for idx, element i enumerate([s1, s2, s3, s4]):print("Trin {}: {}".format (idx, element))
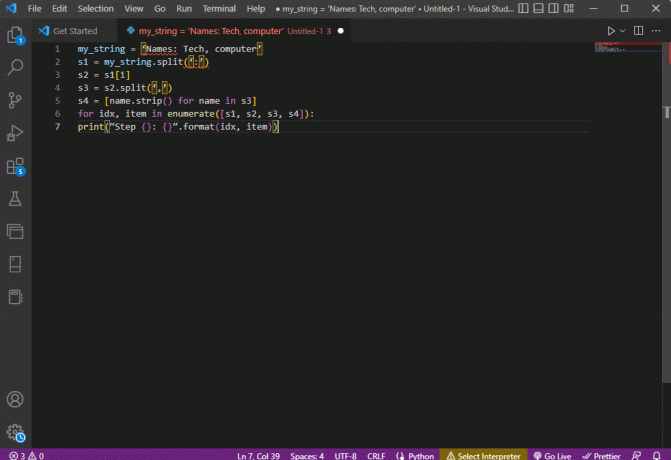
Resultatet af den analyserede tekst for hvert af disse trin vises som vist nedenfor. Du kan bemærke, at i trin 0 er strengen adskilt baseret på specialtegnet : og tekstdataværdierne adskilles baseret på tegnet i yderligere trin.
Trin 0: ['Navne', 'Tech, computer']Trin 1: Teknik, computerTrin 2: ['Tech', 'computer']Trin 3: ['Tech', 'computer']
Mulighed III: Parsing af kompleks fil
I de fleste tilfælde indeholder fildataene, der skal parses, forskellige datatyper og dataværdier. I dette tilfælde kan det være svært at parse filen ved hjælp af de metoder, der er forklaret tidligere.
Funktionerne ved at parse de komplekse data i filen er at få dataværdierne til at blive vist i et tabelformat.
Før du dykker ned i at lære at analysere tekst i denne metode, er det nødvendigt at lære et par grundlæggende begreber. Parsingen af dataværdierne udføres baseret på regulære udtryk eller Regex.
Regex mønstre
For at vide, hvordan man løser parse-fejl, skal du sikre dig, at regex-mønstrene i udtrykkene er korrekte. Koden til at parse strengenes dataværdier ville involvere de almindelige Regex-mønstre, der er angivet nedenfor i dette afsnit.
Regelmæssige udtryk
Regulære udtryksmoduler er en stor del af pandas-pakken i Python-sproget, og en forkert gengivelse kan føre til en fejl i parse tekst x. Det er et lillebitte sprog indlejret i Python for at finde strengmønsteret i udtrykket. Regulære udtryk eller Regex er strenge med speciel syntaks. Det giver brugeren mulighed for at matche mønstre i andre strenge baseret på værdierne i strengene.
Regex oprettes baseret på datatypen og kravet til udtrykket i strengen, som f.eks Streng = (.*)\n. Regex bruges før mønsteret i hvert udtryk. Symbolerne, der bruges i de regulære udtryk, er anført nedenfor og vil hjælpe med at vide, hvordan man analyserer tekst.
RegexObjects
RegexObject er en returværdi for kompileringsfunktionen og bruges til at returnere et MatchObject, hvis udtrykket matcher matchværdien.
1. MatchObject
Da den boolske værdi af MatchObject altid er True, kan du bruge en hvis sætning for at identificere de positive match i objektet. I tilfælde af brug af hvis sætning, bruges den gruppe, som indekset henviser til, til at finde ud af, om objektet i udtrykket passer.
2. Metoder til MatchObject
Mens du finder ud af, hvordan man analyserer tekst, er det vigtigt at vide, at MatchObject har to grundlæggende metoder som anført nedenfor. Hvis MatchObject findes i det angivne udtryk, ville det returnere sin instans, ellers ville det returnere Ingen.
Regulære udtryksfunktioner
Regex-funktioner er kodelinjer, der bruges til at udføre en bestemt funktion, som angivet af brugeren fra det anskaffede sæt af dataværdier.
Bemærk: For at skrive funktionerne bruges rå strenge til de regulære udtryk for at undgå fejl i parse tekst x. Dette gøres ved at tilføje subscriptet r før hvert mønster i udtrykket.
De almindelige funktioner, der bruges i udtrykkene, er forklaret nedenfor.
1. re.findall()
Denne funktion returnerer alle mønstrene i strengen, hvis der findes et match, og returnerer en tom liste, hvis der ikke findes et match. For eksempel funktionen, string = re.findall('[aeiou]', regex_filnavn) bruges til at finde vokalforekomsten i filnavnet.
2. re.split()
Denne funktion bruges til at opdele strengen i tilfælde af et match med et angivet tegn, såsom mellemrum. Hvis der ikke findes noget match, returnerer det en tom streng.
3. re.sub()
Funktionen erstatter den matchede tekst med indholdet af den givne erstatningsvariabel. I modsætning til andre funktioner, hvis der ikke findes noget mønster, returneres den oprindelige streng.
4. forskning()
En af de grundlæggende funktioner til at hjælpe med at lære at analysere tekst er søgefunktionen. Det hjælper med at søge efter mønsteret i strengen og returnere matchobjektet. Hvis søgningen mislykkes med at identificere matchet, returneres ingen værdi.
5. re.compile (mønster)
Denne funktion bruges til at kompilere regulære udtryksmønstre i et RegexObject, som blev diskuteret tidligere.
Andre krav
De anførte krav er en ekstra funktion, der bruges af avancerede programmører i dataanalyse.
Læs også:Sådan installeres NumPy på Windows 10
Processen med at analysere tekst
Metoden til at parse teksten i denne komplekse mulighed er beskrevet som angivet nedenfor.
Kommandoen data = pd. DataFrame (data) bruges til at skabe en pandas DataFrame ud fra dict-værdierne. Alternativt kan du bruge følgende kommandoer til det respektive formål som angivet nedenfor.
Det sidste trin for at vide, hvordan man analyserer tekst, er at teste parseren ved hjælp af hvis erklæring ved at tildele værdierne til en variabel data og udskrive den ved hjælp af print (data) kommando.
Eksempelkoden til forklaringen ovenfor er givet her.
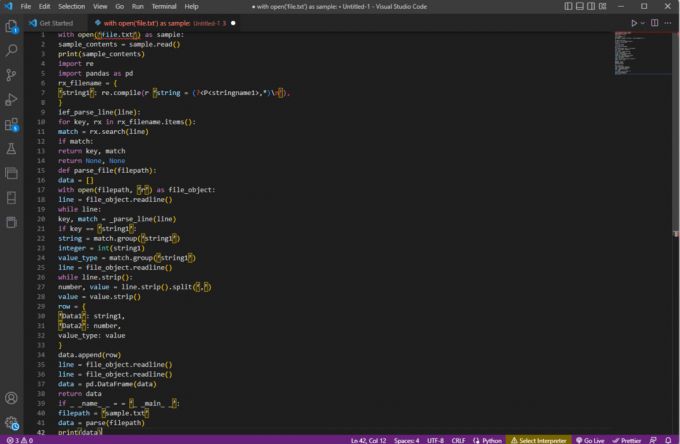
med open('file.txt') som eksempel:sample_contents = sample.read()print (sample_contents)import vedrimporter pandaer som pdrx_filename = {'string1': re.compile (r 'string = (?,*)\n’),
}ief_parse_line (linje):for nøgle, rx i rx_filename.items():match = rx.search (linje)hvis match:returnøgle, matchretur Ingen, Ingendef parse_file (filsti):data = []med åben (filsti, 'r') som fil_objekt:line = file_object.readline()mens linje:nøgle, match = _parse_line (linje)hvis nøgle == 'streng1':string = match.group(‘string1’)heltal = int (streng1)værdi_type = match.group('streng1')line = file_object.readline()while line.strip():tal, værdi = line.strip().split(',')værdi = værdi.strimmel()række = {'Data1': streng1,'Data2': nummer,værditype: værdi}data.append (række)line = file_object.readline()line = file_object.readline()data = pd. DataFrame (data)returnere datahvis _ _navn_ _ = = '_ _main_ _':filsti = 'sample.txt'data = parse (filsti)print (data)
Processen med at konvertere en tekst eller et korpus til tokens eller mindre stykker baseret på visse regler kaldes tokenisering. For at lære at rette parse-fejl er det vigtigt at analysere ordtokeniseringskommandoer i koden. I lighed med regex kan egne regler oprettes i denne metode, og den hjælper med tekstforbehandlingsopgaver såsom at kortlægge dele af tale. Også aktiviteter som at finde og matche almindelige ord, rense tekst og gøre dataene klar til avancerede tekstanalyseteknikker som følelsesanalyse udføres i denne metode. Hvis tokeniseringen er forkert, kan der opstå fejl i parse tekst x.
NLTK bibliotek
Processen tager hjælp af det populære sprogværktøjsbibliotek kaldet NLTK, som har et rigt sæt funktioner til at udføre mange NLP-job. Disse kan downloades gennem Pip- eller Pip-installationspakkerne. For at vide, hvordan man analyserer tekst, kan du bruge basispakken til Anaconda-distributionen, som inkluderer biblioteket som standard.
Former for tokenisering
De almindelige former for denne metode er ord-tokenisering og sætningstokenisering. På grund af symbolet på ordniveau udskriver førstnævnte kun ét ord én gang, mens sidstnævnte udskriver ordet på sætningsniveau.
Processen med at analysere tekst
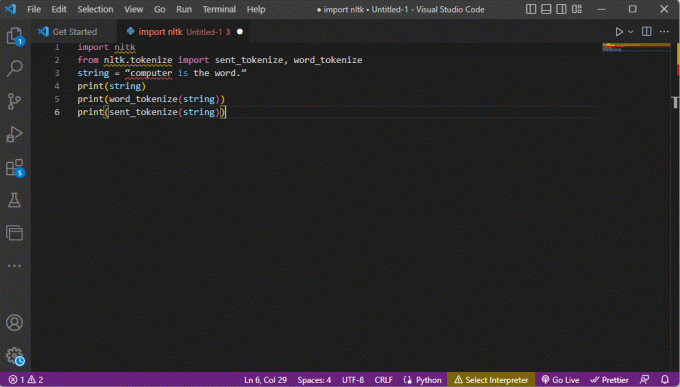
Koden, der forklarer trinene til tokenisering ovenfor, er givet her.
import nltkfra nltk.tokenize import send_tokenize, word_tokenizestring = "computer er ordet."print (streng)print (word_tokenize (streng))print (sent_tokenize (streng))
Læs også:Sådan rettes javascript: void (0) Fejl
I lighed med DataFrame-klassen kan Class DocParser bruges til at parse teksten i koden. Klassen giver dig mulighed for at kalde parse-funktionen med filstien.
Processen med at analysere tekst
For at vide, hvordan man analyserer tekst ved hjælp af DocParser-klassen, skal du følge instruktionerne nedenfor.
Bemærk: For at vide, hvordan man løser parse-fejl, skal denne funktion implementeres korrekt.
Parse tekstværktøjet bruges til at udtrække specifikke data fra variabler og kortlægge dem til andre variabler. Dette er uafhængigt af andre værktøjer, der bruges i en opgave, og BPA Platform-værktøjet bruges til at forbruge og udlæse variabler. Brug linket her for at få adgang til Parse Text Tool online og brug de svar, der er givet tidligere om, hvordan man analyserer tekst.

TextFieldParser brugte objekter til at parse og behandle meget store filer, der er strukturerede og afgrænsede. Bredden og kolonnen af tekst såsom logfiler eller ældre databaseoplysninger kan bruges i denne metode. Parsingmetoden ligner at iterere koden over en tekstfil og bruges hovedsageligt til at udtrække tekstfelter, der ligner strengmanipulationsmetoder. Dette gøres for at tokenisere afgrænsede strenge og felter med forskellige bredder ved hjælp af den definerede afgrænsning, såsom komma eller tabulatormellemrum.
Funktioner til at analysere tekst
Følgende funktioner kan bruges til at analysere teksten i denne metode.
Metoder til at finde MatchObject
Der er to grundlæggende metoder til at finde MatchObject i koden eller den parsede tekst.
I begge tilfælde, hvis et felt ikke matcher det angivne format, mens du udfører parsing eller finder, hvordan man parser tekst, en MalformedLineException undtagelse returneres.
Som en sidste og enkel metode til at parse teksten kan du bruge MS Excel app som en parser til at oprette tabulatorseparerede og kommaseparerede filer. Dette vil hjælpe med at krydstjekke med dit parsede resultat og hjælpe med at finde ud af, hvordan man løser parse-fejl.
1. Vælg dataværdierne i kildefilen, og tryk på Ctrl + C-tasterne sammen for at kopiere filen.
2. Åbn Excel app ved hjælp af Windows-søgelinjen.

3. Klik på A1 celle og tryk på Ctrl + V tasterne samtidig for at indsætte den kopierede tekst.
4. Vælg A1 celle, naviger til Data fanen, og klik på Tekst til kolonner mulighed i Dataværktøjer afsnit.
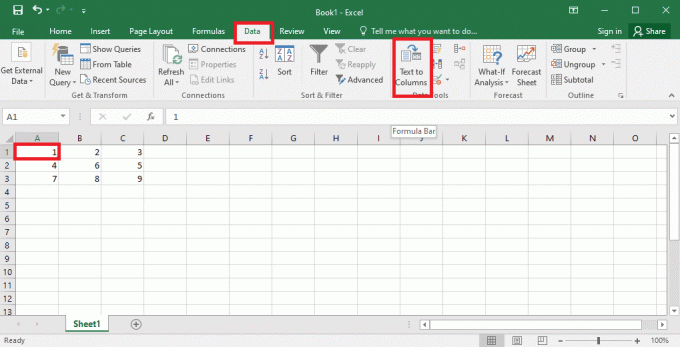
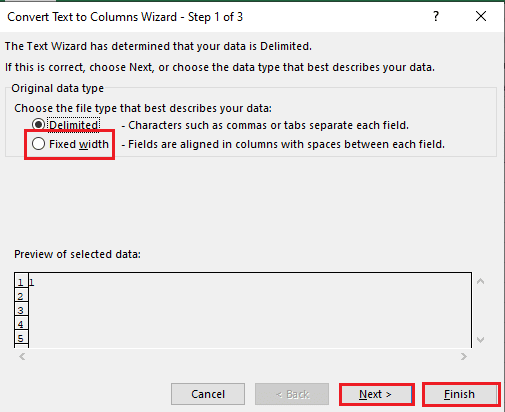
5A. Vælg Afgrænset mulighed hvis en komma eller fanen plads bruges som separator, og klik på Næste og Afslut knapper.

5B. Vælg Fast bredde valgmulighed, tildel en værdi for separatoren, og klik på Næste og Afslut knapper.
Læs også:Sådan rettes Flyt Excel-kolonnefejl
Fejl i parse tekst x kan forekomme på Android-enheder som, Parse Error: Der var et problem med at parse pakken. Dette sker normalt, når appen ikke kan installeres fra Google Play Butik, eller mens du kører en tredjepartsapp.
Fejlteksten x kan forekomme, hvis listen over tegnvektorer er sløjfet, og andre funktioner danner en lineær model til beregning af dataværdierne. Fejlmeddelelsen er Error in parse (tekst = x, keep.source = FALSE):
Du kan læse artiklen på hvordan man løser parse-fejl på Android at lære årsagerne og metoderne til at rette fejlen.
Ud over løsningerne i vejledningen kan du prøve følgende rettelser.
Anbefalede:
Artiklen hjælper i undervisningen hvordan man analyserer tekst og for at lære at rette parse-fejl. Fortæl os, hvilken metode der hjalp med at rette fejl i parse tekst x, og hvilken metode til parsing der foretrækkes. Del venligst dine forslag og spørgsmål i kommentarfeltet nedenfor.

