
0
Vaated

Kui olete õppinud mõnda arvutiprogrammeerimiskeelt, olete võib-olla kuulnud terminit teksti sõelumine. Seda kasutatakse faili keerukate andmeväärtuste lihtsustamiseks. Artikkel aitab teil teada, kuidas keele abil teksti sõeluda. Lisaks sellele, kui teil on teksti x sõelumisel ilmnenud viga, teate, kuidas artiklis parsimisviga parandada.
Sisukord
Selles artiklis oleme näidanud täielikku juhendit teksti sõelumiseks erinevatel viisidel ja lühidalt ka teksti sõelumise sissejuhatust.
Enne süvenemist tutvuge mis tahes koodi abil teksti sõelumise mõistetega. Oluline on teada keele põhitõdesid ja kodeerimist.
Teksti sõelumiseks kasutatakse loomuliku keele töötlemist või NLP-d, mis on tehisintellekti domeeni alamväli. Teksti sõelumiseks kasutatakse Pythoni keelt, mis on üks sellesse kategooriasse kuuluvatest keeltest.
NLP-koodid võimaldavad arvutitel mõista ja töödelda inimkeeli, et muuta need erinevate rakenduste jaoks sobivaks. ML-i või masinõppe tehnikate keelele rakendamiseks tuleb struktureerimata tekstiandmed teisendada struktureeritud tabeliandmeteks. Parsimise lõpuleviimiseks kasutatakse programmikoodide muutmiseks Pythoni keelt.
Teksti sõelumine tähendab lihtsalt andmete teisendamist ühest vormingust teise. Faili salvestamise vorming sõelutakse või teisendatakse erinevas vormingus failiks, et kasutaja saaks seda erinevates rakendustes kasutada.
Selles jaotises on ära toodud põhjused, miks teksti sõeluda tuleb ja see on eeltingimuseks teksti sõelumise oskus.
Pythoni keele DataFrame klassil on kõik teksti sõelumiseks vajalikud funktsioonid. Selles sisseehitatud raamatukogus on vajalikud koodid mis tahes vormingu andmete muusse vormingusse sõelumiseks.
DataFrame klassi lühitutvustus
DataFrame Class on funktsioonirikas andmestruktuur, mida kasutatakse andmeanalüüsi tööriistana. See on võimas andmeanalüüsi tööriist, mida saab kasutada andmete analüüsimiseks minimaalse pingutusega.
Pythoni keele pandad aitavad SQL-i või andmebaasi stiilis toiminguid teha ülimalt täiuslikult, et vältida vigu teksti x sõelumisel. See sisaldab ka mõningaid IO-tööriistu, mis aitavad analüüsida CSV-, MS Exceli-, JSON-, HDF5- ja muude andmevormingute faile.
Loe ka:Parandage puhverserveri taotluse proovimisel ilmnenud viga
Teksti sõelumise protsess DataFrame klassi abil
Et teada saada, kuidas teksti sõeluda, võite kasutada standardset protsessi, kasutades selles jaotises toodud DataFrame klassi.
Märge: Koodi kirjutamine tühjale DataFrame'ile võib olla tüütu ja keeruline. Pandad võimaldavad nendest andmetüüpidest luua DataFrame klassi andmeid. Seega saab primitiivse andmetüübi andmeid hõlpsasti nõutavasse andmevormingusse sõeluda.
Valik I: standardvorming
Siin selgitatakse standardmeetodit mis tahes faili vormindamiseks teatud andmevorminguga (nt CSV).
Märge: Siin on muutuja nimega res kasutatakse sooritamiseks lugeda failis olevate andmete funktsiooni data.txt aastal imporditud pandade kasutamine pd. Sisendteksti andmevorming on määratud CSV vormingus.
Allpool on toodud ülaltoodud protsessi näidiskood, mis aitab mõista, kuidas teksti sõeluda.
importida pandad pd-nares = pd.read_csv('data.txt')res
Sel juhul, kui sisestate faili andmeväärtused data.txt nagu näiteks [1,2,3], sõelutakse ja kuvatakse kujul 1 2 3.
II valik: stringimeetod
Kui koodile antud tekst sisaldab ainult stringe või alfamärke, saab teksti eraldamiseks ja sõelumiseks kasutada stringis olevaid erimärke, nagu koma, tühik jne. Protsess sarnaneb tavaliste sisemiste stringioperatsioonidega. Parsimisvea parandamise leidmiseks peate järgima teksti sõelumise protsessi selle valiku abil, mida selgitatakse allpool.
Näiteks allolevas koodis stringi erimärgid minu_string, mis on "," ja ":' on tuvastatud. Seda protsessi tuleb teha hoolikalt, et vältida vigu parsimise tekstis x.
Näiteks jagatakse string tekstiandmeteks, mis põhinevad split-käsuga tuvastatud erimärkidel.
Allpool on toodud ülaltoodud protsessi näidiskood.
my_string = 'Nimed: Tehnika, arvuti'sfinal = [nimi.riba() nime jaoks minu_stringis.split(':')[1].split(',')]print ("Nimed: {}".vorming (lõplik))
Sel juhul kuvatakse sõelutud stringi tulemus nagu allpool näidatud.
Nimed: ["Tech", "arvuti"]
Parema selguse saamiseks ja teadmiseks, kuidas stringi teksti kasutades teksti sõeluda, a jaoks tsüklit kasutatakse ja koodi muudetakse järgmiselt.
my_string = 'Nimed: Tehnika, arvuti's1 = minu_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [nimi.riba() nime jaoks s3-s]idx jaoks üksus loendis ([s1, s2, s3, s4]):print(“Step {}: {}”.vorming (idx, üksus))
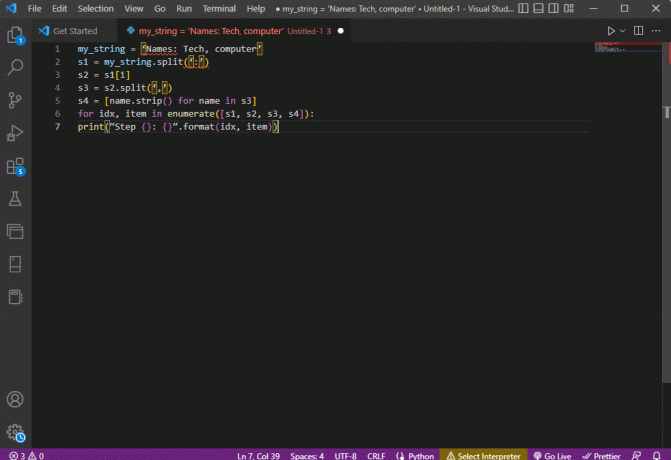
Kõigi nende sammude sõelutud teksti tulemus kuvatakse allpool näidatud viisil. Pange tähele, et sammus 0 eraldatakse string erimärgi alusel : ja tekstiandmete väärtused eraldatakse edasistes sammudes märgi alusel.
Samm 0: ["Nimed", "Technika, arvuti"]1. samm: tehnika, arvuti2. samm: [Tehnika, arvuti]3. samm: [Technika, arvuti]
Valik III: kompleksfaili sõelumine
Enamikul juhtudel sisaldavad sõelumist vajavad failiandmed erinevaid andmetüüpe ja andmeväärtusi. Sel juhul võib olla keeruline faili sõeluda, kasutades eelnevalt kirjeldatud meetodeid.
Failis olevate keerukate andmete sõelumise funktsioonid on andmeväärtuste kuvamine tabelivormingus.
Enne kui hakkate selle meetodi abil teksti sõeluma, peate õppima mõned põhimõisted. Andmeväärtuste sõelumine toimub regulaaravaldiste või regexi põhjal.
Regex mustrid
Et teada saada, kuidas parsimisviga parandada, peate tagama, et avaldiste regex-mustrid on õiged. Stringide andmeväärtuste sõelumiseks kasutatav kood hõlmab selles jaotises allpool loetletud tavalisi regexi mustreid.
Regulaaravaldised
Regulaaravaldise moodulid on Pythoni keeles pandapaketi põhiosa ja vale re võib põhjustada tõrke teksti x sõelumisel. See on Pythoni sisse manustatud väike keel, mis võimaldab leida avaldises stringimustri. Regulaaravaldised ehk Regex on spetsiaalse süntaksiga stringid. See võimaldab kasutajal sobitada teiste stringide mustreid stringide väärtuste põhjal.
Regex luuakse andmetüübi ja stringi avaldise nõude alusel, näiteks String = (.*)\n. Regexit kasutatakse igas avaldises enne mustrit. Regulaaravaldistes kasutatavad sümbolid on loetletud allpool ja aitavad teil teada, kuidas teksti sõeluda.
RegexObjects
RegexObject on kompileerimisfunktsiooni tagastusväärtus ja seda kasutatakse MatchObjecti tagastamiseks, kui avaldis vastab vaste väärtusele.
1. MatchObject
Kuna MatchObjecti Boole'i väärtus on alati True, võite kasutada a kui lause positiivsete vastete tuvastamiseks objektis. Kasutamise korral kui lause, kasutatakse avaldises oleva objekti sobivuse väljaselgitamiseks indeksi poolt viidatud rühma.
2. MatchObjecti meetodid
Teksti sõelumise otsimisel on oluline teada, et MatchObjectil on kaks allpool loetletud põhimeetodit. Kui MatchObject leitakse määratud avaldises, tagastaks see selle eksemplari, vastasel juhul tagastaks None.
Regulaaravaldise funktsioonid
Regex funktsioonid on koodiread, mida kasutatakse teatud funktsiooni täitmiseks, nagu kasutaja on hangitud andmeväärtuste hulgast määranud.
Märge: Funktsioonide kirjutamiseks kasutatakse regulaaravaldiste jaoks töötlemata stringe, et vältida vigu parsimise tekstis x. Seda tehakse alamindeksi lisamisega r enne iga avaldise mustrit.
Avaldistes kasutatavaid tavalisi funktsioone selgitatakse allpool.
1. re.findall()
See funktsioon tagastab vaste leidmisel kõik stringis olevad mustrid ja kui vastet ei leita, tagastab tühja loendi. Näiteks funktsioon, string = re.findall('[aeiou]', regex_failinimi) kasutatakse vokaali esinemise leidmiseks failinimes.
2. re.split()
Seda funktsiooni kasutatakse stringi poolitamiseks juhul, kui leitakse sobivus määratud märgiga, näiteks tühikuga. Kui vastet ei leita, tagastab see tühja stringi.
3. re.sub()
Funktsioon asendab sobitatud teksti antud asendusmuutuja sisuga. Vastupidiselt teistele funktsioonidele, kui mustrit ei leita, tagastatakse algne string.
4. re.search()
Üks põhifunktsioone, mis aitab teksti sõelumist õppida, on otsingufunktsioon. See aitab stringist mustrit otsida ja vasteobjekti tagastada. Kui otsing ei suuda vastet tuvastada, väärtust ei tagastata.
5. re.compile (muster)
Seda funktsiooni kasutatakse regulaaravaldise mustrite kompileerimiseks RegexObjectiks, millest oli varem juttu.
Muud nõuded
Loetletud nõuded on lisafunktsioon, mida kasutavad andmeanalüüsis edasijõudnud programmeerijad.
Loe ka:NumPy installimine Windows 10-sse
Teksti parsimise protsess
Selle keeruka suvandi teksti sõelumise meetodit kirjeldatakse järgmiselt.
Käsk andmed = pd. DataFrame (andmed) kasutatakse panda DataFrame'i loomiseks dikteerimisväärtustest. Teise võimalusena võite kasutada järgmisi käske vastaval eesmärgil, nagu allpool kirjeldatud.
Viimane samm teksti sõelumiseks on parseri testimine, kasutades kui avaldus määrates muutujale väärtused andmeid ja printige see kasutades print (andmed) käsk.
Siin on toodud ülaltoodud selgituse näidiskood.
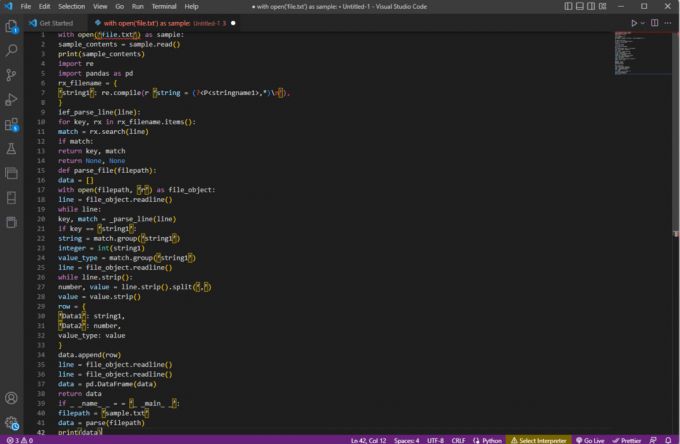
koos näidisega open ('file.txt'):sample_contents = sample.read()print (sample_contents)import reimportida pandad pd-narx_failinimi = {‘string1’: re.compile (r ‘string = (?,*)\n'),
}ief_parse_line (rida):võtme jaoks rx failis rx_filename.items():vaste = rx.search (rida)kui sobib:tagastusvõti, vastetagastama Pole, Poledef parse_file (failitee):andmed = []avatud (failitee, 'r') faili_objektina:rida = file_object.readline()samas rida:võti, vaste = _parse_line (rida)kui klahv == ‘string1’:string = match.group('string1')täisarv = int (string1)väärtuse_tüüp = match.group('string1')rida = file_object.readline()while line.strip():arv, väärtus = line.strip().split(‘,’)väärtus = väärtus.riba()rida = {'Andmed1': string1,"Data2": number,väärtuse_tüüp: väärtus}data.append (rida)rida = file_object.readline()rida = file_object.readline()andmed = pd. DataFrame (andmed)tagastada andmedif _ _name_ _ = = '_ _main_ _':filepath = 'näidis.txt'andmed = sõelumine (failitee)print (andmed)
Protsessi teksti või korpuse teisendamiseks märgideks või väiksemateks tükkideks teatud reeglite alusel nimetatakse tokeniseerimiseks. Parsimise vea parandamise õppimiseks on oluline analüüsida koodis olevaid sõna tokeniseerimiskäske. Sarnaselt regexile saab selle meetodiga luua oma reegleid ja see aitab teksti eeltöötlustoimingutes, nagu kõneosade kaardistamine. Selle meetodi abil teostatakse ka selliseid tegevusi nagu levinud sõnade otsimine ja sobitamine, teksti puhastamine ja andmete ettevalmistamine täiustatud tekstianalüütika tehnikate jaoks, nagu meeleoluanalüüs. Kui märgistus on vale, võib parsimise tekstis x ilmneda viga.
NLTK raamatukogu
Protsess kasutab populaarse keele tööriistakomplekti teeki NLTK, millel on rikkalik funktsioonide komplekt paljude NLP-tööde tegemiseks. Neid saab alla laadida Pip- või Pip-installipakettide kaudu. Teksti sõelumiseks võite kasutada Anaconda distributsiooni põhipaketti, mis sisaldab vaikimisi teeki.
Tokeniseerimise vormid
Selle meetodi levinumad vormid on sõna tokeniseerimine ja lause tokeniseerimine. Sõnataseme märgi tõttu trükib esimene sõna ühe sõna ainult üks kord, teine aga lause tasemel.
Teksti parsimise protsess
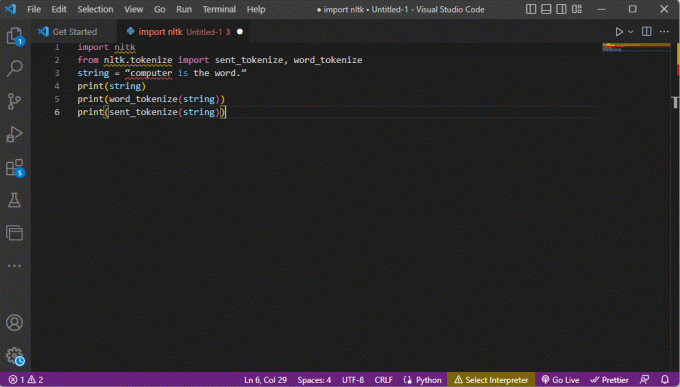
Siin on toodud ülaltoodud märgistamise samme selgitav kood.
import nltkalates nltk.tokenize import send_tokenize, word_tokenizestring = "arvuti on sõna."print (string)print (word_tokenize (string))print (saadetud_tokenize (string))
Loe ka:Javascripti parandamine: void (0) Viga
Sarnaselt DataFrame klassiga saab klassi DocParserit kasutada koodis oleva teksti sõelumiseks. Klass võimaldab kutsuda parsifunktsiooni failitee abil.
Teksti parsimise protsess
Et teada saada, kuidas DocParseri klassi abil teksti sõeluda, järgige alltoodud juhiseid.
Märge: Et teada saada, kuidas parsimisviga parandada, tuleb see funktsioon õigesti rakendada.
Teksti sõelumise tööriista kasutatakse muutujatest konkreetsete andmete eraldamiseks ja nende vastendamiseks muude muutujatega. See ei sõltu muudest ülesandes kasutatavatest tööriistadest ning muutujate tarbimiseks ja väljastamiseks kasutatakse BPA platvormi tööriista. Juurdepääsuks kasutage siin antud linki Parse Text Tool võrgus ja kasutage teksti sõelumise kohta varem antud vastuseid.

TextFieldParser kasutas objekte väga suurte struktureeritud ja piiritletud failide sõelumiseks ja töötlemiseks. Selle meetodi puhul saab kasutada teksti laiust ja veergu, nagu logifailid või pärandandmebaasi teave. Sõelumismeetod sarnaneb koodi itereerimisega tekstifailis ja seda kasutatakse peamiselt stringitöötlusmeetoditele sarnaste tekstiväljade eraldamiseks. Seda tehakse piiritletud stringide ja erineva laiusega väljade märgistamiseks, kasutades määratletud eraldajat, näiteks koma või tabeldusruumi.
Funktsioonid teksti sõelumiseks
Selle meetodi puhul saab teksti sõelumiseks kasutada järgmisi funktsioone.
MatchObjecti leidmise meetodid
Koodist või sõelutud tekstist MatchObjecti leidmiseks on kaks põhimeetodit.
Mõlemal juhul, kui väli ei ühti sõelumisel või teksti sõelumise otsimise ajal määratud vorminguga, ValformedLineException erand tagastatakse.
Viimase ja lihtsa meetodina teksti sõelumiseks võite kasutada MS Excel rakendus parserina, et luua tabeldustega ja komadega eraldatud faile. See aitaks analüüsida sõelutud tulemust ja leida, kuidas parsimisviga parandada.
1. Valige lähtefailis andmeväärtused ja vajutage nuppu Ctrl + C klahvid koos faili kopeerimiseks.
2. Ava Excel rakendus Windowsi otsinguriba abil.

3. Klõpsake nuppu A1 lahtrit ja vajutage nuppu Ctrl + V klahvid samaaegselt kopeeritud teksti kleepimiseks.
4. Valige A1 lahtrisse navigeerige Andmed vahekaarti ja klõpsake nuppu Tekst veergudesse valikus Andmetööriistad osa.
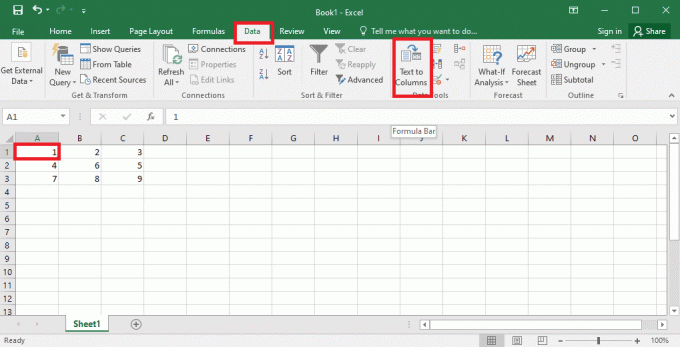
5A. Valige Piiritletud variant, kui a koma või sakk eraldajana kasutatakse tühikut ja klõpsake nuppu Edasi ja Lõpetama nupud.

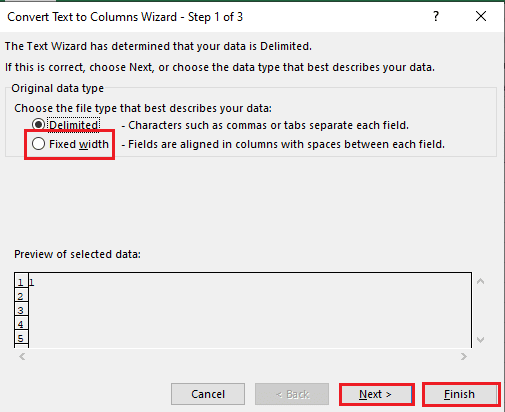
5B. Valige Fikseeritud laius suvand, määrake eraldajale väärtus ja klõpsake nuppu Edasi ja Lõpetama nupud.
Loe ka:Kuidas parandada Exceli teisaldamise veeru viga
Viga teksti x sõelumisel võib ilmneda Android-seadmetes: Sõelumisviga: paketi sõelumisel ilmnes probleem. See juhtub tavaliselt siis, kui rakendust ei õnnestu Google Play poest installida või kui käitate kolmanda osapoole rakendust.
Veatekst x võib ilmneda, kui märgivektorite loend on tsükliline ja muud funktsioonid moodustavad andmeväärtuste arvutamiseks lineaarse mudeli. Veateade on Error in parse (text = x, keep.source = FALSE):
Saate lugeda artiklit kuidas parandada parsimise viga Androidis õppida tundma vea põhjuseid ja meetodeid.
Lisaks juhendis toodud lahendustele võite proovida järgmisi parandusi.
Soovitatav:
Artikkel aitab õpetamisel kuidas teksti sõeluda ja õppida, kuidas parsimisviga parandada. Andke meile teada, milline meetod aitas parandada teksti x sõelumisviga ja millist sõelumismeetodit eelistatakse. Palun jagage oma ettepanekuid ja päringuid allolevas kommentaaride jaotises.

