0
विचारों

यदि आपने कुछ कंप्यूटर प्रोग्रामिंग लैंग्वेज सीखी हैं, तो आपने शब्द पार्सिंग टेक्स्ट सुना होगा। इसका उपयोग फ़ाइल के जटिल डेटा मानों को सरल बनाने के लिए किया जाता है। लेख आपको यह जानने में मदद करता है कि भाषा का उपयोग करके पाठ को कैसे पार्स किया जाए। इसके अतिरिक्त, यदि आपको पार्स टेक्स्ट x में त्रुटि का सामना करना पड़ा है, तो आप लेख में पार्स त्रुटि को ठीक करने का तरीका जानेंगे।
विषयसूची
इस लेख में, हमने विभिन्न तरीकों से टेक्स्ट को पार्स करने के लिए एक पूरी गाइड दिखाई है और साथ ही टेक्स्ट को पार्स करने का संक्षिप्त परिचय भी दिया है।
किसी भी कोड का उपयोग करके पाठ को पार्स करने की अवधारणाओं को सीखने से पहले। भाषा और कोडिंग की मूल बातें जानना महत्वपूर्ण है।
टेक्स्ट को पार्स करने के लिए, नेचुरल लैंग्वेज प्रोसेसिंग या एनएलपी, जो आर्टिफिशियल इंटेलिजेंस डोमेन का एक उप-क्षेत्र है, का उपयोग किया जाता है। पायथन भाषा, जो कि श्रेणी से संबंधित भाषाओं में से एक है, का उपयोग पाठ को पार्स करने के लिए किया जाता है।
एनएलपी कोड कंप्यूटर को विभिन्न अनुप्रयोगों के लिए उपयुक्त बनाने के लिए मानव भाषाओं को समझने और संसाधित करने में सक्षम बनाता है। एमएल या मशीन लर्निंग तकनीकों को भाषा में लागू करने के लिए, असंरचित पाठ डेटा को संरचित सारणीबद्ध डेटा में बदलना होगा। पार्सिंग गतिविधि को पूरा करने के लिए, प्रोग्राम कोड को बदलने के लिए पायथन भाषा का उपयोग किया जाता है।
पाठ को पार्स करने का अर्थ है डेटा को एक प्रारूप से दूसरे प्रारूप में परिवर्तित करना। जिस प्रारूप में फ़ाइल सहेजी गई है उसे पार्स किया जाएगा या एक अलग प्रारूप में फ़ाइल में परिवर्तित किया जाएगा ताकि उपयोगकर्ता इसे विभिन्न अनुप्रयोगों में उपयोग कर सके।
जिन कारणों से पाठ को पार्स किया जाना है, वे इस खंड में दिए गए हैं और यह जानने से पहले कि पाठ को कैसे पार्स किया जाए, यह एक पूर्व-आवश्यक ज्ञान है।
Python भाषा के DataFrame वर्ग में पाठ को पार्स करने के लिए सभी आवश्यक कार्य हैं। यह इन-बिल्ट लाइब्रेरी किसी भी प्रारूप के डेटा को दूसरे प्रारूप में पार्स करने के लिए आवश्यक कोड रखती है।
डेटाफ्रेम क्लास का संक्षिप्त परिचय
DataFrame क्लास एक सुविधा संपन्न डेटा संरचना है, जिसका उपयोग डेटा विश्लेषण उपकरण के रूप में किया जाता है। यह एक शक्तिशाली डेटा विश्लेषण उपकरण है जिसका उपयोग न्यूनतम प्रयास के साथ डेटा का विश्लेषण करने के लिए किया जा सकता है।
पार्स टेक्स्ट x में त्रुटि से बचने के लिए पायथन भाषा के पांडा SQL या डेटाबेस-शैली के संचालन को अत्यंत पूर्णता के साथ करने में मदद करते हैं। इसमें कुछ आईओ टूल्स भी शामिल हैं जो सीएसवी, एमएस एक्सेल, जेएसओएन, एचडीएफ5 और अन्य डेटा प्रारूपों की फाइलों का विश्लेषण करने में मदद करते हैं।
यह भी पढ़ें:प्रॉक्सी अनुरोध का प्रयास करते समय हुई त्रुटि को ठीक करें
डेटाफ़्रेम क्लास का उपयोग करके टेक्स्ट को पार्स करने की प्रक्रिया
टेक्स्ट को पार्स करने का तरीका जानने के लिए, आप इस सेक्शन में दी गई DataFrame क्लास का उपयोग करके मानक प्रक्रिया का उपयोग कर सकते हैं।
टिप्पणी: खाली DataFrame पर कोड लिखना थकाऊ और जटिल हो सकता है। पांडा इन डेटा प्रकारों से डेटाफ़्रेम वर्ग पर डेटा बनाने की अनुमति देते हैं। इसलिए, आदिम डेटा प्रकार के डेटा को आवश्यक डेटा प्रारूप में आसानी से पार्स किया जा सकता है।
विकल्प I: मानक प्रारूप
किसी निश्चित डेटा प्रारूप जैसे CSV के साथ किसी भी फ़ाइल को प्रारूपित करने की मानक विधि यहाँ समझाई गई है।
टिप्पणी: यहाँ, वेरिएबल का नाम दिया गया है आर ई करने के लिए प्रयोग किया जाता है पढ़ना फ़ाइल में डेटा का कार्य data.txt में आयातित पांडा का उपयोग करना पी.डी.. इनपुट टेक्स्ट का डेटा प्रारूप में निर्दिष्ट किया गया है सीएसवी प्रारूप।
ऊपर बताई गई प्रक्रिया के लिए एक उदाहरण कोड नीचे दिया गया है और यह समझने में मदद करेगा कि टेक्स्ट को कैसे पार्स किया जाए।
पीडी के रूप में पांडा आयात करेंरेस = pd.read_csv ('data.txt')आर ई
इस स्थिति में, यदि आप फ़ाइल में डेटा मान इनपुट करते हैं data.txt जैसे कि [1,2,3], इसे पार्स किया जाएगा और इस रूप में प्रदर्शित किया जाएगा 1 2 3.
विकल्प II: स्ट्रिंग विधि
यदि कोड को दिए गए पाठ में केवल तार या अल्फा वर्ण हैं, तो स्ट्रिंग में विशेष वर्ण जैसे अल्पविराम, स्थान आदि का उपयोग पाठ को अलग करने और पार्स करने के लिए किया जा सकता है। प्रक्रिया सामान्य आंतरिक स्ट्रिंग ऑपरेशंस के समान है। पार्स त्रुटि को ठीक करने का तरीका खोजने के लिए, आपको इस विकल्प का उपयोग करके पाठ को पार्स करने की प्रक्रिया का पालन करना होगा, जिसे नीचे समझाया गया है।
उदाहरण के लिए, नीचे दिए गए कोड में, स्ट्रिंग में विशेष वर्ण my_string, जो हैं, ',' और ':' पहचाने जाते हैं। पार्स टेक्स्ट x में त्रुटि से बचने के लिए इस प्रक्रिया को सावधानी से करना होगा।
उदाहरण के लिए, स्प्लिट कमांड का उपयोग करके पहचाने गए विशेष वर्णों के आधार पर स्ट्रिंग को टेक्स्ट डेटा मानों में विभाजित किया जाता है।
ऊपर बताई गई प्रक्रिया के लिए नमूना कोड नीचे दिया गया है।
my_string = 'नाम: तकनीक, कंप्यूटर's final = [name.strip() my_string.split(':')[1].split(',')] में नाम के लिएप्रिंट ("नाम: {}"। प्रारूप (फाइनल))
इस स्थिति में, पार्स की गई स्ट्रिंग का परिणाम नीचे दिखाए अनुसार प्रदर्शित किया जाएगा।
नाम: ['टेक', 'कंप्यूटर']
बेहतर स्पष्टता पाने के लिए और यह जानने के लिए कि स्ट्रिंग टेक्स्ट का उपयोग करते हुए टेक्स्ट को कैसे पार्स करना है, a के लिए लूप का उपयोग किया जाता है और कोड को निम्नानुसार संशोधित किया जाता है।
my_string = 'नाम: तकनीक, कंप्यूटर's1 = my_string.split (':')एस2 = एस1 [1]s3 = s2.split (',')s4 = [name.strip () s3 में नाम के लिए]आईडीएक्स के लिए, गणना में आइटम ([एस 1, एस 2, एस 3, एस 4]):प्रिंट ("चरण {}: {}"। प्रारूप (आईडीएक्स, आइटम))
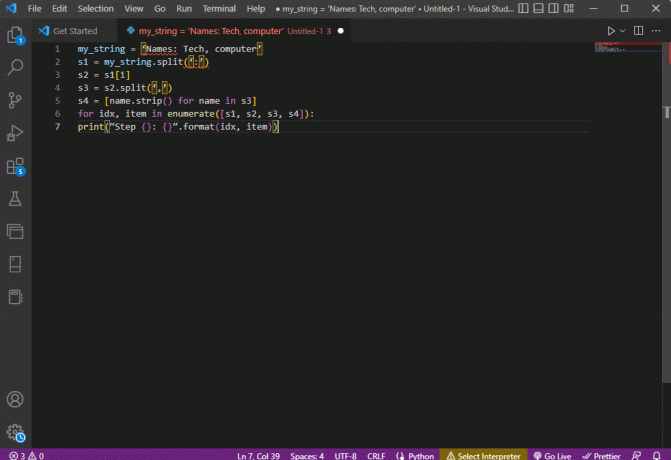
इनमें से प्रत्येक चरण के लिए पार्स किए गए पाठ का परिणाम नीचे दिए गए अनुसार प्रदर्शित किया गया है। आप नोट कर सकते हैं कि, चरण 0 में, विशेष वर्ण के आधार पर स्ट्रिंग को अलग किया जाता है : और आगे के चरणों में वर्ण के आधार पर पाठ डेटा मानों को अलग किया जाता है।
चरण 0: ['नाम', 'टेक, कंप्यूटर']चरण 1: टेक, कंप्यूटरचरण 2: ['टेक', 'कंप्यूटर']चरण 3: ['टेक', 'कंप्यूटर']
विकल्प III: कॉम्प्लेक्स फाइल को पार्स करना
ज्यादातर उदाहरणों में, जिस फ़ाइल डेटा को पार्स करने की आवश्यकता होती है, उसमें अलग-अलग डेटा प्रकार और डेटा मान होते हैं। इस मामले में, पहले बताई गई विधियों का उपयोग करके फ़ाइल को पार्स करना कठिन हो सकता है।
फ़ाइल में जटिल डेटा को पार्स करने की विशेषताएं डेटा मानों को सारणीबद्ध प्रारूप में प्रदर्शित करने के लिए हैं।
इस पद्धति में पाठ को पार्स करने का तरीका सीखने से पहले, कुछ बुनियादी अवधारणाओं को सीखना आवश्यक है। डेटा मानों की पार्सिंग रेगुलर एक्सप्रेशन या रेगेक्स के आधार पर की जाती है।
रेगेक्स पैटर्न
पार्स त्रुटि को ठीक करने का तरीका जानने के लिए, आपको यह सुनिश्चित करना होगा कि एक्सप्रेशन में रेगेक्स पैटर्न उचित हैं। स्ट्रिंग्स के डेटा मानों को पार्स करने के लिए कोड में इस खंड में नीचे सूचीबद्ध सामान्य रेगेक्स पैटर्न शामिल होंगे।
नियमित अभिव्यक्ति
पायथन भाषा में रेगुलर एक्सप्रेशन मॉड्यूल पांडा पैकेज का एक प्रमुख हिस्सा हैं और गलत री से पार्स टेक्स्ट x में त्रुटि हो सकती है। अभिव्यक्ति में स्ट्रिंग पैटर्न खोजने के लिए यह पायथन के अंदर एम्बेडेड एक छोटी भाषा है। रेगुलर एक्सप्रेशंस या रेगेक्स विशेष सिंटैक्स के साथ तार हैं। यह उपयोगकर्ता को स्ट्रिंग्स में मानों के आधार पर अन्य स्ट्रिंग्स में पैटर्न का मिलान करने की अनुमति देता है।
रेगेक्स डेटा प्रकार और स्ट्रिंग में अभिव्यक्ति की आवश्यकता के आधार पर बनाया गया है, जैसे स्ट्रिंग = (.*)\n. प्रत्येक अभिव्यक्ति में पैटर्न से पहले रेगेक्स का उपयोग किया जाता है। रेगुलर एक्सप्रेशन में उपयोग किए गए प्रतीकों को नीचे सूचीबद्ध किया गया है और यह जानने में मदद मिलेगी कि टेक्स्ट को कैसे पार्स करना है।
रेगेक्सऑब्जेक्ट्स
RegexObject कंपाइल फ़ंक्शन के लिए रिटर्न वैल्यू है और अगर एक्सप्रेशन मैच वैल्यू से मेल खाता है तो इसका इस्तेमाल मैचऑब्जेक्ट को वापस करने के लिए किया जाता है।
1. मैचऑब्जेक्ट
चूंकि MatchObject का बूलियन मान हमेशा True होता है, आप a का उपयोग कर सकते हैं अगर कथन वस्तु में सकारात्मक मिलान की पहचान करने के लिए। उपयोग करने के मामले में अगर बयान, सूचकांक द्वारा निर्दिष्ट समूह का उपयोग अभिव्यक्ति में वस्तु के मिलान का पता लगाने के लिए किया जाता है।
2. मैचऑब्जेक्ट के तरीके
पाठ को पार्स करने का तरीका ढूंढते समय, यह जानना महत्वपूर्ण है कि नीचे सूचीबद्ध अनुसार MatchObject के दो बुनियादी तरीके हैं। यदि निर्दिष्ट अभिव्यक्ति में MatchObject पाया जाता है, तो यह अपना उदाहरण लौटाएगा, अन्यथा, यह कोई नहीं लौटाएगा।
नियमित अभिव्यक्ति कार्य
रेगेक्स फ़ंक्शंस कोड लाइनें हैं जिनका उपयोग उपयोगकर्ता द्वारा प्राप्त किए गए डेटा मानों के सेट से निर्दिष्ट एक निश्चित फ़ंक्शन को करने के लिए किया जाता है।
टिप्पणी: कार्यों को लिखने के लिए, पार्स पाठ x में त्रुटि से बचने के लिए नियमित अभिव्यक्ति के लिए कच्चे तार का उपयोग किया जाता है। यह सबस्क्रिप्ट जोड़कर किया जाता है आर अभिव्यक्ति में प्रत्येक पैटर्न से पहले।
भावों में प्रयुक्त सामान्य कार्यों को नीचे समझाया गया है।
1. re.findall ()
यह फ़ंक्शन स्ट्रिंग में सभी पैटर्न लौटाता है यदि कोई मैच मिलता है और कोई मैच नहीं मिलने पर एक खाली सूची देता है। उदाहरण के लिए, समारोह, string = re.findall('[aeiou]', regex_filename) फ़ाइल नाम में स्वर घटना को खोजने के लिए प्रयोग किया जाता है।
2. पुनः विभाजन ()
इस फ़ंक्शन का उपयोग स्ट्रिंग को विभाजित करने के लिए किया जाता है, जब एक निर्दिष्ट वर्ण के साथ मेल खाता है जैसे कि स्थान पाया जाता है। कोई मिलान नहीं मिलने की स्थिति में, यह एक खाली स्ट्रिंग लौटाता है।
3. पुनः उप ()
फ़ंक्शन मिलान किए गए टेक्स्ट को बदले गए चर की सामग्री के साथ प्रतिस्थापित करता है। अन्य कार्यों के विपरीत, यदि कोई पैटर्न नहीं मिलता है, तो मूल स्ट्रिंग वापस आ जाती है।
4. शोध करना()
टेक्स्ट को पार्स करने का तरीका सीखने में मदद करने वाले बुनियादी कार्यों में से एक सर्च फंक्शन है। यह स्ट्रिंग में पैटर्न को खोजने और मैच ऑब्जेक्ट को वापस करने में मदद करता है। यदि खोज मिलान की पहचान करने में विफल रहती है, तो कोई मान नहीं लौटाया जाता है।
5. पुन: संकलन (पैटर्न)
इस फ़ंक्शन का उपयोग रेगेक्सऑब्जेक्ट में रेगुलर एक्सप्रेशन पैटर्न को संकलित करने के लिए किया जाता है, जिसकी चर्चा पहले की गई थी।
अन्य आवश्यकताएं
सूचीबद्ध आवश्यकताएँ डेटा विश्लेषण में उन्नत प्रोग्रामर द्वारा उपयोग की जाने वाली एक अतिरिक्त विशेषता है।
यह भी पढ़ें:विंडोज 10 पर NumPy कैसे इनस्टॉल करें
पाठ को पार्स करने की प्रक्रिया
इस जटिल विकल्प में टेक्स्ट को पार्स करने की विधि नीचे दी गई है।
आदेश डेटा = पीडी। डेटाफ़्रेम (डेटा) तानाशाही मूल्यों से एक पांडा डेटाफ़्रेम बनाने के लिए उपयोग किया जाता है। वैकल्पिक रूप से, आप नीचे बताए अनुसार संबंधित उद्देश्य के लिए निम्न आदेशों का उपयोग कर सकते हैं।
पाठ को पार्स करने का तरीका जानने के लिए अंतिम चरण का उपयोग करके पार्सर का परीक्षण करना है अगर बयान एक चर को मान निर्दिष्ट करके आंकड़े और इसका उपयोग करके इसे प्रिंट करना प्रिंट (डेटा) आज्ञा।
उपरोक्त स्पष्टीकरण के लिए उदाहरण कोड यहाँ दिया गया है।
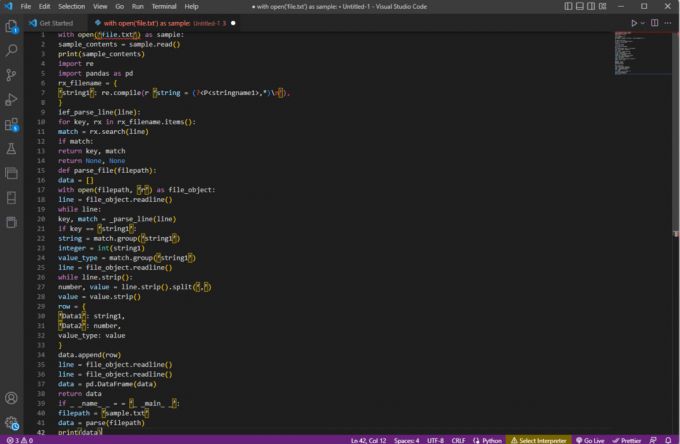
नमूने के रूप में open('file.txt') के साथ:नमूना_ सामग्री = नमूना पढ़ें ()प्रिंट (नमूना_सामग्री)आयात पुनःपीडी के रूप में पांडा आयात करेंआरएक्स_फाइलनाम = {'स्ट्रिंग 1': re.compile (आर 'स्ट्रिंग = (?,*)\एन'),
}ief_parse_line (लाइन):कुंजी के लिए, rx_filename.items में rx ():मैच = आरएक्स.सर्च (लाइन)अगर मैच:वापसी कुंजी, मैचवापसी कोई नहीं, कोई नहींdef parse_file (फ़ाइलपथ):डेटा = []खुले (फ़ाइलपथ, 'आर') के साथ file_object के रूप में:लाइन = file_object.readline ()जबकि लाइन:कुंजी, मैच = _parse_line (लाइन)अगर कुंजी == 'स्ट्रिंग 1':स्ट्रिंग = मैच.ग्रुप ('स्ट्रिंग 1')पूर्णांक = int (string1)value_type = match.group('string1')लाइन = file_object.readline ()जबकि लाइन.स्ट्रिप ():संख्या, मान = लाइन.स्ट्रिप ()। विभाजन (',')मान = मान.पट्टी ()पंक्ति = {'डेटा 1': स्ट्रिंग 1,'डेटा2': संख्या,value_type: मान}डेटा.एपेंड (पंक्ति)लाइन = file_object.readline ()लाइन = file_object.readline ()डेटा = पीडी। डेटाफ़्रेम (डेटा)वापसी डेटाअगर _ _नाम_ _ = = '_ _मुख्य_ _':फ़ाइलपथ = 'नमूना.txt'डेटा = पार्स (फ़ाइलपथ)प्रिंट (डेटा)
कुछ नियमों के आधार पर किसी टेक्स्ट या कॉर्पस को टोकन या छोटे टुकड़ों में बदलने की प्रक्रिया को टोकनाइजेशन कहा जाता है। पार्स त्रुटि को ठीक करने का तरीका जानने के लिए, कोड में शब्द टोकननाइजेशन कमांड का विश्लेषण करना महत्वपूर्ण है। रेगेक्स के समान, इस पद्धति में स्वयं के नियम बनाए जा सकते हैं और यह पाठ के पूर्व-प्रसंस्करण कार्यों जैसे भाषण के भागों की मैपिंग में मदद करता है। साथ ही, सामान्य शब्दों को खोजने और मिलान करने, पाठ की सफाई करने और भावना विश्लेषण जैसी उन्नत पाठ विश्लेषण तकनीकों के लिए डेटा तैयार करने जैसी गतिविधियाँ इस पद्धति में की जाती हैं। यदि टोकननाइज़ेशन अनुचित है, तो पार्स टेक्स्ट x में त्रुटि हो सकती है।
एनएलटीके लाइब्रेरी
यह प्रक्रिया एनएलटीके नामक लोकप्रिय भाषा टूलकिट लाइब्रेरी की मदद लेती है, जिसमें कई एनएलपी कार्यों को करने के लिए कार्यों का एक समृद्ध सेट है। इन्हें पिप या पिप इंस्टाल पैकेज के माध्यम से डाउनलोड किया जा सकता है। टेक्स्ट को पार्स करने के बारे में जानने के लिए, आप एनाकोंडा डिस्ट्रीब्यूशन के बेस पैक का उपयोग कर सकते हैं जिसमें डिफ़ॉल्ट रूप से लाइब्रेरी शामिल है।
टोकनकरण के रूप
इस पद्धति के सामान्य रूप शब्द टोकननाइजेशन और वाक्य टोकननाइजेशन हैं। शब्द-स्तरीय टोकन के कारण, पूर्व एक शब्द को केवल एक बार प्रिंट करता है, जबकि बाद वाला शब्द को वाक्य स्तर पर प्रिंट करता है।
पाठ को पार्स करने की प्रक्रिया
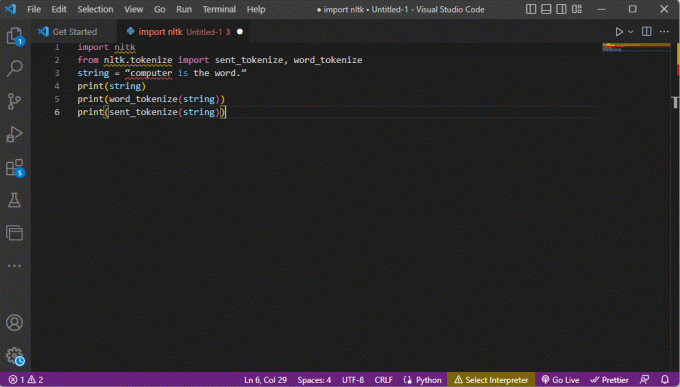
ऊपर टोकनाइजेशन के चरणों की व्याख्या करने वाला कोड यहां दिया गया है।
आयात एनएलटीकेnltk.tokenize से आयात भेजा_tokenize, word_tokenizeस्ट्रिंग = "कंप्यूटर शब्द है।"प्रिंट (स्ट्रिंग)प्रिंट (word_tokenize (स्ट्रिंग))प्रिंट (sent_tokenize (स्ट्रिंग))
यह भी पढ़ें:जावास्क्रिप्ट को कैसे ठीक करें: शून्य (0) त्रुटि
DataFrame क्लास के समान, क्लास DocParser का उपयोग कोड में टेक्स्ट को पार्स करने के लिए किया जा सकता है। वर्ग आपको पार्स फ़ंक्शन को फ़ाइलपथ के साथ कॉल करने की अनुमति देता है।
पाठ को पार्स करने की प्रक्रिया
DocParser क्लास का उपयोग करके टेक्स्ट को पार्स करने का तरीका जानने के लिए, नीचे दिए गए निर्देशों का पालन करें।
टिप्पणी: पार्स त्रुटि को ठीक करने का तरीका जानने के लिए, इस फ़ंक्शन को सही ढंग से कार्यान्वित किया जाना चाहिए।
पार्स टेक्स्ट टूल का उपयोग वेरिएबल्स से विशिष्ट डेटा निकालने और उन्हें अन्य वेरिएबल्स में मैप करने के लिए किया जाता है। यह किसी कार्य में उपयोग किए जाने वाले किसी भी अन्य उपकरण से स्वतंत्र है और BPA प्लेटफ़ॉर्म टूल का उपयोग उपभोग और आउटपुट चर के लिए किया जाता है। तक पहुंचने के लिए यहां दिए गए लिंक का उपयोग करें टेक्स्ट टूल को ऑनलाइन पार्स करें और टेक्स्ट को पार्स करने के तरीके के बारे में पहले दिए गए उत्तरों का उपयोग करें।

TextFieldParser ने संरचित और सीमांकित बहुत बड़ी फ़ाइलों को पार्स और संसाधित करने के लिए ऑब्जेक्ट्स का उपयोग किया। इस पद्धति में पाठ की चौड़ाई और स्तंभ जैसे लॉग फाइल या लीगेसी डेटाबेस जानकारी का उपयोग किया जा सकता है। पार्सिंग विधि टेक्स्ट फ़ाइल पर कोड को पुनरावृत्त करने के समान है और मुख्य रूप से स्ट्रिंग मैनिपुलेशन विधियों के समान टेक्स्ट के फ़ील्ड निकालने के लिए उपयोग की जाती है। यह अल्पविराम या टैब स्थान जैसे परिभाषित सीमांकक का उपयोग करके सीमांकित तार और विभिन्न चौड़ाई के क्षेत्रों को चिह्नित करने के लिए किया जाता है।
पाठ को पार्स करने के कार्य
इस पद्धति में पाठ को पार्स करने के लिए निम्नलिखित कार्यों का उपयोग किया जा सकता है।
मैचऑब्जेक्ट खोजने के तरीके
कोड या पार्स किए गए टेक्स्ट में MatchObject को खोजने के दो बुनियादी तरीके हैं.
किसी भी स्थिति में, यदि पार्सिंग करते समय या पाठ को पार्स करने का तरीका खोजने के दौरान कोई फ़ील्ड निर्दिष्ट प्रारूप से मेल नहीं खाता है, तो ए विकृत लाइन अपवाद अपवाद वापस कर दिया गया है।
पाठ को पार्स करने के लिए अंतिम और सरल विधि के रूप में, आप इसका उपयोग कर सकते हैं एमएस एक्सेल app टैब-सीमांकित और अल्पविराम-सीमांकित फ़ाइलें बनाने के लिए एक पार्सर के रूप में। यह आपके पार्स किए गए परिणाम के साथ क्रॉस-चेकिंग में मदद करेगा और पार्स त्रुटि को ठीक करने का तरीका खोजने में मदद करेगा।
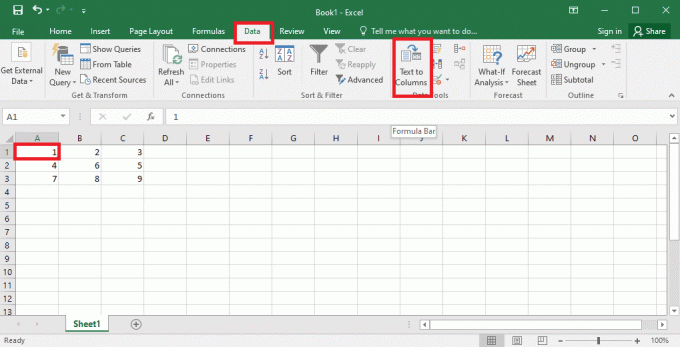
1. स्रोत फ़ाइल में डेटा मानों का चयन करें और दबाएं Ctrl + C कुंजियाँ फाइल को कॉपी करने के लिए एक साथ।
2. खोलें एक्सेल ऐप विंडोज सर्च बार का उपयोग कर रहा है।

3. पर क्लिक करें ए 1 सेल और दबाएं Ctrl + V कुंजियाँ एक साथ कॉपी किए गए टेक्स्ट को पेस्ट करने के लिए।
4. का चयन करें ए 1 सेल, पर नेविगेट करें आंकड़े टैब, और पर क्लिक करें स्तंभों के लिए पाठ विकल्प में डेटा उपकरण अनुभाग।
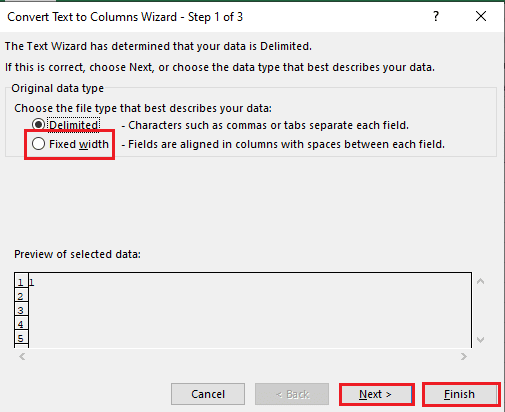
5ए. का चयन करें सीमांकित विकल्प अगर ए अल्पविराम या टैब अंतरिक्ष विभाजक के रूप में प्रयोग किया जाता है, और पर क्लिक करें अगला और खत्म करना बटन।

5बी। का चयन करें निश्चित चौड़ाई विकल्प, विभाजक के लिए एक मान निर्दिष्ट करें, और पर क्लिक करें अगला और खत्म करना बटन।
यह भी पढ़ें:मूव एक्सेल कॉलम एरर को कैसे ठीक करें
एंड्रॉइड डिवाइस पर पार्स टेक्स्ट एक्स में त्रुटि हो सकती है, पार्स त्रुटि: पैकेज को पार्स करने में समस्या थी। यह आमतौर पर तब होता है जब ऐप Google Play Store से इंस्टॉल करने में विफल रहता है या तृतीय-पक्ष ऐप चलाते समय।
त्रुटि पाठ x हो सकता है यदि वर्ण सदिशों की सूची लूप की गई है और अन्य फ़ंक्शन डेटा मानों की गणना के लिए एक रेखीय मॉडल बनाते हैं। त्रुटि संदेश पार्स में त्रुटि है (पाठ = x, रखें। स्रोत = गलत):
आप पर लेख पढ़ सकते हैं Android पर पार्स त्रुटि को कैसे ठीक करें त्रुटि को ठीक करने के कारणों और तरीकों को जानने के लिए।
मार्गदर्शिका में दिए गए समाधानों के अलावा, आप निम्न सुधारों को आज़मा सकते हैं।
अनुशंसित:
लेख शिक्षण में सहायक होता है पाठ का विश्लेषण कैसे करें और पार्स त्रुटि को ठीक करने का तरीका जानने के लिए। आइए जानते हैं कि किस विधि ने टेक्स्ट एक्स को पार्स करने में त्रुटि को ठीक करने में मदद की और पार्सिंग की कौन सी विधि को प्राथमिकता दी गई। कृपया अपने सुझाव और प्रश्न नीचे टिप्पणी अनुभाग में साझा करें।