
0
Pogledi

Ako ste naučili nekoliko računalnih programskih jezika, možda ste čuli izraz raščlanjivanje teksta. Ovo se koristi za pojednostavljenje složenih podatkovnih vrijednosti datoteke. Članak vam pomaže da saznate kako raščlaniti tekst pomoću jezika. Osim toga, ako ste se suočili s pogreškom u raščlanjivanju teksta x, znat ćete kako popraviti pogrešku raščlanjivanja u članku.
Sadržaj
U ovom smo članku prikazali potpuni vodič za raščlanjivanje teksta na različite načine i ukratko dali uvod u raščlanjivanje teksta.
Prije nego što se udubite u učenje pojmova raščlanjivanja teksta pomoću bilo kojeg koda. Važno je znati o osnovama jezika i kodiranja.
Za raščlanjivanje teksta koristi se obrada prirodnog jezika ili NLP, koja je podpolje domene umjetne inteligencije. Python jezik, koji je jedan od jezika koji pripadaju kategoriji koristi se za analizu teksta.
NLP kodovi omogućuju računalima razumijevanje i obradu ljudskih jezika kako bi bili prikladni za različite primjene. Da biste primijenili ML ili tehnike strojnog učenja na jezik, nestrukturirani tekstualni podaci moraju se pretvoriti u strukturirane tablične podatke. Za dovršetak aktivnosti parsiranja koristi se jezik Python za promjenu programskih kodova.
Raščlanjivanje teksta jednostavno znači pretvaranje podataka iz jednog formata u drugi format. Format u kojem je datoteka spremljena analizirat će se ili pretvoriti u datoteku u drugom formatu kako bi se korisniku omogućilo korištenje u različitim aplikacijama.
Razlozi zbog kojih se tekst mora raščlaniti navedeni su u ovom odjeljku i to je preduvjetno znanje prije nego što saznate kako raščlaniti tekst.
Klasa DataFrame jezika Python ima sve potrebne funkcije za raščlanjivanje teksta. Ova ugrađena biblioteka sadrži potrebne kodove za raščlanjivanje podataka bilo kojeg formata u drugi format.
Kratak uvod u DataFrame klasu
DataFrame Class je podatkovna struktura bogata značajkama koja se koristi kao alat za analizu podataka. Ovo je moćan alat za analizu podataka koji se može koristiti za analizu podataka uz minimalan napor.
Pande jezika Python pomažu u izvođenju SQL operacija ili operacija u stilu baze podataka s najvećim savršenstvom kako bi se izbjegla pogreška u analizi teksta x. Također sadrži neke IO alate koji pomažu u analizi datoteka CSV, MS Excel, JSON, HDF5 i drugih formata podataka.
Također pročitajte:Ispravite pogrešku koja se dogodila pri pokušaju proxy zahtjeva
Proces raščlanjivanja teksta pomoću DataFrame klase
Da biste znali kako raščlaniti tekst, možete upotrijebiti standardni postupak pomoću klase DataFrame dane u ovom odjeljku.
Bilješka: Pisanje koda na prazan DataFrame može biti zamorno i složeno. Pande omogućuju stvaranje podataka u klasi DataFrame iz ovih tipova podataka. Stoga se podaci u primitivnom tipu podataka mogu lako raščlaniti na traženi format podataka.
Opcija I: Standardni format
Ovdje je objašnjena standardna metoda za formatiranje bilo koje datoteke s određenim formatom podataka kao što je CSV.
Bilješka: Ovdje je varijabla pod nazivom res koristi se za izvođenje čitati funkciju podataka u datoteci podaci.txt koristeći pande uvezene u pd. Format podataka ulaznog teksta naveden je u CSV format.
Primjer koda za gore objašnjeni proces dan je u nastavku i pomoći će vam u razumijevanju kako analizirati tekst.
uvezi pande kao pdres = pd.read_csv('data.txt')res
U ovom slučaju, ako unesete vrijednosti podataka u datoteku podaci.txt kao npr [1,2,3], analizirat će se i prikazati kao 1 2 3.
Opcija II: Metoda niza
Ako tekst dan kodu sadrži samo nizove ili alfa znakove, posebni znakovi u nizu poput zareza, razmaka itd. mogu se koristiti za odvajanje i raščlanjivanje teksta. Proces je sličan uobičajenim unutarnjim operacijama niza. Da biste saznali kako popraviti pogrešku analize, morate slijediti postupak analize teksta pomoću ove opcije objašnjen u nastavku.
Na primjer, u donjem kodu, posebni znakovi u nizu moj_string, koji su, ',' i ':’ su identificirani. Ovaj postupak treba obaviti pažljivo kako bi se izbjegla pogreška u analizi teksta x.
Na primjer, niz se dijeli na vrijednosti tekstualnih podataka na temelju posebnih znakova identificiranih pomoću naredbe split.
Uzorak koda za gore objašnjeni proces dan je u nastavku.
my_string = 'Imena: tehnika, računalo'sfinal = [name.strip() za ime u my_string.split(':')[1].split(',')]print(“Imena: {}”.format (sfinal))
U tom bi slučaju rezultat raščlanjenog niza bio prikazan kao što je prikazano u nastavku.
Imena: ['tehnika', 'računalo']
Da biste dobili bolju jasnoću i znali kako raščlaniti tekst dok koristite tekst niza, a za koristi se petlja i kod se modificira na sljedeći način.
my_string = 'Imena: tehnika, računalo's1 = moj_string.split(':')s2 = s1[1]s3 = s2.split(‘,’)s4 = [name.strip() za ime u s3]za idx, stavka u enumerate([s1, s2, s3, s4]):print(“Korak {}: {}”.format (idx, stavka))
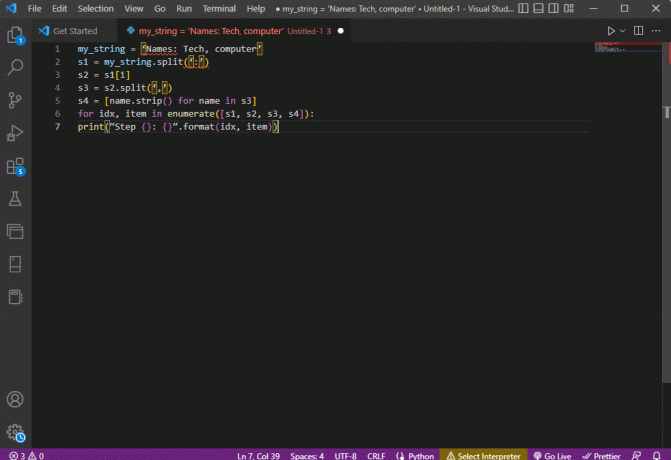
Rezultat raščlanjenog teksta za svaki od ovih koraka prikazan je kao što je navedeno u nastavku. Možete primijetiti da se u koraku 0 niz odvaja na temelju posebnog znaka : a vrijednosti tekstualnih podataka odvajaju se na temelju znaka u daljnjim koracima.
Korak 0: ['Imena', 'Tehnika, računalo']Korak 1: Tehnika, računalo2. korak: ['tehnika', 'računalo']Korak 3: ['Tehnika', 'računalo']
Opcija III: Raščlanjivanje složene datoteke
U većini slučajeva podaci datoteke koje je potrebno raščlaniti sadrže različite vrste podataka i vrijednosti podataka. U tom slučaju može biti teško analizirati datoteku pomoću ranije objašnjenih metoda.
Značajke analiziranja složenih podataka u datoteci su da se vrijednosti podataka prikazuju u tabelarnom formatu.
Prije nego što se upustite u učenje kako analizirati tekst ovom metodom, potrebno je naučiti nekoliko osnovnih pojmova. Raščlanjivanje vrijednosti podataka vrši se na temelju regularnih izraza ili regularnih izraza.
Regex obrasci
Da biste znali kako popraviti pogrešku analize, morate osigurati da su uzorci regularnih izraza u izrazima ispravni. Kod za raščlanjivanje podatkovnih vrijednosti nizova uključivao bi uobičajene uzorke regularnih izraza navedene u nastavku u ovom odjeljku.
Regularni izrazi
Moduli regularnog izraza glavni su dio paketa pandas u jeziku Python i pogrešan re može dovesti do pogreške u analizi teksta x. To je maleni jezik ugrađen u Python za pronalaženje uzorka niza u izrazu. Regularni izrazi ili Regex su nizovi s posebnom sintaksom. Omogućuje korisniku podudaranje uzoraka u drugim nizovima na temelju vrijednosti u nizovima.
Regex se stvara na temelju tipa podataka i zahtjeva izraza u nizu, kao što je Niz = (.*)\n. Regularni izraz se koristi prije uzorka u svakom izrazu. Simboli korišteni u regularnim izrazima navedeni su u nastavku i pomoći će vam da saznate kako raščlaniti tekst.
RegexObjects
RegexObject povratna je vrijednost za funkciju kompajliranja i koristi se za vraćanje MatchObject ako izraz odgovara vrijednosti podudaranja.
1. MatchObject
Kako je Booleova vrijednost MatchObject-a uvijek True, možete koristiti ako izjava za identifikaciju pozitivnih podudaranja u objektu. U slučaju korištenja ako izjava, grupa na koju upućuje indeks koristi se za pronalaženje podudaranja objekta u izrazu.
2. Metode MatchObject
Dok pronalazite kako raščlaniti tekst, važno je znati da MatchObject ima dvije osnovne metode navedene u nastavku. Ako se MatchObject pronađe u navedenom izrazu, vratio bi svoju instancu, inače bi vratio Ništa.
Funkcije regularnog izraza
Regex funkcije su linije koda koje se koriste za izvođenje određene funkcije koju je odredio korisnik iz skupa nabavljenih vrijednosti podataka.
Bilješka: Za pisanje funkcija koriste se neobrađeni nizovi za regularne izraze kako bi se izbjegla pogreška u analizi teksta x. To se postiže dodavanjem indeksa r prije svakog uzorka u izrazu.
Uobičajene funkcije koje se koriste u izrazima objašnjene su u nastavku.
1. re.findall()
Ova funkcija vraća sve uzorke u nizu ako se pronađe podudaranje i vraća prazan popis ako nije pronađeno podudaranje. Na primjer, funkcija, niz = re.findall('[aeiou]', regex_filename) koristi se za pronalaženje samoglasnika u nazivu datoteke.
2. re.split()
Ova se funkcija koristi za dijeljenje niza u slučaju da se pronađe podudaranje s navedenim znakom kao što je razmak. U slučaju da nije pronađeno podudaranje, vraća prazan niz.
3. re.sub()
Funkcija zamjenjuje odgovarajući tekst sa sadržajem dane varijable zamjene. Suprotno drugim funkcijama, ako se ne pronađe uzorak, vraća se izvorni niz.
4. istraživanje()
Jedna od osnovnih funkcija koja pomaže u učenju raščlanjivanja teksta je funkcija pretraživanja. Pomaže u traženju uzorka u nizu i vraćanju objekta podudaranja. Ako pretraživanje ne uspije identificirati podudaranje, vrijednost se ne vraća.
5. re.compile (uzorak)
Ova se funkcija koristi za prevođenje uzoraka regularnih izraza u RegexObject, o čemu je ranije bilo riječi.
Ostali zahtjevi
Navedeni zahtjevi su dodatna značajka koju koriste napredni programeri u analizi podataka.
Također pročitajte:Kako instalirati NumPy na Windows 10
Proces raščlanjivanja teksta
Metoda za analizu teksta u ovoj složenoj opciji opisana je u nastavku.
Zapovijed podaci = pd. DataFrame (podaci) koristi se za stvaranje pandas DataFramea iz dict vrijednosti. Alternativno, možete koristiti sljedeće naredbe za odgovarajuće svrhe kao što je navedeno u nastavku.
Posljednji korak da biste saznali kako analizirati tekst jest testirati parser pomoću izjava if dodjeljivanjem vrijednosti varijabli podaci i ispisati ga pomoću ispis (podataka) naredba.
Primjer koda za gornje objašnjenje dan je ovdje.
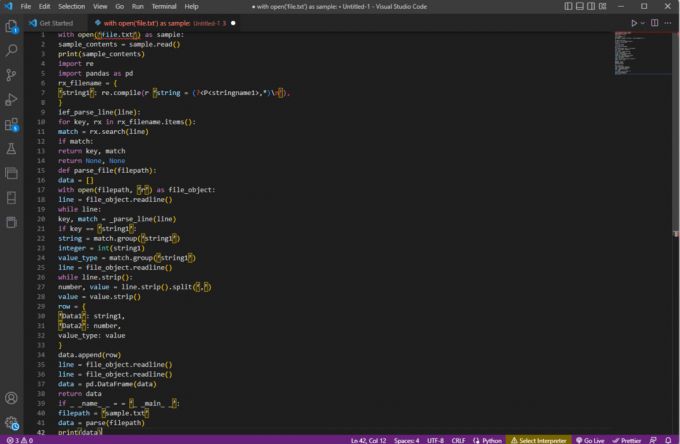
s open('file.txt') kao uzorkom:sample_contents = sample.read()ispis (uzorak_sadržaja)uvoz reuvezi pande kao pdrx_ime_datoteke = {'string1': re.compile (r 'string = (?,*)\n’),
}ief_parse_line (linija):za ključ, rx u rx_filename.items():match = rx.search (linija)ako odgovara:povratni ključ, utakmicavrati None, Nonedef parse_file (putanja datoteke):podaci = []s otvorenim (putanja datoteke, 'r') kao file_object:linija = file_object.readline()redak dok:ključ, podudaranje = _parse_line (linija)if key == 'niz1':niz = match.group('string1')cijeli broj = int (string1)value_type = match.group('string1')linija = file_object.readline()dok linija.strip():broj, vrijednost = line.strip().split(‘,’)vrijednost = vrijednost.strip()red = {'Podaci1': niz1,'Podatak2': broj,vrsta_vrijednosti: vrijednost}data.append (redak)linija = file_object.readline()linija = file_object.readline()podaci = pd. DataFrame (podaci)vratiti podatkeako _ _ime_ _ = = '_ _glavni_ _':put datoteke = 'uzorak.txt'podaci = raščlaniti (putanja datoteke)ispis (podataka)
Proces pretvaranja teksta ili korpusa u tokene ili manje dijelove na temelju određenih pravila naziva se tokenizacija. Da biste naučili kako popraviti pogrešku analize, važno je analizirati naredbe tokenizacije riječi u kodu. Slično regularnom izrazu, ovom se metodom mogu stvoriti vlastita pravila i pomaže u zadacima pretprocesiranja teksta kao što je mapiranje dijelova govora. Također, aktivnosti poput pronalaženja i spajanja zajedničkih riječi, čišćenja teksta i pripreme podataka za napredne tehnike analize teksta kao što je analiza raspoloženja izvode se ovom metodom. Ako tokenizacija nije ispravna, može doći do pogreške u analizi teksta x.
NLTK knjižnica
Proces uzima pomoć knjižnice popularnog jezičnog alata pod nazivom NLTK, koja ima bogat skup funkcija za obavljanje mnogih NLP poslova. Oni se mogu preuzeti putem paketa Pip ili Pip Installs. Da biste znali kako raščlaniti tekst, možete koristiti osnovni paket distribucije Anaconda koji uključuje biblioteku prema zadanim postavkama.
Oblici tokenizacije
Uobičajeni oblici ove metode su tokenizacija riječi i tokenizacija rečenice. Zahvaljujući tokenu razine riječi, prvi ispisuje jednu riječ samo jednom, dok drugi ispisuje riječ na razini rečenice.
Proces raščlanjivanja teksta
Kod koji objašnjava gornje korake za tokenizaciju dan je ovdje.
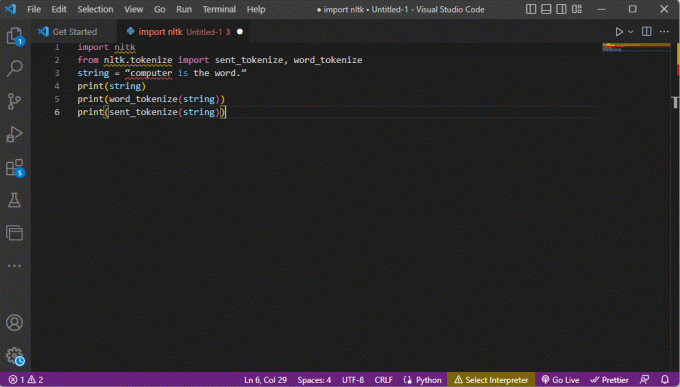
uvoz nltkiz nltk.tokenize import sent_tokenize, word_tokenizestring = "računalo je riječ."ispis (string)ispis (word_tokenize (string))ispis (sent_tokenize (string))
Također pročitajte:Kako popraviti javascript: void (0) greška
Slično klasi DataFrame, klasa DocParser može se koristiti za analizu teksta u kodu. Klasa vam omogućuje da pozovete funkciju parse s putanjom datoteke.
Proces raščlanjivanja teksta
Da biste znali kako raščlaniti tekst pomoću DocParser klase, slijedite dolje navedene upute.
Bilješka: Da biste znali kako popraviti pogrešku analize, ova funkcija mora biti pravilno implementirana.
Alat za analizu teksta koristi se za izdvajanje određenih podataka iz varijabli i njihovo mapiranje u druge varijable. Ovo je neovisno o bilo kojim drugim alatima koji se koriste u zadatku, a alat BPA platforme koristi se za potrošnju i izlaz varijabli. Upotrijebite ovdje danu poveznicu za pristup Alat za analizu teksta na mreži i upotrijebite ranije dane odgovore o tome kako raščlaniti tekst.

TextFieldParser koristio je objekte za analizu i obradu vrlo velikih datoteka koje su strukturirane i razgraničene. U ovoj se metodi mogu koristiti širina i stupac teksta kao što su datoteke dnevnika ili informacije o naslijeđenoj bazi podataka. Metoda raščlanjivanja slična je ponavljanju koda preko tekstualne datoteke i uglavnom se koristi za izdvajanje polja teksta slično metodama manipulacije nizovima. Ovo se radi kako bi se tokenizirali razgraničeni nizovi i polja različitih širina pomoću definiranog razdjelnika kao što je zarez ili razmak tabulator.
Funkcije za analizu teksta
Sljedeće funkcije mogu se koristiti za analizu teksta u ovoj metodi.
Metode za pronalaženje MatchObject
Postoje dvije osnovne metode za pronalaženje MatchObject-a u kodu ili raščlanjenom tekstu.
U oba slučaja, ako polje ne odgovara navedenom formatu tijekom izvođenja analize ili pronalaženja načina analize teksta, MalformedLineException vraćena je iznimka.
Kao konačnu i jednostavnu metodu za analizu teksta, možete koristiti MS Excel aplikaciju kao parser za stvaranje datoteka odvojenih tabulatorima i zarezima. To bi pomoglo u unakrsnoj provjeri s vašim raščlanjenim rezultatom i pomoglo u pronalaženju načina ispravljanja pogreške raščlanjivanja.
1. Odaberite vrijednosti podataka u izvornoj datoteci i pritisnite Tipke Ctrl + C zajedno za kopiranje datoteke.
2. Otvori Excel aplikaciju pomoću Windows trake za pretraživanje.

3. Klikni na A1 ćeliju i pritisnite Tipke Ctrl + V istovremeno za lijepljenje kopiranog teksta.
4. Odaberite A1 ćelija, idite na Podaci i kliknite na Tekst u stupce opcija u Alati za podatke odjeljak.
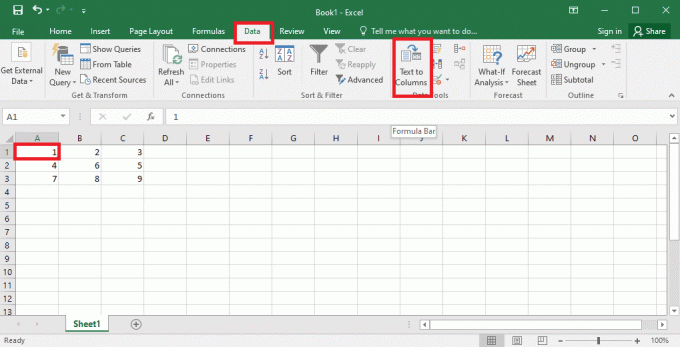
5A. Odaberite Razgraničeno opcija ako a zarez ili tab razmak se koristi kao separator i kliknite na Sljedeći i Završi gumbi.

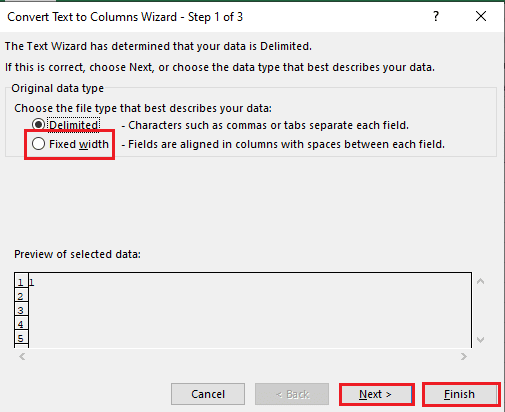
5B. Odaberite Fiksna širina opciju, dodijelite vrijednost za razdjelnik i kliknite na Sljedeći i Završi gumbi.
Također pročitajte:Kako popraviti pogrešku Move Excel Column
Pogreška u raščlanjivanju teksta x može se pojaviti na Android uređajima kao, Pogreška raščlanjivanja: Došlo je do problema pri raščlanjivanju paketa. To se obično događa kada se aplikacija ne uspije instalirati iz Trgovine Google Play ili tijekom pokretanja aplikacije treće strane.
Tekst pogreške x može se pojaviti ako je popis vektora znakova u petlji, a druge funkcije tvore linearni model za izračunavanje vrijednosti podataka. Poruka o pogrešci je Pogreška u analizi (tekst = x, keep.source = FALSE):
Možete pročitati članak na kako popraviti pogrešku parse na Androidu kako biste naučili uzroke i metode za ispravljanje pogreške.
Osim rješenja u vodiču, možete isprobati sljedeće popravke.
Preporučeno:
Članak pomaže u nastavi kako raščlaniti tekst i naučiti kako popraviti pogrešku analize. Javite nam koja je metoda pomogla popraviti pogrešku u raščlanjivanju teksta x i koja je metoda raščlanjivanja preferirana. Podijelite svoje prijedloge i upite u odjeljku za komentare u nastavku.
