
0
Nézetek

Ha megtanult néhány számítógépes programozási nyelvet, valószínűleg hallotta a szövegelemzés kifejezést. Ez a fájl összetett adatértékeinek egyszerűsítésére szolgál. A cikk segít abban, hogy megtudja, hogyan kell szöveget elemezni a nyelv használatával. Ezen túlmenően, ha hibába ütközött az x elemző szövegben, tudni fogja, hogyan javítsa ki az elemzési hibát a cikkben.
Tartalomjegyzék
Ebben a cikkben egy teljes útmutatót mutattunk be a szöveg különböző módokon történő elemzéséhez, valamint röviden bemutattuk a szöveg elemzését.
Mielőtt belevágna, tanulja meg a szövegelemzés fogalmait bármilyen kóddal. Fontos tudni a nyelv és a kódolás alapjait.
A szöveg elemzéséhez a természetes nyelvi feldolgozást vagy az NLP-t használják, amely a mesterséges intelligencia tartomány egyik almezője. A Python nyelv, amely a kategóriába tartozó nyelvek egyike, a szöveg elemzésére szolgál.
Az NLP kódok lehetővé teszik a számítógépek számára, hogy megértsék és feldolgozzák az emberi nyelveket, hogy alkalmassá tegyék azokat különféle alkalmazásokhoz. Az ML vagy Machine Learning technikák nyelvre történő alkalmazásához a strukturálatlan szöveges adatokat strukturált táblázatos adatokká kell konvertálni. Az elemzési tevékenység befejezéséhez a Python nyelvet használják a programkódok megváltoztatására.
A szöveg elemzése egyszerűen az adatok egyik formátumból egy másik formátumba való konvertálását jelenti. A fájl mentési formátumát elemezni kell, vagy más formátumú fájllá kell konvertálni, hogy a felhasználó különféle alkalmazásokban felhasználhassa.
A szöveg elemzésének okait ebben a részben ismertetjük, és ez egy előfeltétel a szövegelemzés ismerete előtt.
A Python nyelv DataFrame osztálya rendelkezik a szöveg elemzéséhez szükséges összes funkcióval. Ez a beépített könyvtár tartalmazza a szükséges kódokat, hogy bármilyen formátumú adatokat más formátumba elemezhessen.
A DataFrame osztály rövid bemutatása
A DataFrame Class egy funkciókban gazdag adatstruktúra, amelyet adatelemző eszközként használnak. Ez egy hatékony adatelemző eszköz, amellyel minimális erőfeszítéssel elemezhetők az adatok.
A Python nyelv pandái segítenek az SQL vagy adatbázis-stílusú műveletek maximális tökéletesítésében, hogy elkerüljék az x szövegelemzési hibákat. Néhány IO-eszközt is tartalmaz, amelyek segítenek a CSV, MS Excel, JSON, HDF5 és más adatformátumok fájlok elemzésében.
Olvassa el még:Javítsa ki a proxykérés során fellépő hibát
Szöveg elemzési folyamata DataFrame osztály használatával
A szöveg elemzésének megismeréséhez használhatja az ebben a részben megadott DataFrame osztályt használó szabványos folyamatot.
Jegyzet: A kód írása egy üres DataFrame-re fárasztó és bonyolult lehet. A pandák lehetővé teszik a DataFrame osztály adatainak létrehozását ezekből az adattípusokból. Így a primitív adattípusban lévő adatok könnyen elemezhetők a kívánt adatformátumba.
I. lehetőség: Szabványos formátum
Itt ismertetjük a szabványos módszert, amellyel bármilyen fájlt formázhatunk bizonyos adatformátummal, például CSV-vel.
Jegyzet: Itt a változó neve res végrehajtására szolgál olvas a fájlban lévő adatok funkciója data.txt a behozott pandák felhasználásával pd. A beviteli szöveg adatformátumát a CSV formátum.
Az alábbiakban egy példakód található a fent ismertetett folyamathoz, amely segít megérteni a szöveg elemzését.
import pandákat pd-kéntres = pd.read_csv('data.txt')res
Ebben az esetben, ha beírja az adatértékeket a fájlba data.txt mint például [1,2,3], akkor a rendszer elemzi és a következőként jeleníti meg 1 2 3.
II. lehetőség: String módszer
Ha a kódhoz adott szöveg csak karakterláncokat vagy alfa karaktereket tartalmaz, akkor a karakterláncban lévő speciális karakterek, például vessző, szóköz stb. használhatók a szöveg elválasztására és elemzésére. A folyamat hasonló a szokásos belső karakterlánc-műveletekhez. Az elemzési hiba kijavításának megtudásához kövesse a szöveg ezzel az opcióval történő elemzésének folyamatát, amelyet alább ismertetünk.
Például az alább megadott kódban a karakterlánc speciális karakterei my_string, amelyek, ',"és":’ azonosítják. Ezt a folyamatot óvatosan kell végrehajtani, hogy elkerüljük az x elemző szöveg hibáit.
Például a karakterlánc szöveges adatértékekre van felosztva a split paranccsal azonosított speciális karakterek alapján.
A fent ismertetett folyamat mintakódja az alábbiakban található.
my_string = 'Nevek: Tech, computer'sfinal = [name.strip() a névhez a my_string.split(':')[1].split(',')]print ("Nevek: {}".formátum (sfinal))
Ebben az esetben az elemzett karakterlánc eredménye az alábbiak szerint jelenik meg.
Nevek: ['Tech', 'computer']
A jobb áttekinthetőség és a szöveg elemzésének megismerése érdekében a karakterlánc használata közben a számára ciklust használjuk, és a kódot az alábbiak szerint módosítjuk.
my_string = 'Nevek: Tech, computer's1 = my_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [name.strip() a névhez az s3-ban]idx esetén az enumerate ([s1, s2, s3, s4]) elem:print ("Step {}: {}". formátum (idx, elem))
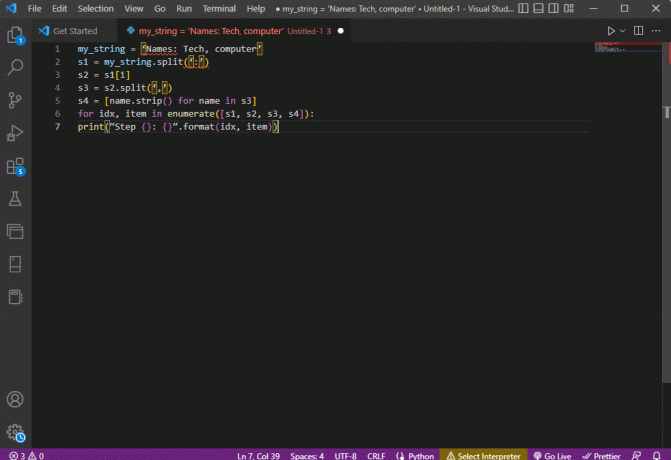
Az egyes lépések elemzett szövegének eredménye az alábbiak szerint jelenik meg. Megjegyzendő, hogy a 0. lépésben a karakterlánc a speciális karakter alapján lesz elválasztva : a szöveges adatértékeket pedig a karakter alapján különítjük el a további lépésekben.
0. lépés: ["Nevek", "Tech, számítógép"]1. lépés: Technika, számítógép2. lépés: [" Tech", "számítógép"]3. lépés: [„Tech”, „számítógép”]
III. lehetőség: Komplex fájl elemzése
A legtöbb esetben az elemezni kívánt fájladatok különböző adattípusokat és adatértékeket tartalmaznak. Ebben az esetben nehéz lehet a fájl elemzése a korábban ismertetett módszerekkel.
A fájlban található összetett adatok elemzésének funkciója az, hogy az adatértékek táblázatos formátumban jelenjenek meg.
Mielőtt belevágna a szövegelemzés megtanulásába ezzel a módszerrel, meg kell tanulnia néhány alapfogalmat. Az adatértékek elemzése reguláris kifejezések vagy Regex alapján történik.
Regex minták
Az elemzési hiba kijavításához meg kell győződnie arról, hogy a kifejezésekben a regex minták megfelelőek. A karakterláncok adatértékeinek elemzésére szolgáló kód az ebben a szakaszban alább felsorolt általános Regex-mintákat tartalmazná.
Reguláris kifejezések
A Python nyelvben a reguláris kifejezés modulok a pandas csomag fő részét képezik, és a rossz re hibához vezethet az x szövegelemzésben. Ez egy apró nyelv, amely a Pythonba van beágyazva, hogy megtalálja a karakterlánc-mintát a kifejezésben. A reguláris kifejezések vagy a reguláris kifejezések speciális szintaxisú karakterláncok. Lehetővé teszi a felhasználó számára, hogy a karakterláncok értékei alapján más karakterláncok mintáit illessze.
A Regex az adattípus és a karakterláncban lévő kifejezés követelménye alapján jön létre, mint pl Karakterlánc = (.*)\n. A regex minden kifejezésben a minta előtt használatos. A reguláris kifejezésekben használt szimbólumok az alábbiakban találhatók, és segítenek a szöveg elemzésének megismerésében.
RegexObjects
A RegexObject a fordítási függvény visszatérési értéke, és egy MatchObject visszaadására szolgál, ha a kifejezés megegyezik az egyezési értékkel.
1. MatchObject
Mivel a MatchObject logikai értéke mindig True, használhat egy ha utasítással azonosítja az objektum pozitív egyezéseit. Használata esetén a ha utasítás, az index által hivatkozott csoport a kifejezésben szereplő objektum egyezésének kiderítésére szolgál.
2. A MatchObject módszerei
A szöveg elemzése során fontos tudni, hogy a MatchObject két alapvető módszerrel rendelkezik az alábbiak szerint. Ha a MatchObject megtalálható a megadott kifejezésben, akkor a példányát adja vissza, ellenkező esetben a None-t.
Reguláris kifejezés függvények
A reguláris függvények olyan kódsorok, amelyek egy bizonyos funkció végrehajtására szolgálnak a felhasználó által a beszerzett adatértékek halmazából.
Jegyzet: A függvények írásához nyers karakterláncokat használnak a reguláris kifejezésekhez, hogy elkerüljék a hibákat az x elemző szövegben. Ez az alsó index hozzáadásával történik r a kifejezés minden mintája előtt.
A kifejezésekben használt gyakori függvények magyarázata az alábbiakban található.
1. re.findall()
Ez a függvény visszaadja a karakterlánc összes mintáját, ha egyezés található, és egy üres listát ad vissza, ha nem található egyezés. Például a funkció, string = re.findall('[aeiou]', regex_fájlnév) A fájlnévben a magánhangzó előfordulásának megkeresésére szolgál.
2. re.split()
Ez a funkció a karakterlánc felosztására szolgál, ha egy megadott karakterrel, például szóközzel talál egyezést. Ha nem található egyezés, üres karakterláncot ad vissza.
3. re.sub()
A függvény az egyező szöveget a megadott helyettesítő változó tartalmával helyettesíti. Más függvényekkel ellentétben, ha nem található minta, a rendszer az eredeti karakterláncot adja vissza.
4. kutatás()
Az egyik alapvető funkció, amely segít a szövegelemzés megtanulásában, a keresési funkció. Segít a minta keresésében a karakterláncban és a megfelelő objektum visszaadásában. Ha a keresés sikertelen az egyezés azonosításában, nem ad vissza értéket.
5. re.compile (minta)
Ezt a funkciót arra használják, hogy reguláris kifejezési mintákat fordítsanak RegexObject-be, amiről korábban volt szó.
Egyéb követelmények
A felsorolt követelmények a haladó programozók által az adatelemzés során használt kiegészítő szolgáltatás.
Olvassa el még:A NumPy telepítése Windows 10 rendszeren
A szöveg elemzésének folyamata
Az alábbiakban ismertetjük a szöveg elemzésének módszerét ebben az összetett beállításban.
A parancs adatok = pd. DataFrame (adat) Pandas DataFrame létrehozására szolgál a diktált értékekből. Alternatív megoldásként használhatja a következő parancsokat a megfelelő célra, az alábbiak szerint.
Az utolsó lépés a szöveg elemzésének megismeréséhez az, hogy tesztelje az elemzőt a ha nyilatkozat az értékek változóhoz való hozzárendelésével adat és kinyomtatja a segítségével nyomtatás (adat) parancs.
A fenti magyarázat példakódja itt található.
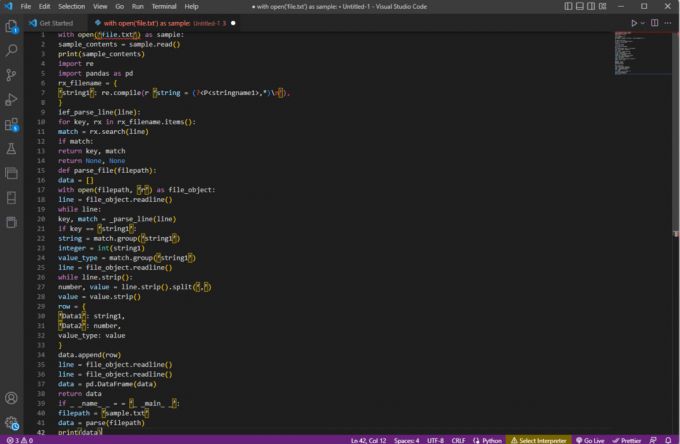
az open('file.txt') mintával:minta_tartalom = sample.read()nyomtatás (minta_tartalom)import reimport pandákat pd-kéntrx_fájlnév = {‘karakterlánc1’: re.compile (r ‘string = (?,*)\n’),
}ief_parse_line (sor):kulcs esetén rx az rx_filename.items()-ben:egyezés = rx.search (sor)ha egyezés:visszatérési kulcs, gyufareturn Nincs, Nincsdef parse_file (fájlútvonal):adatok = []nyitott (filepath, 'r') mint file_object:sor = file_object.readline()míg sor:kulcs, egyezés = _parse_line (sor)if key == ‘karakterlánc1’:string = match.group('karakterlánc1')egész = int (karakterlánc1)érték_típus = match.group('karakterlánc1')sor = file_object.readline()while line.strip():szám, érték = line.strip().split(‘,’)érték = value.strip()sor = {„Adat1”: string1,„Data2”: szám,value_type: érték}data.append (sor)sor = file_object.readline()sor = file_object.readline()adatok = pd. DataFrame (adat)visszaadja az adatokatif _ _name_ _ = = '_ _main_ _':filepath = 'minta.txt'adatok = elemzés (fájlútvonal)nyomtatás (adat)
Azt a folyamatot, amelynek során egy szöveget vagy korpuszt tokenekké vagy kisebb darabokká alakítanak át bizonyos szabályok alapján, tokenizálásnak nevezik. Az elemzési hiba kijavításának megismeréséhez fontos elemezni a kódban található szó tokenizációs parancsokat. A regexhez hasonlóan ezzel a módszerrel is lehet saját szabályokat létrehozni, és segítséget nyújt a szöveg-előkészítési feladatokban, például a beszédrészek leképezésében. Ezzel a módszerrel olyan tevékenységeket is végrehajtanak, mint a gyakori szavak keresése és egyeztetése, a szöveg tisztítása és az adatok előkészítése a fejlett szövegelemzési technikákhoz, például a hangulatelemzéshez. Ha a tokenizálás nem megfelelő, hiba léphet fel az x elemző szövegben.
NLTK Könyvtár
A folyamat az NLTK nevű népszerű nyelvi eszköztárat veszi igénybe, amely gazdag funkciókészlettel rendelkezik számos NLP-feladat végrehajtásához. Ezeket a Pip vagy Pip Telepítési csomagokon keresztül lehet letölteni. A szöveg elemzésének megismeréséhez használhatja az Anaconda disztribúció alapcsomagját, amely alapértelmezés szerint tartalmazza a könyvtárat.
A tokenizálás formái
Ennek a módszernek a gyakori formái a szó tokenizálás és a mondat tokenizálás. A szószintű tokennek köszönhetően az előbbi csak egyszer, míg az utóbbi mondatszinten írja ki a szót.
A szöveg elemzésének folyamata
A fenti tokenizálás lépéseit magyarázó kód itt található.
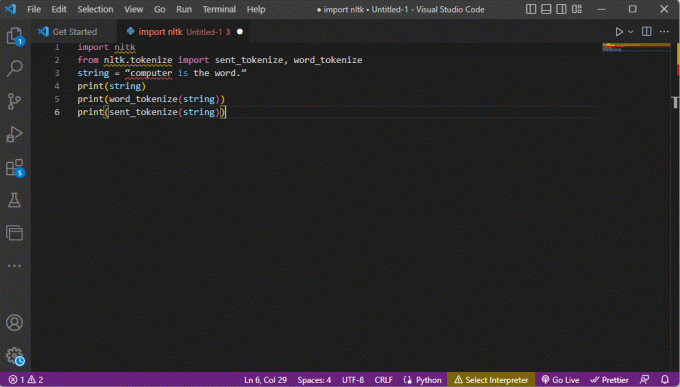
import nltkinnen: nltk.tokenize import send_tokenize, word_tokenizestring = "a számítógép a szó."nyomtatás (karakterlánc)nyomtatás (word_tokenize (karakterlánc))nyomtatás (elküldött_tokenizálás (karakterlánc))
Olvassa el még:A javascript javítása: void (0) Hiba
A DataFrame osztályhoz hasonlóan a Class DocParser is használható a kód szövegének elemzésére. Az osztály lehetővé teszi a parse függvény meghívását a fájl elérési útjával.
A szöveg elemzésének folyamata
Ha tudni szeretné, hogyan kell szöveget elemezni a DocParser osztály használatával, kövesse az alábbi utasításokat.
Jegyzet: Az elemzési hiba kijavításához ezt a funkciót helyesen kell végrehajtani.
A Szövegelemzés eszközzel meghatározott adatok kinyerhetők a változókból, és leképezhetők más változókra. Ez független a feladatban használt egyéb eszközöktől, és a BPA Platform eszközt használják a változók fogyasztására és kiadására. Az itt található link segítségével elérheti a Szövegelemzési eszköz online és használja a korábban adott válaszokat a szöveg elemzéséhez.

A TextFieldParser objektumokat használt a nagyon nagy, strukturált és elhatárolt fájlok elemzésére és feldolgozására. Ebben a módszerben a szöveg szélessége és oszlopa, például naplófájlok vagy örökölt adatbázis-információk használhatók. Az elemzési módszer hasonló a kód szövegfájlon történő iterálásához, és főként a karakterlánc-manipulációs módszerekhez hasonló szövegmezők kinyerésére szolgál. Ez az elválasztott karakterláncok és különböző szélességű mezők tokenizálására szolgál a meghatározott határolóval, például vesszővel vagy tabulátorral.
Szöveg elemzésére szolgáló függvények
A következő függvények használhatók a szöveg elemzésére ebben a módszerben.
Módszerek a MatchObject megkeresésére
Két alapvető módszer létezik a MatchObject megtalálására a kódban vagy az elemzett szövegben.
Bármelyik esetben, ha egy mező nem egyezik a megadott formátummal az elemzés végrehajtása vagy a szöveg elemzésének megkeresése közben, a Rosszul formázottLineException kivétel visszakerül.
A szöveg elemzésének végső és egyszerű módszereként használhatja a MS Excel alkalmazás elemzőként tabulátorral tagolt és vesszővel tagolt fájlok létrehozásához. Ez segít az elemzési eredmény összehasonlításában, és segít megtalálni az elemzési hiba kijavítását.
1. Válassza ki az adatértékeket a forrásfájlban, és nyomja meg a gombot Ctrl + C billentyűk együtt a fájl másolásához.
2. Nyissa meg a Excel alkalmazást a Windows keresősávjával.

3. Kattintson a A1 cellát, és nyomja meg a gombot Ctrl + V billentyűk egyidejűleg a másolt szöveg beillesztéséhez.
4. Válaszd ki a A1 cella, navigáljon a Adat fület, és kattintson a Szöveg oszlopokba opció a Adateszközök szakasz.
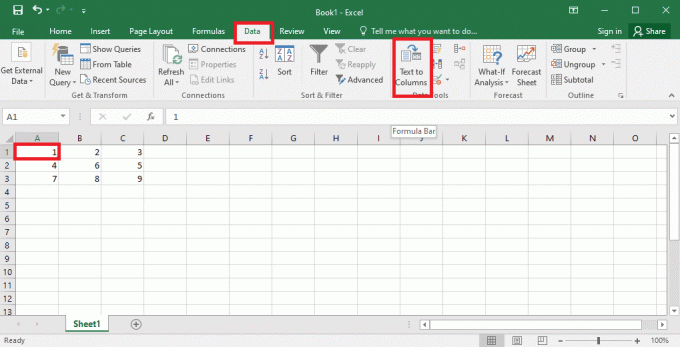
5A. Válaszd ki a Elhatárolt opció, ha a vessző vagy lapon szóközt használ elválasztóként, majd kattintson a gombra Következő és Befejez gombokat.

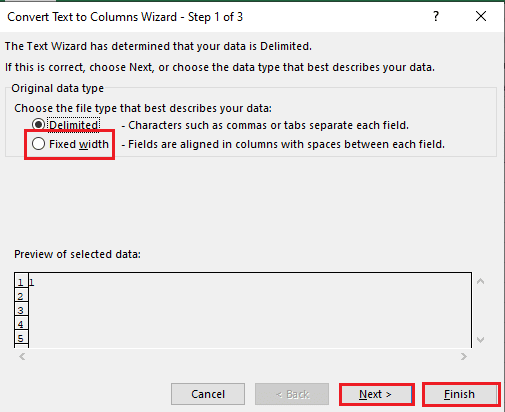
5B. Válaszd ki a Fix szélesség opciót, adjon hozzá egy értéket az elválasztóhoz, és kattintson a gombra Következő és Befejez gombokat.
Olvassa el még:Az Excel-oszlop áthelyezési hibájának javítása
Az x szövegelemzési hiba előfordulhat Android-eszközökön: Elemzési hiba: Hiba történt a csomag elemzése során. Ez általában akkor fordul elő, ha az alkalmazást nem sikerül telepíteni a Google Play Áruházból, vagy ha harmadik féltől származó alkalmazást futtat.
Az x hibaszöveg akkor fordulhat elő, ha a karaktervektorok listája hurkolt, és más függvények lineáris modellt alkotnak az adatértékek kiszámításához. A hibaüzenet Error in parse (text = x, keep.source = FALSE):
A cikket elolvashatja hogyan lehet javítani az elemzési hibát Androidon hogy megismerje a hiba okait és módszereit.
Az útmutatóban szereplő megoldásokon kívül a következő javításokat is kipróbálhatja.
Ajánlott:
A cikk segít a tanításban hogyan kell szöveget elemezni és megtudhatja, hogyan javíthatja ki az elemzési hibát. Tudassa velünk, hogy melyik módszer segített kijavítani a hibát az x elemző szövegben, és melyik elemzési módszert részesítjük előnyben. Kérjük, ossza meg javaslatait és kérdéseit az alábbi megjegyzések részben.

