
0
Visualizzazioni

Se hai imparato alcuni linguaggi di programmazione per computer, potresti aver sentito il termine, analizzare il testo. Questo viene utilizzato per semplificare i valori di dati complessi del file. L'articolo ti aiuta a sapere come analizzare il testo usando la lingua. Inoltre, se hai riscontrato un errore nell'analisi del testo x, saprai come correggere l'errore di analisi nell'articolo.
Sommario
In questo articolo, abbiamo mostrato una guida completa per analizzare il testo in vari modi e abbiamo anche fornito una breve introduzione all'analisi del testo.
Prima di approfondire, apprendere i concetti di analisi del testo utilizzando qualsiasi codice. È importante conoscere le basi della lingua e della codifica.
Per analizzare il testo, viene utilizzato Natural Language Processing o NLP, che è un sottocampo del dominio dell'Intelligenza Artificiale. Il linguaggio Python, che è uno dei linguaggi che appartengono alla categoria, viene utilizzato per analizzare il testo.
I codici NLP consentono ai computer di comprendere ed elaborare i linguaggi umani per renderli adatti a varie applicazioni. Per applicare le tecniche di ML o Machine Learning alla lingua, i dati di testo non strutturati devono essere convertiti in dati tabulari strutturati. Per completare l'attività di analisi, viene utilizzato il linguaggio Python per alterare i codici del programma.
Analizzare il testo significa semplicemente convertire i dati da un formato a un altro formato. Il formato in cui il file viene salvato deve essere analizzato o convertito in un file in un formato diverso per consentire all'utente di utilizzarlo in varie applicazioni.
I motivi per cui il testo deve essere analizzato sono indicati in questa sezione ed è una conoscenza preliminare prima di sapere come analizzare il testo.
La classe DataFrame del linguaggio Python ha tutte le funzioni necessarie per analizzare il testo. Questa libreria integrata ospita i codici necessari per analizzare i dati di qualsiasi formato in un altro formato.
Breve introduzione della classe DataFrame
DataFrame Class è una struttura dati ricca di funzionalità, che viene utilizzata come strumento di analisi dei dati. Questo è un potente strumento di analisi dei dati che può essere utilizzato per analizzare i dati con il minimo sforzo.
I panda del linguaggio Python aiutano a eseguire le operazioni SQL o in stile database con la massima perfezione per evitare errori nell'analisi del testo x. Contiene anche alcuni strumenti IO che aiutano ad analizzare i file di CSV, MS Excel, JSON, HDF5 e altri formati di dati.
Leggi anche:Errore di correzione verificatosi durante il tentativo di richiesta proxy
Processo di analisi del testo utilizzando la classe DataFrame
Per sapere come analizzare il testo, puoi utilizzare il processo standard utilizzando la classe DataFrame fornita in questa sezione.
Nota: Scrivere il codice su un DataFrame vuoto può essere noioso e complesso. I panda consentono di creare i dati sulla classe DataFrame da questi tipi di dati. Pertanto, i dati nel tipo di dati primitivo possono essere facilmente analizzati nel formato dati richiesto.
Opzione I: formato standard
Il metodo standard per formattare qualsiasi file con un determinato formato di dati come CSV è spiegato qui.
Nota: Qui, la variabile denominata ris viene utilizzato per eseguire il Leggere funzione dei dati nel file dati.txt utilizzando i panda importati pd. Il formato dei dati del testo di input è specificato nel file CSV formato.
Un codice di esempio per il processo spiegato sopra è fornito di seguito e aiuterà a capire come analizzare il testo.
importa panda come pdres = pd.read_csv('dati.txt')ris
In questo caso, se inserisci i valori dei dati nel file dati.txt ad esempio [1,2,3], verrebbe analizzato e visualizzato come 1 2 3.
Opzione II: metodo delle stringhe
Se il testo dato al codice contiene solo stringhe o caratteri alfabetici, i caratteri speciali nella stringa come virgole, spazio, ecc., possono essere usati per separare e analizzare il testo. Il processo è simile alle comuni operazioni di stringhe interne. Per scoprire come correggere l'errore di analisi, devi seguire il processo di analisi del testo utilizzando questa opzione spiegata di seguito.
Ad esempio, nel codice fornito di seguito, i caratteri speciali nella stringa mia_stringa, quali sono, ',' E ':' sono identificati. Questo processo deve essere eseguito con attenzione per evitare errori nell'analisi del testo x.
Ad esempio, la stringa viene suddivisa in valori di dati di testo basati sui caratteri speciali identificati utilizzando il comando split.
Il codice di esempio per il processo spiegato sopra è riportato di seguito.
my_string = 'Nomi: tecnico, computer'sfinal = [nome.strip() for nome in mia_stringa.split(‘:’)[1].split(‘,’)]print("Nomi: {}".format (sfinal))
In questo caso, il risultato della stringa analizzata verrebbe visualizzato come mostrato di seguito.
Nomi: ['Tech', 'computer']
Per ottenere maggiore chiarezza e sapere come analizzare il testo durante l'utilizzo della stringa di testo, a per loop viene utilizzato e il codice viene modificato come segue.
my_string = 'Nomi: tecnico, computer's1 = mia_stringa.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [nome.strip() per nome in s3]per idx, elemento in enumerate([s1, s2, s3, s4]):print("Passaggio {}: {}".format (idx, item))
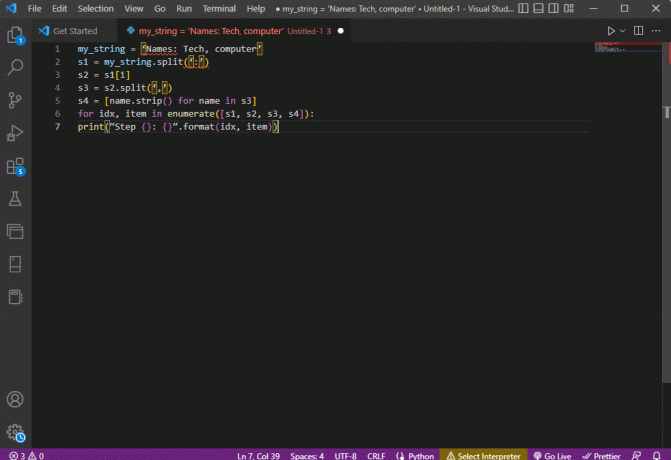
Il risultato del testo analizzato per ciascuno di questi passaggi viene visualizzato come indicato di seguito. Puoi notare che, nel passaggio 0, la stringa è separata in base al carattere speciale : e i valori dei dati di testo vengono separati in base al carattere in ulteriori passaggi.
Passaggio 0: ['Nomi', 'Tecnico, computer']Passaggio 1: tecnologia, computerPassaggio 2: ['Tech', 'computer']Passaggio 3: ['Tecnico', 'computer']
Opzione III: analisi di file complessi
Nella maggior parte dei casi, i dati del file che devono essere analizzati contengono diversi tipi di dati e valori di dati. In questo caso, potrebbe essere difficile analizzare il file utilizzando i metodi spiegati in precedenza.
Le caratteristiche dell'analisi dei dati complessi nel file sono di visualizzare i valori dei dati in un formato tabulare.
Prima di approfondire l'apprendimento di come analizzare il testo in questo metodo, è necessario apprendere alcuni concetti di base. L'analisi dei valori dei dati viene eseguita in base a espressioni regolari o Regex.
Modelli Regex
Per sapere come correggere l'errore di analisi, devi assicurarti che i pattern regex nelle espressioni siano corretti. Il codice per analizzare i valori dei dati delle stringhe implicherebbe i modelli Regex comuni elencati di seguito in questa sezione.
Espressioni regolari
I moduli delle espressioni regolari sono una parte importante del pacchetto pandas nel linguaggio Python e un errore re può portare a un errore nell'analisi del testo x. È un minuscolo linguaggio incorporato in Python per trovare il modello di stringa nell'espressione. Le espressioni regolari o Regex sono stringhe con una sintassi speciale. Consente all'utente di abbinare modelli in altre stringhe in base ai valori nelle stringhe.
La Regex viene creata in base al tipo di dati e al requisito dell'espressione nella stringa, ad esempio Stringa = (.*)\n. La regex viene utilizzata prima del modello in ogni espressione. I simboli utilizzati nelle espressioni regolari sono elencati di seguito e aiuteranno a sapere come analizzare il testo.
RegexObjects
RegexObject è un valore restituito per la funzione di compilazione e viene utilizzato per restituire un MatchObject se l'espressione corrisponde al valore di corrispondenza.
1. AbbinaOggetto
Poiché il valore booleano di MatchObject è sempre True, puoi utilizzare an Se istruzione per identificare le corrispondenze positive nell'oggetto. Nel caso di utilizzo del Se istruzione, il gruppo a cui fa riferimento l'indice viene utilizzato per scoprire la corrispondenza dell'oggetto nell'espressione.
2. Metodi di MatchObject
Durante la ricerca di come analizzare il testo, è importante sapere che MatchObject ha due metodi di base elencati di seguito. Se il MatchObject viene trovato nell'espressione specificata, restituirà la sua istanza, altrimenti restituirà None.
Funzioni di espressione regolare
Le funzioni Regex sono righe di codice che vengono utilizzate per eseguire una determinata funzione come specificato dall'utente dall'insieme di valori di dati procurati.
Nota: Per scrivere le funzioni, vengono utilizzate stringhe grezze per le espressioni regolari per evitare errori nell'analisi del testo x. Questo viene fatto aggiungendo il pedice R prima di ogni pattern nell'espressione.
Le funzioni comuni utilizzate nelle espressioni sono spiegate di seguito.
1. re.trovall()
Questa funzione restituisce tutti i modelli nella stringa se viene trovata una corrispondenza e restituisce un elenco vuoto se non viene trovata alcuna corrispondenza. Ad esempio, la funzione, string = re.findall('[aeiou]', regex_filename) è usato per trovare l'occorrenza vocale nel nome del file.
2. re.split()
Questa funzione viene utilizzata per dividere la stringa in caso di corrispondenza con un carattere specificato, ad esempio viene trovato uno spazio. In caso di mancata corrispondenza, restituisce una stringa vuota.
3. re.sub()
La funzione sostituisce il testo corrispondente con il contenuto della variabile di sostituzione fornita. Contrariamente ad altre funzioni, se non viene trovato alcun modello, viene restituita la stringa originale.
4. ricerca()
Una delle funzioni di base per aiutare a imparare come analizzare il testo è la funzione di ricerca. Aiuta a cercare il modello nella stringa e a restituire l'oggetto match. Se la ricerca non riesce a identificare la corrispondenza, non viene restituito alcun valore.
5. ricompilare (schema)
Questa funzione viene utilizzata per compilare modelli di espressioni regolari in un RegexObject, discusso in precedenza.
Altri requisiti
I requisiti elencati sono una funzionalità aggiuntiva utilizzata dai programmatori avanzati nell'analisi dei dati.
Leggi anche:Come installare NumPy su Windows 10
Processo di analisi del testo
Il metodo per analizzare il testo in questa opzione complessa è descritto come indicato di seguito.
Il comando dati = pd. DataFrame (dati) viene utilizzato per creare un DataFrame panda dai valori dict. In alternativa, è possibile utilizzare i seguenti comandi per il rispettivo scopo indicato di seguito.
Il passaggio finale per sapere come analizzare il testo è testare il parser utilizzando il file se dichiarazione assegnando i valori a una variabile dati e stamparlo utilizzando il file stampa (dati) comando.
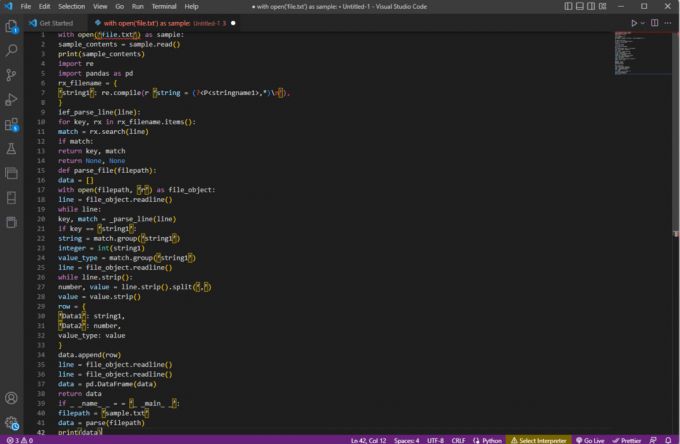
Il codice di esempio per la spiegazione di cui sopra è fornito qui.
con open('file.txt') come esempio:sample_contents = sample.read()stampa (sample_contents)importa reimporta panda come pdrx_nomefile = {'stringa1': re.compile (r 'stringa = (?,*)\N'),
}ief_parse_line (linea):per chiave, rx in rx_filename.items():match = rx.search (riga)se corrisponde:chiave di ritorno, partitarestituisce Nessuno, Nessunodef parse_file (percorso file):dati = []con open (filepath, 'r') come file_object:riga = file_oggetto.readline()mentre la linea:chiave, corrispondenza = _parse_line (linea)if chiave == 'stringa1':stringa = match.group('stringa1')numero intero = int (stringa1)value_type = match.group('stringa1')riga = file_oggetto.readline()mentre linea.strip():numero, valore = line.strip().split(‘,’)valore = valore.strip()riga = {"Dati1": stringa1,"Dati2": numero,tipo_valore: valore}data.append (riga)riga = file_oggetto.readline()riga = file_oggetto.readline()dati = pd. DataFrame (dati)restituire i datiif _ _name_ _ = = '_ _main_ _':percorso file = 'campione.txt'data = analizza (percorso file)stampa (dati)
Il processo di conversione di un testo o di un corpus in token o pezzi più piccoli in base a determinate regole è chiamato tokenizzazione. Per sapere come correggere l'errore di analisi, è importante analizzare la parola comandi di tokenizzazione nel codice. Simile alla regex, in questo metodo è possibile creare regole proprie e aiuta nelle attività di pre-elaborazione del testo come la mappatura di parti del discorso. Inoltre, con questo metodo vengono eseguite attività come la ricerca e la corrispondenza di parole comuni, la pulizia del testo e la preparazione dei dati per tecniche avanzate di analisi del testo come l'analisi del sentiment. Se la tokenizzazione non è corretta, potrebbe verificarsi un errore nel testo di analisi x.
Libreria NLTK
Il processo richiede l'aiuto della popolare libreria di toolkit linguistici chiamata NLTK, che ha un ricco set di funzioni per eseguire molti lavori di PNL. Questi possono essere scaricati tramite i pacchetti Pip o Pip Installs. Per sapere come analizzare il testo, puoi utilizzare il pacchetto base della distribuzione Anaconda che include la libreria per impostazione predefinita.
Forme di tokenizzazione
Le forme comuni di questo metodo sono la tokenizzazione delle parole e la tokenizzazione delle frasi. Grazie al token a livello di parola, il primo stampa una parola solo una volta, mentre il secondo stampa la parola a livello di frase.
Processo di analisi del testo
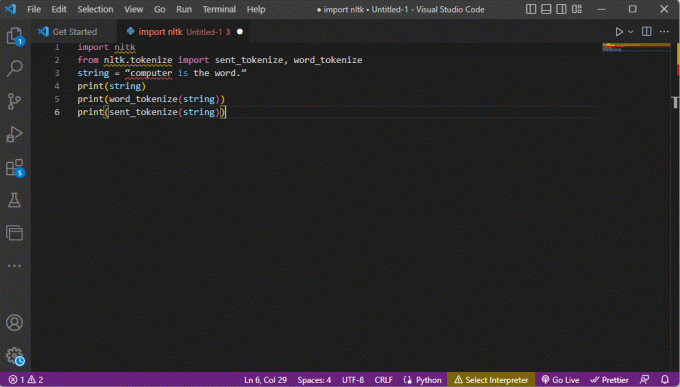
Il codice che spiega i passaggi per la tokenizzazione di cui sopra è fornito qui.
importa nltkda nltk.tokenize import sent_tokenize, word_tokenizestring = "computer è la parola".stampa (stringa)stampa (word_tokenize (stringa))stampa (sent_tokenize (stringa))
Leggi anche:Come risolvere javascript: errore void (0).
Simile alla classe DataFrame, la classe DocParser può essere utilizzata per analizzare il testo nel codice. La classe ti consente di chiamare la funzione parse con il filepath.
Processo di analisi del testo
Per sapere come analizzare il testo utilizzando la classe DocParser, seguire le istruzioni fornite di seguito.
Nota: Per sapere come correggere l'errore di analisi, questa funzione deve essere implementata correttamente.
Lo strumento Analizza testo viene utilizzato per estrarre dati specifici dalle variabili e mapparli ad altre variabili. Questo è indipendente da qualsiasi altro strumento utilizzato in un'attività e lo strumento della piattaforma BPA viene utilizzato per consumare e produrre variabili. Utilizzare il collegamento fornito qui per accedere al Analizza lo strumento di testo online e utilizzare le risposte fornite in precedenza su come analizzare il testo.

TextFieldParser ha utilizzato oggetti per analizzare ed elaborare file molto grandi, strutturati e delimitati. In questo metodo è possibile utilizzare la larghezza e la colonna del testo, ad esempio i file di registro o le informazioni del database legacy. Il metodo di analisi è simile all'iterazione del codice su un file di testo e viene utilizzato principalmente per estrarre campi di testo simili ai metodi di manipolazione delle stringhe. Questo viene fatto per tokenizzare stringhe delimitate e campi di varie larghezze utilizzando il delimitatore definito come virgola o spazio di tabulazione.
Funzioni per analizzare il testo
Le seguenti funzioni possono essere utilizzate per analizzare il testo in questo metodo.
Metodi per trovare MatchObject
Esistono due metodi di base per trovare il MatchObject nel codice o nel testo analizzato.
In entrambi i casi, se un campo non corrisponde al formato specificato durante l'esecuzione dell'analisi o la ricerca di come analizzare il testo, a MalformatoLineException viene restituita l'eccezione.
Come metodo finale e semplice per analizzare il testo, puoi utilizzare il file Microsoft Excel app come parser per creare file delimitati da tabulazioni e delimitati da virgole. Ciò aiuterebbe nel controllo incrociato con il risultato analizzato e aiuterebbe a trovare come correggere l'errore di analisi.
1. Selezionare i valori dei dati nel file di origine e premere il tasto Tasti Ctrl+C insieme per copiare il file.
2. Apri il Eccellere app utilizzando la barra di ricerca di Windows.

3. Clicca sul A1 cellulare e premere il Tasti Ctrl+V contemporaneamente per incollare il testo copiato.
4. Seleziona il A1 cella, vai al file Dati scheda e fare clic su Testo in colonne opzione nel Strumenti dati sezione.
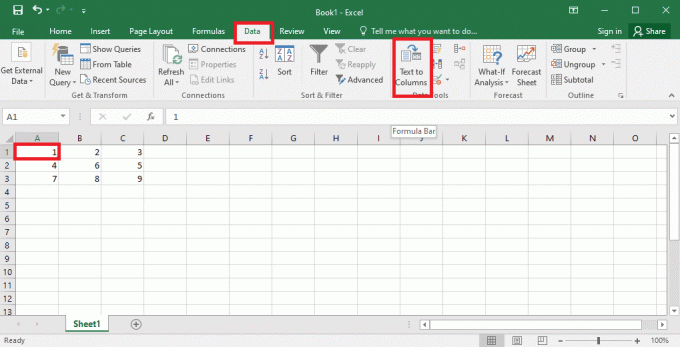
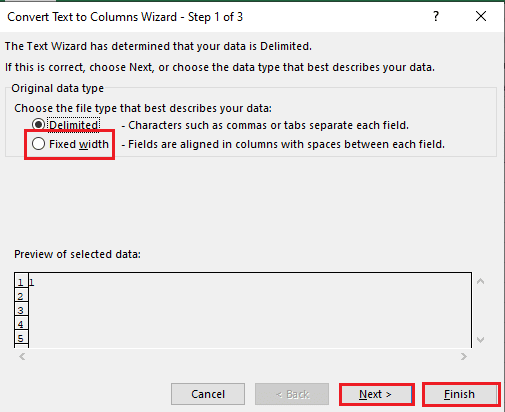
5A. Seleziona il Delimitato opzione se a virgola O scheda lo spazio viene utilizzato come separatore e fare clic su Prossimo E Fine pulsanti.

5B. Seleziona il Larghezza fissa opzione, assegnare un valore per il separatore e fare clic sull'icona Prossimo E Fine pulsanti.
Leggi anche:Come correggere l'errore di spostamento della colonna di Excel
L'errore nel testo di analisi x può verificarsi su dispositivi Android come Errore di analisi: si è verificato un problema durante l'analisi del pacchetto. Questo di solito si verifica quando l'app non viene installata dal Google Play Store o durante l'esecuzione di un'app di terze parti.
Il testo di errore x può verificarsi se l'elenco dei vettori di caratteri è in loop e altre funzioni formano un modello lineare per il calcolo dei valori dei dati. Il messaggio di errore è Error in parse (text = x, keep.source = FALSE):
Puoi leggere l'articolo su come correggere l'errore di analisi su Android per conoscere le cause ei metodi per correggere l'errore.
Oltre alle soluzioni nella guida, puoi provare le seguenti correzioni.
Consigliato:
L'articolo aiuta nell'insegnamento come analizzare il testo e per imparare a correggere l'errore di analisi. Facci sapere quale metodo ha aiutato a correggere l'errore nell'analisi del testo x e quale metodo di analisi è preferito. Si prega di condividere i vostri suggerimenti e domande nella sezione commenti qui sotto.

