27/04/2023

თუ თქვენ ისწავლეთ კომპიუტერული პროგრამირების რამდენიმე ენა, შესაძლოა გსმენიათ ტერმინი, ტექსტის გარჩევა. ეს გამოიყენება ფაილის რთული მონაცემთა მნიშვნელობების გასამარტივებლად. სტატია დაგეხმარებათ გაიგოთ, თუ როგორ უნდა გააანალიზოთ ტექსტი ენის გამოყენებით. ამას გარდა, თუ შეგექმნათ შეცდომა ტექსტის ანალიზში x, თქვენ გეცოდინებათ როგორ გამოასწოროთ გაანალიზების შეცდომა სტატიაში.
Სარჩევი
ამ სტატიაში ჩვენ ვაჩვენეთ სრული გზამკვლევი ტექსტის გარჩევისთვის სხვადასხვა გზით და ასევე მოკლედ მივეცი შესავალი ტექსტის გარჩევის შესახებ.
სანამ ჩავუღრმავდებით, ისწავლეთ ტექსტის გარჩევის ცნებები ნებისმიერი კოდის გამოყენებით. მნიშვნელოვანია იცოდეთ ენისა და კოდირების საფუძვლების შესახებ.
ტექსტის გასაანალიზებლად გამოიყენება ბუნებრივი ენის დამუშავება ან NLP, რომელიც წარმოადგენს ხელოვნური ინტელექტის დომენის ქვეველს. პითონის ენა, რომელიც არის ერთ-ერთი ენა, რომელიც ეკუთვნის კატეგორიას, გამოიყენება ტექსტის გასაანალიზებლად.
NLP კოდები კომპიუტერებს საშუალებას აძლევს გაიგონ და დაამუშავონ ადამიანის ენები, რათა ისინი შესაფერისი იყოს სხვადასხვა აპლიკაციებისთვის. ენაზე ML ან მანქანათმცოდნეობის ტექნიკის გამოსაყენებლად, არასტრუქტურირებული ტექსტის მონაცემები უნდა გარდაიქმნას სტრუქტურირებულ ცხრილის მონაცემებად. ანალიზის აქტივობის დასასრულებლად პითონის ენა გამოიყენება პროგრამის კოდების შესაცვლელად.
ტექსტის გარჩევა უბრალოდ ნიშნავს მონაცემთა ერთი ფორმატიდან მეორე ფორმატში გადაყვანას. ფორმატი, რომელშიც ინახება ფაილი, უნდა იყოს გაანალიზებული ან გარდაიქმნება ფაილად სხვა ფორმატში, რათა მომხმარებელს მისცეს საშუალება გამოიყენოს იგი სხვადასხვა აპლიკაციებში.
მიზეზები, რისთვისაც ტექსტი უნდა გაანალიზდეს, მოცემულია ამ განყოფილებაში და ეს არის წინასწარი ცოდნა ტექსტის ანალიზამდე.
Python ენის DataFrame კლასს აქვს ყველა საჭირო ფუნქცია ტექსტის გასაანალიზებლად. ეს ჩაშენებული ბიბლიოთეკა შეიცავს აუცილებელ კოდებს ნებისმიერი ფორმატის მონაცემების სხვა ფორმატში გასაანალიზებლად.
DataFrame კლასის მოკლე შესავალი
DataFrame Class არის ფუნქციებით მდიდარი მონაცემთა სტრუქტურა, რომელიც გამოიყენება როგორც მონაცემთა ანალიზის ინსტრუმენტი. ეს არის მონაცემთა ანალიზის მძლავრი ინსტრუმენტი, რომელიც შეიძლება გამოყენებულ იქნას მონაცემთა ანალიზისთვის მინიმალური ძალისხმევით.
პითონის ენის პანდები ეხმარებიან SQL-ის ან მონაცემთა ბაზის სტილის ოპერაციების შესრულებაში მაქსიმალური სრულყოფილად, რათა თავიდან იქნას აცილებული შეცდომა ტექსტის გაანალიზებაში. ის ასევე შეიცავს IO ინსტრუმენტებს, რომლებიც დაგეხმარებათ CSV, MS Excel, JSON, HDF5 და სხვა მონაცემთა ფორმატების ფაილების ანალიზში.
ასევე წაიკითხეთ:პროქსის მოთხოვნის მცდელობისას წარმოქმნილი შეცდომის გამოსწორება
ტექსტის გაანალიზების პროცესი DataFrame კლასის გამოყენებით
იმისათვის, რომ იცოდეთ როგორ გააანალიზოთ ტექსტი, შეგიძლიათ გამოიყენოთ სტანდარტული პროცესი ამ განყოფილებაში მოცემული DataFrame კლასის გამოყენებით.
Შენიშვნა: კოდის დაწერა ცარიელ DataFrame-ზე შეიძლება იყოს დამღლელი და რთული. პანდები საშუალებას გაძლევთ შექმნათ მონაცემები მონაცემთა ამ ტიპებიდან DataFrame კლასზე. აქედან გამომდინარე, მონაცემთა პრიმიტიული ტიპის მონაცემები შეიძლება ადვილად გაანალიზდეს მონაცემთა საჭირო ფორმატში.
ვარიანტი I: სტანდარტული ფორმატი
აქ არის ახსნილი ნებისმიერი ფაილის ფორმატირების სტანდარტული მეთოდი მონაცემთა გარკვეული ფორმატით, როგორიცაა CSV.
Შენიშვნა: აქ, ცვლადი დაასახელა რეზ გამოიყენება შესასრულებლად წაიკითხეთ ფაილში არსებული მონაცემების ფუნქცია data.txt იმპორტირებული პანდების გამოყენებით პდ. შეყვანის ტექსტის მონაცემთა ფორმატი მითითებულია CSV ფორმატი.
ზემოთ ახსნილი პროცესის კოდის მაგალითი მოცემულია ქვემოთ და დაგეხმარებათ გაიგოთ, როგორ გავაანალიზოთ ტექსტი.
პანდების იმპორტი როგორც PDres = pd.read_csv ('data.txt')რეზ
ამ შემთხვევაში, თუ ფაილში შეიყვანთ მონაცემთა მნიშვნელობებს data.txt როგორიცაა [1,2,3], ის იქნება გაანალიზებული და ნაჩვენები როგორც 1 2 3.
ვარიანტი II: სიმებიანი მეთოდი
თუ კოდისთვის მიცემული ტექსტი შეიცავს მხოლოდ სტრიქონებს ან ალფა სიმბოლოებს, სტრიქონის სპეციალური სიმბოლოები, როგორიცაა მძიმეები, ინტერვალი და ა. პროცესი მსგავსია საერთო შიდა სიმებიანი ოპერაციების. იმის გასაგებად, თუ როგორ უნდა გამოასწოროთ ანალიზის შეცდომა, თქვენ უნდა მიჰყვეთ ამ პარამეტრის გამოყენებით ტექსტის გაანალიზების პროცესს, რომელიც აღწერილია ქვემოთ.
მაგალითად, ქვემოთ მოცემულ კოდში, სპეციალური სიმბოლოები სტრიქონში ჩემი_სტრიქონი, რომლებიც არიან, ',"და":“ იდენტიფიცირებულია. ეს პროცესი უნდა გაკეთდეს ფრთხილად, რათა თავიდან იქნას აცილებული შეცდომა ტექსტის გაანალიზებაში x.
მაგალითად, სტრიქონი იყოფა ტექსტურ მონაცემთა მნიშვნელობებად, სპეციალური სიმბოლოების საფუძველზე, რომლებიც იდენტიფიცირებულია გაყოფის ბრძანების გამოყენებით.
ზემოთ ახსნილი პროცესის ნიმუში კოდი მოცემულია ქვემოთ.
my_string = 'სახელები: ტექნიკა, კომპიუტერი'sfinal = [name.strip() სახელისთვის my_string.split(':')[1].split(',')]print (“სახელები: {}”.ფორმატი (ფინალი))
ამ შემთხვევაში, გაანალიზებული სტრიქონის შედეგი ნაჩვენები იქნება, როგორც ნაჩვენებია ქვემოთ.
სახელები: ['ტექნიკა', 'კომპიუტერი']
იმისათვის, რომ მიიღოთ უკეთესი სიცხადე და იცოდეთ როგორ გააანალიზოთ ტექსტი სტრიქონის ტექსტის გამოყენებისას, ა ამისთვის მარყუჟი გამოიყენება და კოდი იცვლება შემდეგნაირად.
my_string = 'სახელები: ტექნიკა, კომპიუტერი's1 = my_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [name.strip() სახელისთვის s3-ში]idx-ისთვის, პუნქტი innumerate-ში ([s1, s2, s3, s4]):print ("ნაბიჯი {}: {}".ფორმატი (idx, ელემენტი))
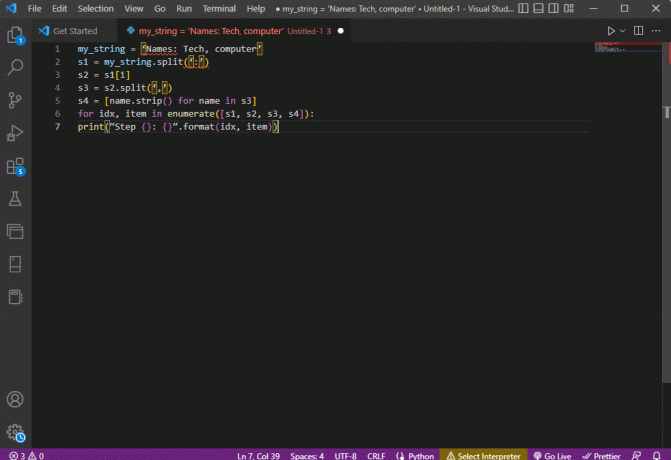
გაანალიზებული ტექსტის შედეგი თითოეული ამ ნაბიჯისთვის ნაჩვენებია ქვემოთ მოცემული სახით. შეგიძლიათ გაითვალისწინოთ, რომ ნაბიჯ 0-ში სტრიქონი გამოყოფილია სპეციალური სიმბოლოს საფუძველზე : და ტექსტის მონაცემების მნიშვნელობები გამოყოფილია სიმბოლოზე დაყრდნობით შემდგომ ნაბიჯებში.
ნაბიჯი 0: [„სახელები“, „ტექნიკა, კომპიუტერი“]ნაბიჯი 1: ტექნიკა, კომპიუტერინაბიჯი 2: ["ტექნიკა", "კომპიუტერი"]ნაბიჯი 3: [„ტექნიკა“, „კომპიუტერი“]
ვარიანტი III: კომპლექსური ფაილის ანალიზი
უმეტეს შემთხვევაში, ფაილის მონაცემები, რომლებიც უნდა გაანალიზდეს, შეიცავს სხვადასხვა ტიპის მონაცემთა ტიპებს და მონაცემთა მნიშვნელობებს. ამ შემთხვევაში, შესაძლოა რთული იყოს ფაილის გაანალიზება ადრე ახსნილი მეთოდების გამოყენებით.
ფაილში რთული მონაცემების ანალიზის თავისებურებებია მონაცემთა მნიშვნელობების ცხრილის ფორმატში ჩვენება.
სანამ ამ მეთოდით ტექსტის ანალიზს ისწავლით, აუცილებელია ვისწავლოთ რამდენიმე ძირითადი კონცეფცია. მონაცემთა მნიშვნელობების ანალიზი ხდება რეგულარული გამონათქვამების ან Regex-ის საფუძველზე.
რეგექსის ნიმუშები
იმისათვის, რომ იცოდეთ როგორ გამოვასწოროთ ანალიზის შეცდომა, უნდა დარწმუნდეთ, რომ გამონათქვამებში რეგექსის შაბლონები სწორია. კოდი სტრიქონების მონაცემთა მნიშვნელობების გასაანალიზებლად მოიცავს ამ განყოფილებაში ქვემოთ ჩამოთვლილ ჩვეულებრივ Regex შაბლონებს.
რეგულარული გამონათქვამები
რეგულარული გამოხატვის მოდულები არის პანდების პაკეტის ძირითადი ნაწილი პითონის ენაზე და არასწორმა ხელახლა შეიძლება გამოიწვიოს შეცდომა ტექსტის ანალიზში x. ეს არის პატარა ენა, რომელიც ჩაშენებულია პითონის შიგნით, რათა იპოვოთ სიმებიანი ნიმუში გამოხატვაში. Regular Expressions ან Regex არის სტრიქონები სპეციალური სინტაქსით. ის მომხმარებელს აძლევს საშუალებას დააკავშიროს შაბლონები სხვა სტრიქონებში, სტრიქონების მნიშვნელობებზე დაყრდნობით.
Regex იქმნება მონაცემთა ტიპისა და სტრიქონში გამოხატვის მოთხოვნის საფუძველზე, როგორიცაა სტრიქონი = (.*)\n. რეგექსი გამოიყენება შაბლონამდე ყველა გამოხატულებაში. რეგულარულ გამონათქვამებში გამოყენებული სიმბოლოები ჩამოთვლილია ქვემოთ და დაგეხმარებათ გაიგოთ, თუ როგორ უნდა გააანალიზოთ ტექსტი.
RegexObjects
RegexObject არის კომპილაციის ფუნქციის დაბრუნების მნიშვნელობა და გამოიყენება MatchObject-ის დასაბრუნებლად, თუ გამოთქმა შეესაბამება შესაბამის მნიშვნელობას.
1. MatchObject
ვინაიდან MatchObject-ის ლოგიკური მნიშვნელობა ყოველთვის True არის, შეგიძლიათ გამოიყენოთ ან თუ განცხადება ობიექტში დადებითი შესატყვისების გამოსავლენად. გამოყენების შემთხვევაში თუ განცხადებაში, ინდექსით მოხსენიებული ჯგუფი გამოიყენება გამოსახულებაში ობიექტის შესატყვისობის გასარკვევად.
2. MatchObject-ის მეთოდები
ტექსტის გაანალიზების ძიებისას მნიშვნელოვანია იცოდეთ, რომ MatchObject-ს აქვს ორი ძირითადი მეთოდი, როგორც ეს მოცემულია ქვემოთ. თუ MatchObject მოიძებნება მითითებულ გამონათქვამში, ის დააბრუნებს თავის მაგალითს, წინააღმდეგ შემთხვევაში, ის დააბრუნებს None-ს.
რეგულარული გამოხატვის ფუნქციები
Regex ფუნქციები არის კოდის ხაზები, რომლებიც გამოიყენება გარკვეული ფუნქციის შესასრულებლად, როგორც მითითებულია მომხმარებლის მიერ შეძენილი მონაცემთა მნიშვნელობების ნაკრებიდან.
Შენიშვნა: ფუნქციების ჩასაწერად, უმი სტრიქონები გამოიყენება რეგულარული გამონათქვამებისთვის, რათა თავიდან იქნას აცილებული შეცდომის გარჩევა x ტექსტში. ეს კეთდება ხელმოწერის დამატებით რ გამოხატვის ყოველი ნიმუშის წინ.
გამონათქვამებში გამოყენებული საერთო ფუნქციები აღწერილია ქვემოთ.
1. re.findall()
ეს ფუნქცია აბრუნებს სტრიქონში არსებულ ყველა შაბლონს, თუ შესატყვისი ნაპოვნია და აბრუნებს ცარიელ სიას, თუ შესატყვისი არ არის ნაპოვნი. მაგალითად, ფუნქცია, string = re.findall('[aeiou]', regex_filename) გამოიყენება ფაილის სახელში ხმოვანთა მნიშვნელობის საპოვნელად.
2. re.split()
ეს ფუნქცია გამოიყენება სტრიქონის გასაყოფად, მითითებულ სიმბოლოსთან შესატყვისობის შემთხვევაში, როგორიცაა ინტერვალის პოვნა. იმ შემთხვევაში, თუ მატჩი არ არის ნაპოვნი, ის აბრუნებს ცარიელ სტრიქონს.
3. re.sub()
ფუნქცია ცვლის შესაბამის ტექსტს მოცემული ჩანაცვლების ცვლადის შინაარსით. სხვა ფუნქციებისგან განსხვავებით, თუ ნიმუში არ არის ნაპოვნი, თავდაპირველი სტრიქონი ბრუნდება.
4. კვლევა()
ერთ-ერთი ძირითადი ფუნქცია, რომელიც დაგეხმარებათ ისწავლოთ ტექსტის გაანალიზება, არის საძიებო ფუნქცია. ის ეხმარება სტრიქონში ნიმუშის ძიებას და შესატყვისი ობიექტის დაბრუნებას. თუ ძიება ვერ ხერხდება დამთხვევის იდენტიფიცირებაში, მნიშვნელობა არ ბრუნდება.
5. ხელახლა შედგენა (ნიმუში)
ეს ფუნქცია გამოიყენება რეგულარული გამოხატვის შაბლონების შედგენისთვის RegexObject-ში, რომელიც ადრე იყო განხილული.
სხვა მოთხოვნები
ჩამოთვლილი მოთხოვნები არის დამატებითი ფუნქცია, რომელსაც იყენებენ მოწინავე პროგრამისტები მონაცემთა ანალიზში.
ასევე წაიკითხეთ:როგორ დააინსტალიროთ NumPy Windows 10-ზე
ტექსტის გარჩევის პროცესი
ამ რთულ ვარიანტში ტექსტის გარჩევის მეთოდი აღწერილია ქვემოთ მოცემული სახით.
ბრძანება მონაცემები = pd. DataFrame (მონაცემები) გამოიყენება პანდების DataFrame-ის შესაქმნელად დიქტალური მნიშვნელობებიდან. ალტერნატიულად, შეგიძლიათ გამოიყენოთ შემდეგი ბრძანებები შესაბამისი მიზნისთვის, როგორც ეს მოცემულია ქვემოთ.
საბოლოო ნაბიჯი იმისათვის, რომ ვიცოდეთ, თუ როგორ უნდა გააანალიზოთ ტექსტი, არის პარსერის ტესტირება თუ განცხადება ცვლადისთვის მნიშვნელობების მინიჭებით მონაცემები და დაბეჭდეთ მისი გამოყენებით ბეჭდვა (მონაცემები) ბრძანება.
ზემოთ მოყვანილი ახსნის კოდის მაგალითი მოცემულია აქ.
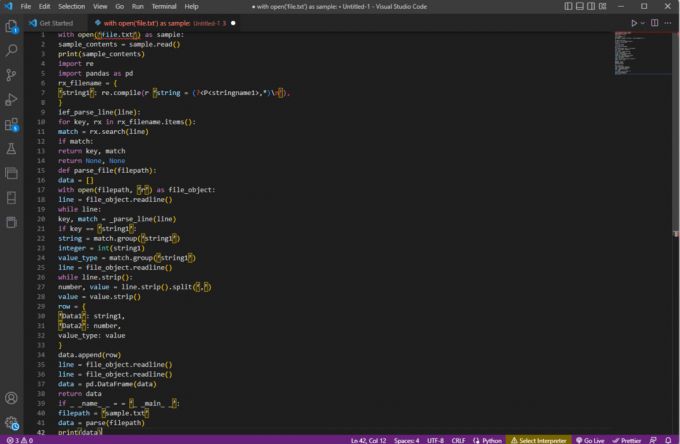
open('file.txt') ნიმუშით:sample_contents = sample.read()ბეჭდვა (sample_contents)იმპორტი რეპანდების იმპორტი როგორც PDrx_filename = {'string1': re.compile (r 'string = (?,*)\n'),
}ief_parse_line (ხაზი):გასაღებისთვის, rx rx_filename.items():match = rx.search (ხაზი)თუ ემთხვევა:დაბრუნების გასაღები, მატჩიდაბრუნება არცერთი, არცერთიdef parse_file (ფაილის გზა):მონაცემები = []ღია (ფაილის გზა, 'r') როგორც file_object:ხაზი = file_object.readline()ხოლო ხაზი:გასაღები, შესატყვისი = _ parse_line (ხაზი)თუ გასაღები == 'string1':string = match.group ('string1')მთელი რიცხვი = int (სტრიქონი 1)value_type = match.group ('string1')ხაზი = file_object.readline()while line.strip():ნომერი, მნიშვნელობა = line.strip().split(',')value = value.strip()რიგი = {'მონაცემები1': string1,"მონაცემები2": ნომერი,value_type: ღირებულება}data.append (სტრიქონი)ხაზი = file_object.readline()ხაზი = file_object.readline()მონაცემები = pd. DataFrame (მონაცემები)მონაცემების დაბრუნებათუ _ _სახელი_ _ = = "_ _მთავარი_ _":filepath = 'sample.txt'მონაცემები = ანალიზი (ფაილის გზა)ბეჭდვა (მონაცემები)
ტექსტის ან კორპუსის ტოკენებად ან უფრო მცირე ნაწილებად გარდაქმნის პროცესს გარკვეული წესების საფუძველზე ეწოდება ტოკენიზაცია. იმის გასაგებად, თუ როგორ უნდა გამოასწოროთ ანალიზის შეცდომა, მნიშვნელოვანია გაანალიზოთ სიტყვის ტოკენიზაციის ბრძანებები კოდში. რეგექსის მსგავსად, ამ მეთოდში შეიძლება შეიქმნას საკუთარი წესები და ის ეხმარება ტექსტის წინასწარ დამუშავების ამოცანებს, როგორიცაა მეტყველების ნაწილების რუქა. ასევე, ამ მეთოდში შესრულებულია ისეთი აქტივობები, როგორიცაა საერთო სიტყვების პოვნა და შესატყვისი, ტექსტის გაწმენდა და მონაცემების მომზადება ტექსტის ანალიტიკური გაფართოებული ტექნიკისთვის, როგორიცაა განწყობის ანალიზი. თუ ტოკენიზაცია არასწორია, შეიძლება მოხდეს შეცდომა ტექსტის ანალიზში x.
NLTK ბიბლიოთეკა
პროცესი იყენებს პოპულარული ენის ინსტრუმენტარიუმის ბიბლიოთეკას, სახელწოდებით NLTK, რომელსაც აქვს ფუნქციების მდიდარი ნაკრები მრავალი NLP სამუშაოს შესასრულებლად. მათი ჩამოტვირთვა შესაძლებელია Pip ან Pip Installs Packages-ით. იმისათვის, რომ იცოდეთ როგორ გააანალიზოთ ტექსტი, შეგიძლიათ გამოიყენოთ Anaconda განაწილების საბაზისო პაკეტი, რომელიც შეიცავს ბიბლიოთეკას ნაგულისხმევად.
ტოკენიზაციის ფორმები
ამ მეთოდის გავრცელებული ფორმებია სიტყვების ტოკენიზაცია და წინადადების ტოკენიზაცია. სიტყვის დონის ნიშნის გამო, პირველი ბეჭდავს ერთ სიტყვას მხოლოდ ერთხელ, ხოლო მეორე ბეჭდავს სიტყვას წინადადების დონეზე.
ტექსტის გარჩევის პროცესი
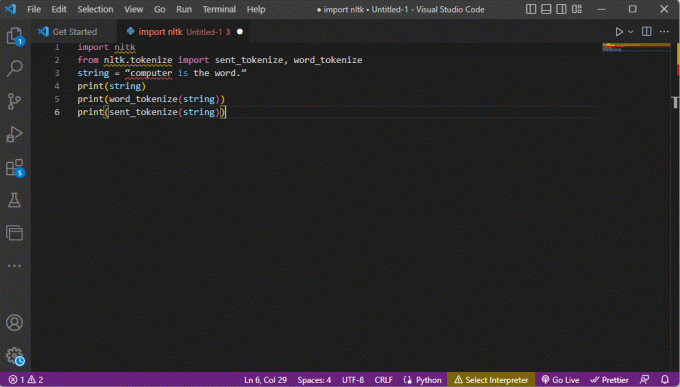
კოდი, რომელიც ხსნის ზემოთ მოყვანილი ტოკენიზაციის ნაბიჯებს, მოცემულია აქ.
იმპორტი nltknltk.tokenize-დან იმპორტი sent_tokenize, word_tokenizestring = "კომპიუტერი არის სიტყვა."ბეჭდვა (სტრიქონი)ბეჭდვა (word_tokenize (სტრიქონი))ბეჭდვა (sent_tokenize (სტრიქონი))
ასევე წაიკითხეთ:როგორ გამოვასწოროთ javascript: void (0) შეცდომა
DataFrame კლასის მსგავსად, Class DocParser შეიძლება გამოყენებულ იქნას კოდის ტექსტის გასაანალიზებლად. კლასი საშუალებას გაძლევთ გამოიძახოთ გარჩევის ფუნქცია ფაილის გზაზე.
ტექსტის გარჩევის პროცესი
იმისათვის, რომ იცოდეთ როგორ გააანალიზოთ ტექსტი DocParser კლასის გამოყენებით, მიჰყევით ქვემოთ მოცემულ ინსტრუქციას.
Შენიშვნა: იმისათვის, რომ იცოდეთ როგორ გამოვასწოროთ ანალიზის შეცდომა, ეს ფუნქცია სწორად უნდა განხორციელდეს.
ტექსტის ანალიზის ინსტრუმენტი გამოიყენება ცვლადებიდან კონკრეტული მონაცემების ამოსაღებად და სხვა ცვლადებზე გადასატანად. ეს დამოუკიდებელია დავალებაში გამოყენებული ნებისმიერი სხვა ხელსაწყოებისგან და BPA Platform ინსტრუმენტი გამოიყენება ცვლადების მოხმარებისა და გამოსატანად. გამოიყენეთ აქ მოცემული ბმული წვდომისთვის Parse Text Tool ონლაინ რეჟიმში და გამოიყენეთ ადრე მოცემული პასუხები ტექსტის გაანალიზების შესახებ.

TextFieldParser იყენებდა ობიექტებს ძალიან დიდი ფაილების გასაანალიზებლად და დასამუშავებლად, რომლებიც სტრუქტურირებული და შემოსაზღვრულია. ტექსტის სიგანე და სვეტი, როგორიცაა ჟურნალის ფაილები ან ძველი მონაცემთა ბაზის ინფორმაცია, შეიძლება გამოყენებულ იქნას ამ მეთოდით. ანალიზების მეთოდი ტექსტურ ფაილზე კოდის გამეორების მსგავსია და ძირითადად გამოიყენება ტექსტის ველების ამოსაღებად, სიმებიანი მანიპულაციის მეთოდების მსგავსი. ეს კეთდება სტრიქონების და სხვადასხვა სიგანის ველების ტოკენიზაციისთვის განსაზღვრული გამიჯვნის გამოყენებით, როგორიცაა მძიმე ან ჩანართის სივრცე.
ფუნქციები ტექსტის გასაანალიზებლად
შემდეგი ფუნქციები შეიძლება გამოყენებულ იქნას ამ მეთოდის ტექსტის გასაანალიზებლად.
MatchObject-ის პოვნის მეთოდები
არსებობს ორი ძირითადი მეთოდი, რომ იპოვოთ MatchObject კოდში ან გაანალიზებულ ტექსტში.
ორივე შემთხვევაში, თუ ველი არ ემთხვევა მითითებულ ფორმატს ანალიზების შესრულებისას ან ტექსტის ანალიზისას, MalformedLineException გამონაკლისი ბრუნდება.
როგორც საბოლოო და მარტივი მეთოდი ტექსტის გასაანალიზებლად, შეგიძლიათ გამოიყენოთ MS Excel აპი, როგორც პარსერი ჩანართებით გამოყოფილი და მძიმით გამოყოფილი ფაილების შესაქმნელად. ეს დაგვეხმარება თქვენი გაანალიზებული შედეგის ჯვარედინი შემოწმებაში და დაგეხმარებათ იპოვოთ ანალიზის შეცდომის გამოსწორება.
1. აირჩიეთ მონაცემთა მნიშვნელობები წყარო ფაილში და დააჭირეთ Ctrl + C კლავიშები ერთად დააკოპირეთ ფაილი.
2. Გააღე Excel აპლიკაცია Windows საძიებო ზოლის გამოყენებით.

3. დააწკაპუნეთ A1 საკანში და დააჭირეთ Ctrl + V კლავიშები კოპირებული ტექსტის ერთდროულად ჩასმა.
4. აირჩიეთ A1 უჯრედში, გადადით მონაცემები ჩანართი და დააწკაპუნეთ ტექსტი სვეტებზე ვარიანტი -ში მონაცემთა ინსტრუმენტები განყოფილება.
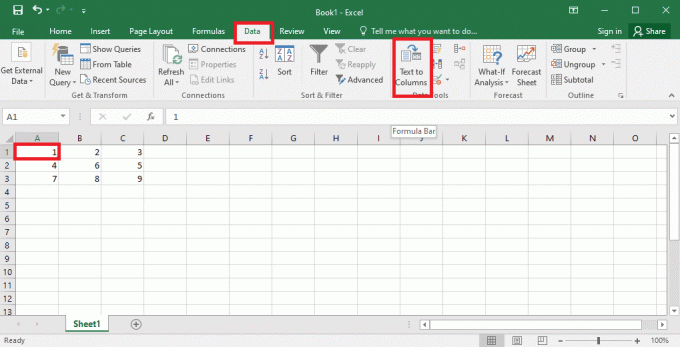
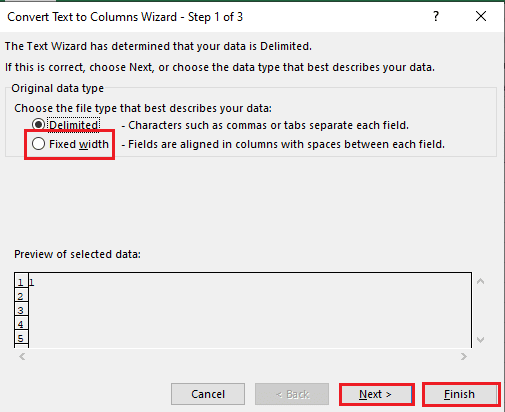
5A. აირჩიეთ შემოსაზღვრული ვარიანტი, თუ ა მძიმით ან ჩანართი სივრცე გამოიყენება როგორც გამყოფი და დააწკაპუნეთ შემდეგი და დასრულება ღილაკები.

5ბ. აირჩიეთ ფიქსირებული სიგანე ვარიანტი, მიანიჭეთ მნიშვნელობა გამყოფისთვის და დააწკაპუნეთ შემდეგი და დასრულება ღილაკები.
ასევე წაიკითხეთ:როგორ დავაფიქსიროთ Move Excel-ის სვეტის შეცდომა
შეცდომა ტექსტის ანალიზში x შეიძლება მოხდეს Android მოწყობილობებზე, როგორც, გარჩევის შეცდომა: მოხდა პაკეტის გარჩევის პრობლემა. ეს ჩვეულებრივ ხდება მაშინ, როდესაც აპი ვერ ინსტალდება Google Play Store-დან ან მესამე მხარის აპის გაშვებისას.
შეცდომის ტექსტი x შეიძლება წარმოიშვას, თუ სიმბოლოთა ვექტორების სია მარყუჟშია და სხვა ფუნქციები ქმნიან ხაზოვან მოდელს მონაცემთა მნიშვნელობების გამოსათვლელად. შეცდომის შეტყობინება არის Error in parse (ტექსტი = x, keep.source = FALSE):
შეგიძლიათ წაიკითხოთ სტატია როგორ დავაფიქსიროთ ანალიზის შეცდომა ანდროიდზე გაეცნონ შეცდომის გამოსწორების მიზეზებსა და მეთოდებს.
სახელმძღვანელოში მოცემული გადაწყვეტილებების გარდა, შეგიძლიათ სცადოთ შემდეგი გამოსწორებები.
რეკომენდებულია:
სტატია გვეხმარება სწავლებაში როგორ გავაანალიზოთ ტექსტი და ვისწავლოთ როგორ გამოვასწოროთ ანალიზის შეცდომა. შეგვატყობინეთ, რომელი მეთოდი დაეხმარა შეცდომის გამოსწორებას ტექსტში x-ში და ანალიზის რომელი მეთოდია სასურველი. გთხოვთ, გააზიაროთ თქვენი წინადადებები და შეკითხვები ქვემოთ მოცემულ კომენტარებში.