
0
Skati

Ja esat apguvis dažas datorprogrammēšanas valodas, iespējams, esat dzirdējis terminu teksta parsēšana. To izmanto, lai vienkāršotu faila sarežģītās datu vērtības. Šis raksts palīdz jums uzzināt, kā parsēt tekstu, izmantojot valodu. Turklāt, ja esat saskāries ar kļūdu parsēšanas tekstā x, jūs zināt, kā rakstā labot parsēšanas kļūdu.
Satura rādītājs
Šajā rakstā mēs esam parādījuši pilnu rokasgrāmatu teksta parsēšanai dažādos veidos, kā arī īsi iepazīstinājām ar teksta parsēšanu.
Pirms iedziļināties, lai uzzinātu teksta parsēšanas jēdzienus, izmantojot jebkuru kodu. Ir svarīgi zināt valodas un kodēšanas pamatus.
Teksta parsēšanai tiek izmantota dabiskās valodas apstrāde vai NLP, kas ir mākslīgā intelekta domēna apakšlauks. Python valoda, kas ir viena no valodām, kas pieder šai kategorijai, tiek izmantota teksta parsēšanai.
NLP kodi ļauj datoriem saprast un apstrādāt cilvēku valodas, lai padarītu tos piemērotus dažādām lietojumprogrammām. Lai lietotu valodai ML vai mašīnmācīšanās paņēmienus, nestrukturētie teksta dati ir jāpārvērš strukturētos tabulas datos. Lai pabeigtu parsēšanas darbību, programmu kodu mainīšanai tiek izmantota Python valoda.
Teksta parsēšana vienkārši nozīmē datu konvertēšanu no viena formāta citā formātā. Faila saglabāšanas formātu parsē vai pārveido par failu citā formātā, lai lietotājs varētu to izmantot dažādās lietojumprogrammās.
Iemesli, kādēļ teksts ir jāparsē, ir norādīti šajā sadaļā, un tās ir priekšnosacījuma zināšanas, pirms zināt, kā parsēt tekstu.
Python valodas DataFrame klasei ir visas nepieciešamās funkcijas teksta parsēšanai. Šajā iebūvētajā bibliotēkā ir nepieciešamie kodi, lai parsētu jebkura formāta datus citā formātā.
Īss ievads par DataFrame klasi
DataFrame Class ir ar funkcijām bagāta datu struktūra, kas tiek izmantota kā datu analīzes rīks. Šis ir spēcīgs datu analīzes rīks, ko var izmantot, lai analizētu datus ar minimālu piepūli.
Python valodas pandas palīdz veikt SQL vai datu bāzes stila darbības ar vislielāko pilnību, lai izvairītos no kļūdām teksta parsēšanā x. Tajā ir arī daži IO rīki, kas palīdz analizēt CSV, MS Excel, JSON, HDF5 un citu datu formātu failus.
Lasi arī:Izlabojiet kļūdu, kas radās, mēģinot pieprasīt starpniekserveri
Teksta parsēšanas process, izmantojot DataFrame klasi
Lai zinātu, kā parsēt tekstu, varat izmantot standarta procesu, izmantojot šajā sadaļā norādīto DataFrame klasi.
Piezīme: Koda rakstīšana tukšā DataFrame var būt garlaicīga un sarežģīta. Pandas ļauj izveidot datus DataFrame klasē no šiem datu tipiem. Tādējādi primitīvā datu tipa datus var viegli parsēt vajadzīgajā datu formātā.
I iespēja: standarta formāts
Šeit ir izskaidrota standarta metode jebkura faila formatēšanai ar noteiktu datu formātu, piemēram, CSV.
Piezīme: Šeit tiek nosaukts mainīgais res tiek izmantots, lai veiktu lasīt failā esošo datu funkcija data.txt izmantojot ievestās pandas pd. Ievadītā teksta datu formāts ir norādīts CSV formātā.
Tālāk ir sniegts iepriekš aprakstītā procesa koda piemērs, kas palīdzēs saprast, kā parsēt tekstu.
importēt pandas kā pdres = pd.read_csv('data.txt')res
Šajā gadījumā, ja failā ievadāt datu vērtības data.txt piemēram, [1,2,3], tas tiks parsēts un parādīts kā 1 2 3.
II iespēja: virknes metode
Ja kodam dotajā tekstā ir tikai virknes vai alfa rakstzīmes, teksta atdalīšanai un parsēšanai var izmantot virknes īpašās rakstzīmes, piemēram, komatus, atstarpes utt. Process ir līdzīgs parastajām iekšējām virkņu operācijām. Lai uzzinātu, kā novērst parsēšanas kļūdu, jums ir jāseko teksta parsēšanas procesam, izmantojot šo opciju, kas ir izskaidrota tālāk.
Piemēram, tālāk norādītajā kodā virknes īpašās rakstzīmes my_string, kuri ir, ',' un ':' ir identificēti. Šis process ir jāveic uzmanīgi, lai izvairītos no kļūdām parsēšanas tekstā x.
Piemēram, virkne tiek sadalīta teksta datu vērtībās, pamatojoties uz īpašajām rakstzīmēm, kas identificētas, izmantojot sadalīšanas komandu.
Iepriekš aprakstītā procesa parauga kods ir norādīts tālāk.
my_string = 'Vārdi: Tehnika, dators'sfinal = [nosaukums.josla() vārdam my_string.split(':')[1].split(',')]drukāt (“Vārdi: {}”. formāts (galīgais))
Šajā gadījumā parsētās virknes rezultāts tiks parādīts, kā parādīts tālāk.
Vārdi: ['Tech', 'computer']
Lai iegūtu labāku skaidrību un zinātu, kā parsēt tekstu, izmantojot virknes tekstu, a priekš tiek izmantota cilpa un kods tiek modificēts šādi.
my_string = 'Vārdi: Tehnika, dators's1 = my_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [nosaukums.josla() vārdam s3]idx, vienums sarakstā ([s1, s2, s3, s4]):drukāt ("Step {}: {}".formāts (idx, vienums))
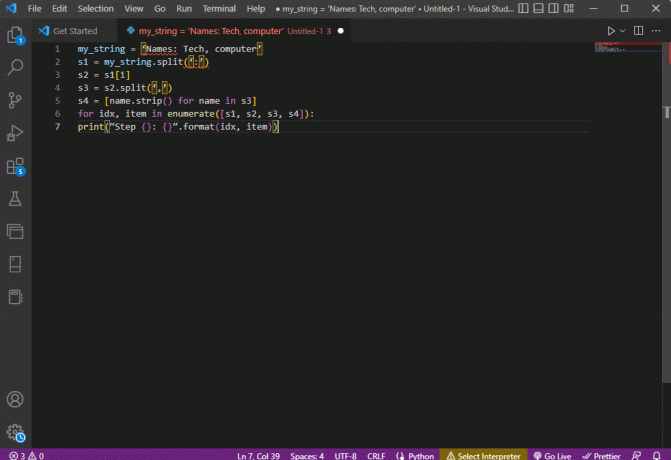
Parsētā teksta rezultāts katrai no šīm darbībām tiek parādīts, kā norādīts tālāk. Varat atzīmēt, ka 0. darbībā virkne tiek atdalīta, pamatojoties uz īpašo rakstzīmi : un teksta datu vērtības turpmākajās darbībās tiek atdalītas atkarībā no rakstzīmes.
0. darbība: [“Vārdi”, “Tehnika, dators”]1. darbība: tehnika, dators2. darbība: [“Tehnika”, “Dators”]3. darbība: [“Tehnika”, “dators”]
III iespēja: kompleksā faila parsēšana
Vairumā gadījumu faila dati, kas ir jāparsē, satur dažādus datu tipus un datu vērtības. Šādā gadījumā var būt grūti parsēt failu, izmantojot iepriekš aprakstītās metodes.
Sarežģīto datu parsēšana failā ir tāda, lai datu vērtības tiktu parādītas tabulas formātā.
Pirms iedziļināties tajā, kā mācīties parsēt tekstu, izmantojot šo metodi, ir jāapgūst daži pamatjēdzieni. Datu vērtību parsēšana tiek veikta, pamatojoties uz regulārām izteiksmēm vai Regex.
Regex modeļi
Lai zinātu, kā labot parsēšanas kļūdu, jums ir jānodrošina, ka izteiksmēs ir pareizie regex modeļi. Virkņu datu vērtību parsēšanas kods ietvers vispārīgos Regex modeļus, kas norādīti tālāk šajā sadaļā.
Regulāras izteiksmes
Regulārās izteiksmes moduļi ir galvenā pandas pakotnes daļa Python valodā, un nepareiza re var izraisīt kļūdu teksta parsēšanā x. Tā ir maza valoda, kas ir iegulta Python, lai atrastu virknes modeli izteiksmē. Regulārās izteiksmes jeb Regex ir virknes ar īpašu sintaksi. Tas ļauj lietotājam saskaņot modeļus citās virknēs, pamatojoties uz virkņu vērtībām.
Regex tiek izveidots, pamatojoties uz datu tipu un izteiksmes prasību virknē, piemēram, Virkne = (.*)\n. Regulāro izteiksmi izmanto pirms modeļa katrā izteiksmē. Regulārajās izteiksmēs izmantotie simboli ir uzskaitīti zemāk, un tie palīdzēs uzzināt, kā parsēt tekstu.
RegexObjects
RegexObject ir kompilēšanas funkcijas atgriešanas vērtība, un to izmanto, lai atgrieztu MatchObject, ja izteiksme atbilst atbilstības vērtībai.
1. MatchObject
Tā kā MatchObject Būla vērtība vienmēr ir True, varat izmantot an ja paziņojums, lai identificētu pozitīvās atbilstības objektā. Gadījumā, ja tiek izmantots ja apgalvojumu, indeksa norādītā grupa tiek izmantota, lai noskaidrotu objekta atbilstību izteiksmē.
2. MatchObject metodes
Meklējot, kā parsēt tekstu, ir svarīgi zināt, ka MatchObject ir divas tālāk norādītās pamatmetodes. Ja norādītajā izteiksmē tiek atrasts MatchObject, tas atgrieztu savu gadījumu, pretējā gadījumā tas atgrieztu Nav.
Regulārās izteiksmes funkcijas
Regex funkcijas ir koda rindas, kas tiek izmantotas, lai veiktu noteiktu funkciju, ko norādījis lietotājs no iegūto datu vērtību kopas.
Piezīme: Lai rakstītu funkcijas, regulārajām izteiksmēm tiek izmantotas neapstrādātas virknes, lai izvairītos no kļūdām parsēšanas tekstā x. Tas tiek darīts, pievienojot apakšindeksu r pirms katra izteiksmes modeļa.
Izteiksmēs izmantotās kopīgās funkcijas ir izskaidrotas tālāk.
1. re.findall()
Šī funkcija atgriež visus virknes modeļus, ja tiek atrasta atbilstība, un atgriež tukšu sarakstu, ja atbilstība netiek atrasta. Piemēram, funkcija, virkne = re.findall('[aeiou]', regex_filename) tiek izmantots, lai atrastu patskaņu sastopamību faila nosaukumā.
2. re.split()
Šī funkcija tiek izmantota, lai sadalītu virkni, ja tiek atrasta atbilstība norādītajai rakstzīmei, piemēram, atstarpe. Ja atbilstība netiek atrasta, tā atgriež tukšu virkni.
3. re.sub()
Funkcija aizstāj atbilstošo tekstu ar norādītā aizstājamā mainīgā saturu. Pretēji citām funkcijām, ja modelis netiek atrasts, tiek atgriezta sākotnējā virkne.
4. re.search()
Viena no pamatfunkcijām, kas palīdz mācīties parsēt tekstu, ir meklēšanas funkcija. Tas palīdz meklēt rakstu virknē un atgriezt atbilstības objektu. Ja meklēšana neizdodas noteikt atbilstību, vērtība netiek atgriezta.
5. re.compile (raksts)
Šī funkcija tiek izmantota, lai apkopotu regulārās izteiksmes modeļus RegexObject, kas tika apspriests iepriekš.
Citas prasības
Norādītās prasības ir papildu līdzeklis, ko izmanto progresīvi programmētāji datu analīzē.
Lasi arī:Kā instalēt NumPy operētājsistēmā Windows 10
Teksta parsēšanas process
Teksta parsēšanas metode šajā sarežģītajā opcijā ir aprakstīta tālāk.
Komanda dati = pd. DataFrame (dati) tiek izmantots, lai izveidotu pandas DataFrame no diktētajām vērtībām. Varat arī izmantot tālāk norādītās komandas attiecīgajam mērķim, kā norādīts tālāk.
Pēdējais solis, lai uzzinātu, kā parsēt tekstu, ir pārbaudīt parsētāju, izmantojot ja paziņojums piešķirot vērtības mainīgajam datus un izdrukājot to, izmantojot drukāt (dati) komandu.
Šeit ir sniegts iepriekš minētā skaidrojuma koda piemērs.
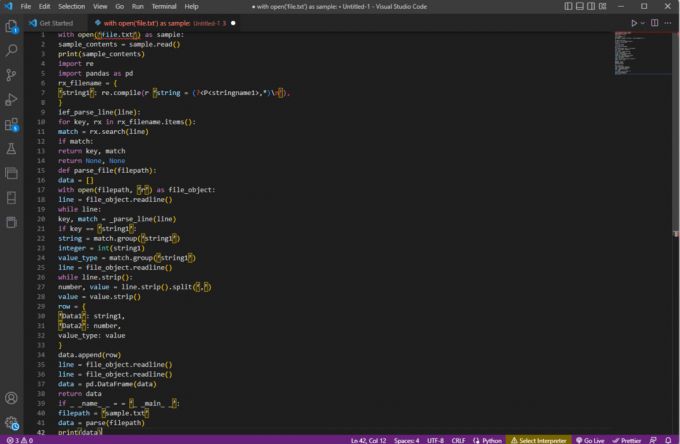
ar open ('file.txt') kā paraugu:sample_contents = paraugs.lasīt()drukāt (sample_contents)importa reimportēt pandas kā pdrx_faila nosaukums = {‘string1’: re.compile (r ‘virkne = (?,*)\n’),
}ief_parse_line (rinda):atslēgai rx failā rx_filename.items ():atbilstība = rx.search (rindiņa)ja atbilst:atgriešanas atslēga, spēleatgriezties Nav, Navdef parse_file (faila ceļš):dati = []ar atvērtu (filepath, “r”) kā file_object:rinda = file_object.readline()kamēr līnija:atslēga, atbilstība = _parse_line (rinda)ja atslēga == ‘string1’:virkne = match.group('virkne1')vesels skaitlis = int (string1)value_type = match.group('virkne1')rinda = file_object.readline()while line.strip():skaitlis, vērtība = line.strip().split(',')vērtība = value.strip()rinda = {“Dati1”: virkne1,“Dati2”: numurs,value_type: vērtība}data.append (rinda)rinda = file_object.readline()rinda = file_object.readline()dati = pd. DataFrame (dati)atgriezt datusja _ _name_ _ = = '_ _main_ _':filepath = 'sample.txt'dati = parsēt (faila ceļš)drukāt (dati)
Teksta vai korpusa konvertēšanas procesu marķieros vai mazākās daļās, pamatojoties uz noteiktiem noteikumiem, sauc par marķieri. Lai uzzinātu, kā novērst parsēšanas kļūdu, ir svarīgi analizēt vārdu marķierizācijas komandas kodā. Līdzīgi kā regulārajā izteiksmē, ar šo metodi var izveidot savus noteikumus, un tas palīdz teksta pirmapstrādes uzdevumos, piemēram, runas daļu kartēšanā. Izmantojot šo metodi, tiek veiktas arī tādas darbības kā parastu vārdu meklēšana un atbilstības noteikšana, teksta tīrīšana un datu sagatavošana uzlabotām teksta analīzes metodēm, piemēram, noskaņojuma analīzei. Ja marķieris ir nepareizs, var rasties kļūda parsēšanas tekstā x.
NLTK bibliotēka
Šajā procesā tiek izmantota populārā valodu rīku komplekta bibliotēka ar nosaukumu NLTK, kurai ir bagātīgs funkciju kopums daudzu NLP darbu veikšanai. Tos var lejupielādēt, izmantojot Pip vai Pip instalēšanas pakotnes. Lai zinātu, kā parsēt tekstu, varat izmantot Anaconda izplatīšanas bāzes pakotni, kurā pēc noklusējuma ir iekļauta bibliotēka.
Tokenizācijas formas
Šīs metodes izplatītās formas ir vārdu marķieris un teikuma marķieris. Vārda līmeņa marķiera dēļ pirmais drukā vienu vārdu tikai vienu reizi, bet otrais vārdu drukā teikuma līmenī.
Teksta parsēšanas process
Šeit ir norādīts kods, kas izskaidro iepriekš norādītās marķiera darbības darbības.
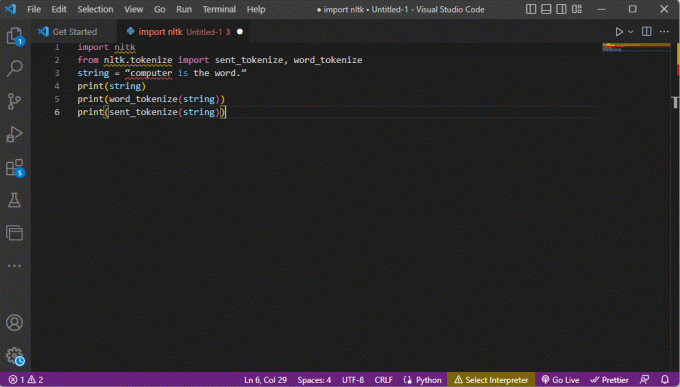
importēt nltkno nltk.tokenize importēt send_tokenize, word_tokenizestring = “dators ir vārds”.drukāt (virkne)drukāt (word_tokenize (string))drukāt (nosūtīts_tokenizēt (virkne))
Lasi arī:Kā labot javascript: void (0) Error
Līdzīgi kā DataFrame klasē, klases DocParser var izmantot, lai parsētu tekstu kodā. Klase ļauj izsaukt parsēšanas funkciju ar faila ceļu.
Teksta parsēšanas process
Lai uzzinātu, kā parsēt tekstu, izmantojot DocParser klasi, izpildiet tālāk sniegtos norādījumus.
Piezīme: Lai zinātu, kā novērst parsēšanas kļūdu, šī funkcija ir jāīsteno pareizi.
Teksta parsēšanas rīku izmanto, lai no mainīgajiem iegūtu konkrētus datus un kartētu tos ar citiem mainīgajiem. Tas nav atkarīgs no citiem uzdevumā izmantotajiem rīkiem, un BPA platformas rīks tiek izmantots, lai patērētu un izvadītu mainīgos. Izmantojiet šeit sniegto saiti, lai piekļūtu Parsēt teksta rīku tiešsaistē un izmantojiet iepriekš sniegtās atbildes par teksta parsēšanu.

TextFieldParser izmantoja objektus, lai parsētu un apstrādātu ļoti lielus strukturētus un norobežotus failus. Šajā metodē var izmantot teksta platumu un kolonnu, piemēram, žurnālfailus vai mantotās datu bāzes informāciju. Parsēšanas metode ir līdzīga koda atkārtošanai teksta failā, un to galvenokārt izmanto, lai iegūtu teksta laukus, kas līdzīgi virkņu manipulācijas metodēm. Tas tiek darīts, lai marķierizētu norobežotas virknes un dažāda platuma laukus, izmantojot definēto atdalītāju, piemēram, komatu vai tabulēšanas atstarpi.
Funkcijas teksta parsēšanai
Lai parsētu tekstu, izmantojot šo metodi, var izmantot šādas funkcijas.
Metodes MatchObject atrašanai
Ir divas pamatmetodes, lai kodā vai parsētajā tekstā atrastu MatchObject.
Jebkurā gadījumā, ja lauks neatbilst norādītajam formātam, veicot parsēšanu vai meklējot, kā parsēt tekstu, MalformedLineException izņēmums tiek atgriezts.
Kā pēdējo un vienkāršu metodi teksta parsēšanai varat izmantot MS Excel lietotni kā parsētāju, lai izveidotu ar tabulēšanu atdalītus un ar komatu atdalītus failus. Tas palīdzētu salīdzināt parsēto rezultātu un palīdzētu atrast parsēšanas kļūdu.
1. Atlasiet datu vērtības avota failā un nospiediet Ctrl + C taustiņi kopā, lai kopētu failu.
2. Atveriet Excel lietotni, izmantojot Windows meklēšanas joslu.

3. Noklikšķiniet uz A1 šūnu un nospiediet Ctrl + V taustiņi vienlaikus, lai ielīmētu nokopēto tekstu.
4. Izvēlieties A1 šūnu, dodieties uz Dati cilni un noklikšķiniet uz Teksts uz kolonnām opcija sadaļā Datu rīki sadaļā.
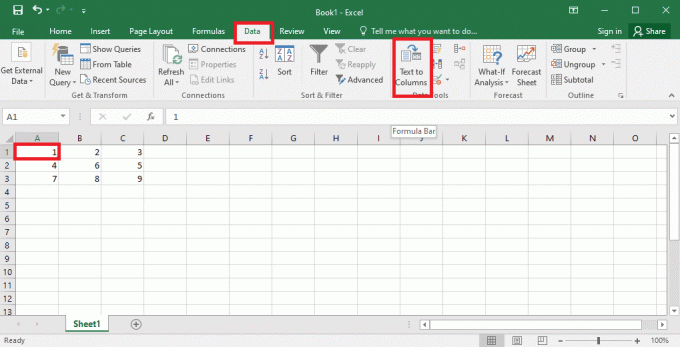
5A. Izvēlieties Norobežots variants, ja a komats vai cilne atstarpe tiek izmantota kā atdalītājs, un noklikšķiniet uz Nākamais un Pabeigt pogas.

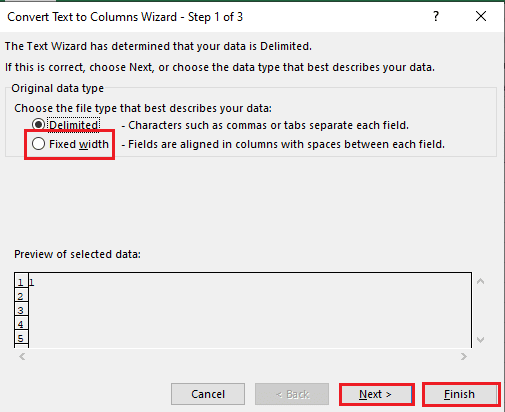
5B. Izvēlieties Fiksēts platums opciju, piešķiriet atdalītājam vērtību un noklikšķiniet uz Nākamais un Pabeigt pogas.
Lasi arī:Kā labot Move Excel kolonnas kļūdu
Kļūda parsēšanas tekstā x var rasties Android ierīcēs, piemēram, Parsēšanas kļūda: parsējot pakotni, radās problēma. Tas parasti notiek, ja lietotni neizdodas instalēt no Google Play veikala vai palaižot trešās puses lietotni.
Kļūdas teksts x var rasties, ja rakstzīmju vektoru saraksts ir cilpas un citas funkcijas veido lineāru modeli datu vērtību aprēķināšanai. Kļūdas ziņojums ir Error in parse (teksts = x, keep.source = FALSE):
Jūs varat izlasīt rakstu par kā novērst parsēšanas kļūdu operētājsistēmā Android lai uzzinātu kļūdas cēloņus un metodes, kā novērst kļūdu.
Papildus ceļvedī sniegtajiem risinājumiem varat izmēģināt tālāk norādītos labojumus.
Ieteicams:
Raksts palīdz mācībās kā parsēt tekstu un uzzināt, kā novērst parsēšanas kļūdu. Pastāstiet mums, kura metode palīdzēja novērst kļūdu parsēšanas tekstā x un kura parsēšanas metode ir ieteicama. Lūdzu, kopīgojiet savus ieteikumus un jautājumus tālāk esošajā komentāru sadaļā.

