
0
Keer bekeken

Als je een paar computerprogrammeertalen hebt geleerd, heb je misschien de term 'tekst ontleden' gehoord. Dit wordt gebruikt om de complexe gegevenswaarden van het bestand te vereenvoudigen. Het artikel helpt u te weten hoe u tekst kunt ontleden met behulp van de taal. Bovendien, als u een fout tegenkomt bij het parseren van tekst x, weet u hoe u de parseerfout in het artikel kunt oplossen.
Inhoudsopgave
In dit artikel hebben we een volledige gids getoond om tekst op verschillende manieren te ontleden en hebben we ook een korte inleiding gegeven tot het ontleden van tekst.
Voordat u zich gaat verdiepen, leert u de concepten van het ontleden van tekst met behulp van welke code dan ook. Het is belangrijk om de basisprincipes van de taal en de codering te kennen.
Om tekst te ontleden, wordt natuurlijke taalverwerking of NLP gebruikt, een subveld van het domein van kunstmatige intelligentie. Python-taal, een van de talen die tot de categorie behoren, wordt gebruikt om tekst te ontleden.
De NLP-codes stellen computers in staat menselijke talen te begrijpen en te verwerken om ze geschikt te maken voor verschillende toepassingen. Om ML- of Machine Learning-technieken op de taal toe te passen, moeten de ongestructureerde tekstgegevens worden omgezet in gestructureerde tabelgegevens. Voor het voltooien van de parseeractiviteit wordt de Python-taal gebruikt om de programmacodes te wijzigen.
Het ontleden van tekst betekent simpelweg het converteren van de gegevens van het ene formaat naar het andere formaat. Het formaat waarin het bestand is opgeslagen, wordt geparseerd of geconverteerd naar een bestand in een ander formaat, zodat de gebruiker het in verschillende toepassingen kan gebruiken.
De redenen waarom de tekst moet worden geparseerd, worden in deze sectie gegeven en het is een vereiste kennis voordat u weet hoe u tekst moet parseren.
De DataFrame-klasse van de Python-taal heeft alle vereiste functies om tekst te ontleden. Deze ingebouwde bibliotheek bevat de nodige codes om gegevens van elk formaat naar een ander formaat te ontleden.
Korte introductie van de DataFrame-klasse
DataFrame Class is een feature-rijke datastructuur, die wordt gebruikt als een data-analysetool. Dit is een krachtige tool voor gegevensanalyse die kan worden gebruikt om gegevens met minimale inspanning te analyseren.
De panda's van de Python-taal helpen bij het uitvoeren van de SQL- of database-achtige bewerkingen met de grootst mogelijke perfectie om fouten bij het ontleden van tekst x te voorkomen. Het bevat ook enkele IO-tools die helpen bij het analyseren van de bestanden van CSV, MS Excel, JSON, HDF5 en andere gegevensindelingen.
Lees ook:Fix Er is een fout opgetreden tijdens het proberen om een proxyverzoek in te dienen
Proces van het parseren van tekst met behulp van DataFrame Class
Om te weten hoe u tekst moet ontleden, kunt u het standaardproces gebruiken met behulp van de DataFrame-klasse die in deze sectie wordt gegeven.
Opmerking: Het schrijven van de code op een leeg DataFrame kan vervelend en complex zijn. Met de panda's kunnen de gegevens op de DataFrame-klasse worden gemaakt op basis van deze gegevenstypen. Daarom kunnen de gegevens in het primitieve gegevenstype eenvoudig worden geparseerd naar het vereiste gegevensformaat.
Optie I: Standaard Formaat
De standaardmethode om elk bestand op te maken met een bepaald gegevensformaat, zoals CSV, wordt hier uitgelegd.
Opmerking: Hier, de variabele met de naam res wordt gebruikt om de lezen functie van de gegevens in het bestand gegevens.txt met de geïmporteerde panda's pd. Het gegevensformaat van de ingevoerde tekst wordt gespecificeerd in de CSV formaat.
Een voorbeeldcode voor het hierboven beschreven proces wordt hieronder gegeven en zal helpen bij het begrijpen van het ontleden van tekst.
importeer panda's als pdres = pd.read_csv(‘data.txt’)res
In dit geval, als u de gegevenswaarden in het bestand invoert gegevens.txt zoals [1,2,3], zou het worden geparseerd en weergegeven als 1 2 3.
Optie II: String-methode
Als de tekst die aan de code wordt gegeven alleen tekenreeksen of alfatekens bevat, kunnen de speciale tekens in de tekenreeks, zoals komma's, spatie, enz., worden gebruikt om de tekst te scheiden en te ontleden. Het proces is vergelijkbaar met de gewone interne tekenreeksbewerkingen. Om erachter te komen hoe u de parseerfout kunt oplossen, moet u het proces volgen van het parseren van de tekst met behulp van deze optie, die hieronder wordt uitgelegd.
Bijvoorbeeld, in de onderstaande code, de speciale tekens in de string mijn_tekenreeks, welke zijn, ',' En ':’ worden geïdentificeerd. Dit proces moet zorgvuldig worden uitgevoerd om fouten bij het ontleden van tekst x te voorkomen.
De tekenreeks wordt bijvoorbeeld opgesplitst in tekstgegevenswaarden op basis van de speciale tekens die zijn geïdentificeerd met behulp van de opdracht splitsen.
De voorbeeldcode voor het hierboven beschreven proces wordt hieronder weergegeven.
my_string = 'Namen: Tech, computer'sfinal = [name.strip() voor naam in my_string.split(‘:’)[1].split(‘,’)]print(“Namen: {}”.format (sfinal))
In dit geval wordt het resultaat van de geparseerde tekenreeks weergegeven zoals hieronder weergegeven.
Namen: [‘Tech’, ‘computer’]
Om meer duidelijkheid te krijgen en te weten hoe tekst moet worden geparseerd terwijl u de tekenreekstekst gebruikt, a voor lus wordt gebruikt en de code wordt als volgt gewijzigd.
my_string = 'Namen: Tech, computer's1 = mijn_string.split(‘:’)s2 = s1[1]s3 = s2.split(‘,’)s4 = [name.strip() voor naam in s3]voor idx, item in opsommen([s1, s2, s3, s4]):print(“Stap {}: {}”.format (idx, item))
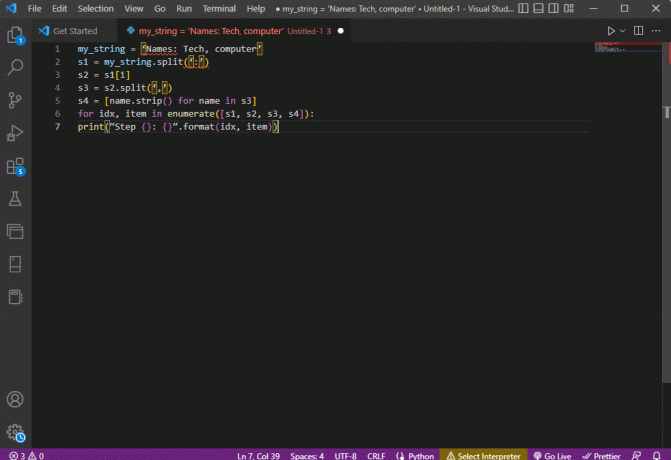
Het resultaat van de geparseerde tekst voor elk van deze stappen wordt weergegeven zoals hieronder weergegeven. U kunt opmerken dat in stap 0 de tekenreeks wordt gescheiden op basis van het speciale teken : en de tekstgegevenswaarden worden gescheiden op basis van het teken in verdere stappen.
Stap 0: [‘Namen’, ‘Tech, computer’]Stap 1: Technologie, computerStap 2: [‘ Tech’, ‘ computer’]Stap 3: [‘Tech’, ‘computer’]
Optie III: Complex bestand parseren
In de meeste gevallen bevatten de bestandsgegevens die moeten worden geparseerd verschillende gegevenstypen en gegevenswaarden. In dit geval kan het moeilijk zijn om het bestand te ontleden met de eerder beschreven methoden.
De kenmerken van het ontleden van de complexe gegevens in het bestand zijn ervoor te zorgen dat de gegevenswaarden in tabelvorm worden weergegeven.
Voordat we ons verdiepen in het leren ontleden van tekst in deze methode, is het noodzakelijk om een paar basisconcepten te leren. Het ontleden van de gegevenswaarden gebeurt op basis van reguliere expressies of Regex.
Regex-patronen
Om te weten hoe u parseerfouten kunt oplossen, moet u ervoor zorgen dat de regex-patronen in de uitdrukkingen juist zijn. De code om de gegevenswaarden van de tekenreeksen te ontleden, omvat de algemene Regex-patronen die hieronder in deze sectie worden vermeld.
Normale uitdrukkingen
Reguliere expressiemodules vormen een belangrijk onderdeel van het panda-pakket in de Python-taal en een verkeerde re kan leiden tot een fout bij het ontleden van tekst x. Het is een kleine taal die in Python is ingebed om het tekenreekspatroon in de uitdrukking te vinden. Reguliere expressies of regex zijn tekenreeksen met een speciale syntaxis. Hiermee kan de gebruiker patronen in andere tekenreeksen matchen op basis van de waarden in de tekenreeksen.
De Regex wordt gemaakt op basis van het gegevenstype en de vereiste van de uitdrukking in de tekenreeks, zoals Tekenreeks = (.*)\n. De regex wordt in elke expressie vóór het patroon gebruikt. De symbolen die in de reguliere expressies worden gebruikt, worden hieronder vermeld en helpen u te weten hoe u tekst moet ontleden.
RegexObjecten
Het RegexObject is een retourwaarde voor de compileerfunctie en wordt gebruikt om een MatchObject te retourneren als de expressie overeenkomt met de matchwaarde.
1. MatchObject
Aangezien de Booleaanse waarde van het MatchObject altijd True is, kunt u een als instructie om de positieve overeenkomsten in het object te identificeren. In het geval van het gebruik van de als instructie, wordt de groep waarnaar wordt verwezen door de index gebruikt om de overeenkomst van het object in de uitdrukking te achterhalen.
2. Methoden van MatchObject
Terwijl u zoekt naar het ontleden van tekst, is het belangrijk om te weten dat het MatchObject twee basismethoden heeft, zoals hieronder vermeld. Als het MatchObject wordt gevonden in de opgegeven expressie, retourneert het zijn instantie, anders retourneert het geen.
Functies voor reguliere expressies
Regex-functies zijn coderegels die worden gebruikt om een bepaalde functie uit te voeren zoals gespecificeerd door de gebruiker uit de set gegevenswaarden die is verkregen.
Opmerking: Om de functies te schrijven, worden onbewerkte tekenreeksen gebruikt voor de reguliere expressies om fouten bij het ontleden van tekst x te voorkomen. Dit wordt gedaan door het subscript toe te voegen R vóór elk patroon in de uitdrukking.
De algemene functies die in de expressies worden gebruikt, worden hieronder uitgelegd.
1. re.findall()
Deze functie retourneert alle patronen in de tekenreeks als er een overeenkomst is gevonden en retourneert een lege lijst als er geen overeenkomst is gevonden. Bijvoorbeeld de functie, tekenreeks = re.findall(‘[aeiou]’, regex_bestandsnaam) wordt gebruikt om de klinker in de bestandsnaam te vinden.
2. opnieuw.split()
Deze functie wordt gebruikt om de tekenreeks te splitsen in het geval dat er een overeenkomst wordt gevonden met een opgegeven teken, zoals een spatie. Als er geen overeenkomst wordt gevonden, wordt een lege string geretourneerd.
3. re.sub()
De functie vervangt de overeenkomende tekst door de inhoud van de gegeven vervangvariabele. In tegenstelling tot andere functies, wordt de oorspronkelijke tekenreeks geretourneerd als er geen patroon wordt gevonden.
4. onderzoek()
Een van de basisfuncties om te helpen bij het leren ontleden van tekst is de zoekfunctie. Het helpt bij het zoeken naar het patroon in de string en het retourneren van het match-object. Als de zoekopdracht de overeenkomst niet kan identificeren, wordt er geen waarde geretourneerd.
5. opnieuw compileren (patroon)
Deze functie wordt gebruikt om patronen voor reguliere expressies te compileren in een RegexObject, wat eerder is besproken.
Andere vereisten
De vermelde vereisten zijn een extra functie die door geavanceerde programmeurs wordt gebruikt bij gegevensanalyse.
Lees ook:Hoe NumPy op Windows 10 te installeren
Proces van het ontleden van tekst
De methode om de tekst in deze complexe optie te ontleden wordt hieronder beschreven.
Het bevel gegevens = pd. DataFrame (gegevens) wordt gebruikt om een Panda's DataFrame te maken op basis van de dict-waarden. Als alternatief kunt u de volgende opdrachten gebruiken voor het respectievelijke doel, zoals hieronder vermeld.
De laatste stap om te weten hoe tekst moet worden geparseerd, is het testen van de parser met behulp van de als verklaring door de waarden toe te wijzen aan een variabele gegevens en afdrukken met behulp van de afdrukken (gegevens) commando.
De voorbeeldcode voor de uitleg hierboven wordt hier gegeven.
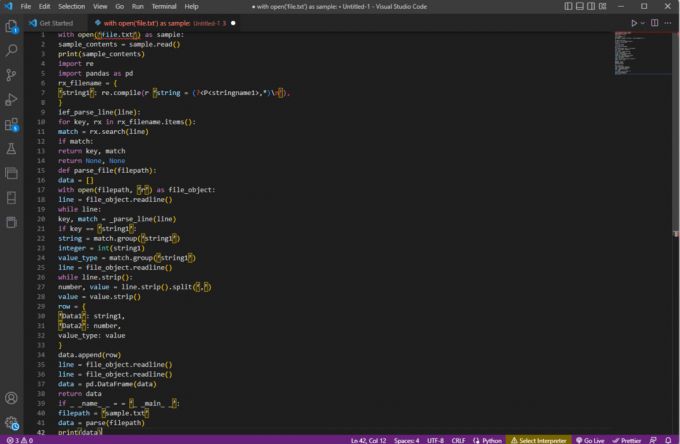
met open(‘file.txt’) als voorbeeld:sample_contents = voorbeeld.lezen()afdrukken (sample_contents)importeren opnieuwimporteer panda's als pdrx_bestandsnaam = {‘string1’: opnieuw compileren (r ‘string = (?,*)\N'),
}ief_parse_line (regel):voor sleutel, rx in rx_filename.items():match = rx.zoeken (regel)indien overeenkomen:return-toets, overeenkomenretourneer Geen, Geendef parse_file (bestandspad):gegevens = []met open (bestandspad, 'r') als file_object:regel = file_object.readline()terwijl regel:key, match = _parse_line (regel)als sleutel == ‘tekenreeks1’:string = match.group(‘string1’)geheel getal = geheel getal (tekenreeks1)waarde_type = match.group(‘string1’)regel = file_object.readline()terwijl lijn.strip():getal, waarde = lijn.strip().split(‘,’)waarde = waarde.strip()rij = {‘Gegevens1’: tekenreeks1,‘Data2’: nummer,waarde_type: waarde}data.append (rij)regel = file_object.readline()regel = file_object.readline()gegevens = pd. DataFrame (gegevens)gegevens retournerenif _ _name_ _ = = ‘_ _main_ _’:bestandspad = ‘voorbeeld.txt’data = ontleden (bestandspad)afdrukken (gegevens)
Het proces van het omzetten van een tekst of corpus in tokens of kleinere stukken op basis van bepaalde regels wordt tokenisatie genoemd. Om te leren hoe u parseerfouten kunt oplossen, is het belangrijk om de woordtokenisatieopdrachten in de code te analyseren. Net als bij de regex kunnen met deze methode eigen regels worden gemaakt en het helpt bij taken voor het voorbewerken van tekst, zoals het in kaart brengen van woordsoorten. Ook activiteiten zoals het vinden en matchen van veelgebruikte woorden, het opschonen van tekst en het klaarmaken van de gegevens voor geavanceerde tekstanalysetechnieken zoals sentimentanalyse worden met deze methode uitgevoerd. Als de tokenisatie onjuist is, kan er een fout optreden in de ontleedtekst x.
NLTK-bibliotheek
Het proces maakt gebruik van de populaire taaltoolkit-bibliotheek genaamd NLTK, die een uitgebreide reeks functies heeft voor het uitvoeren van veel NLP-taken. Deze kunnen worden gedownload via de Pip- of Pip-installatiepakketten. Om te weten hoe u tekst moet ontleden, kunt u het basispakket van de Anaconda-distributie gebruiken, die standaard de bibliotheek bevat.
Vormen van tokenisatie
De gebruikelijke vormen van deze methode zijn woordtokenisatie en zintokenisatie. Dankzij het token op woordniveau drukt de eerste slechts één woord af, terwijl de laatste het woord op zinsniveau afdrukt.
Proces van het ontleden van tekst
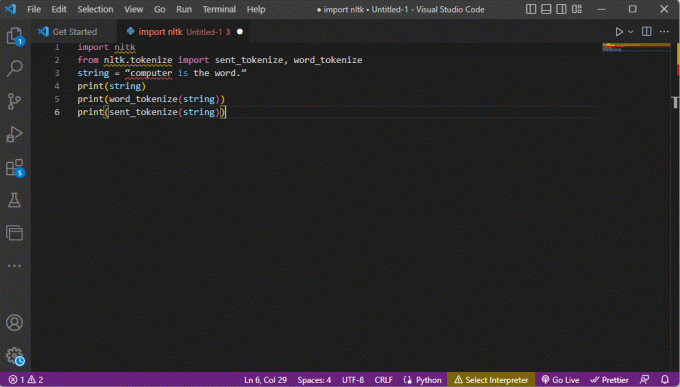
De code die de bovenstaande stappen voor tokenisatie uitlegt, wordt hier gegeven.
import nltkvan nltk.tokenize importeer sent_tokenize, word_tokenizestring = "computer is het woord."afdrukken (reeks)print (word_tokenize (tekenreeks))afdrukken (verzonden_tokenize (tekenreeks))
Lees ook:Hoe javascript te repareren: ongeldig (0) Fout
Net als bij de DataFrame-klasse kan de klasse DocParser worden gebruikt om de tekst in de code te ontleden. Met de klasse kunt u de parse-functie aanroepen met het bestandspad.
Proces van het ontleden van tekst
Volg de onderstaande instructies om te weten hoe u tekst kunt ontleden met behulp van de DocParser-klasse.
Opmerking: Om te weten hoe u de parseerfout kunt oplossen, moet deze functie correct zijn geïmplementeerd.
De tool Tekst ontleden wordt gebruikt om specifieke gegevens uit variabelen te extraheren en toe te wijzen aan andere variabelen. Dit is onafhankelijk van alle andere tools die in een taak worden gebruikt en de BPA Platform-tool wordt gebruikt om variabelen te consumeren en uit te voeren. Gebruik de hier gegeven link om toegang te krijgen tot de Ontleed teksttool online en gebruik de eerder gegeven antwoorden over het ontleden van tekst.

De TextFieldParser gebruikte objecten om zeer grote bestanden te ontleden en te verwerken die gestructureerd en afgebakend zijn. De breedte en kolom van tekst, zoals logbestanden of verouderde database-informatie, kan bij deze methode worden gebruikt. De parseermethode is vergelijkbaar met het herhalen van de code over een tekstbestand en wordt voornamelijk gebruikt om tekstvelden te extraheren, vergelijkbaar met methoden voor het manipuleren van tekenreeksen. Dit wordt gedaan om afgebakende tekenreeksen en velden van verschillende breedtes te tokeniseren met behulp van het gedefinieerde scheidingsteken, zoals een komma of tabruimte.
Functies om tekst te ontleden
De volgende functies kunnen worden gebruikt om de tekst in deze methode te ontleden.
Methoden om MatchObject te vinden
Er zijn twee basismethoden om het MatchObject in de code of de geparseerde tekst te vinden.
In beide gevallen, als een veld niet overeenkomt met de opgegeven indeling tijdens het ontleden of zoeken naar het ontleden van tekst, MalformedLineException uitzondering wordt geretourneerd.
Als laatste en eenvoudige methode om de tekst te ontleden, kunt u de MS-Excel app als een parser om door tabs en komma's gescheiden bestanden te maken. Dit zou helpen bij het vergelijken van uw geparseerde resultaat en helpen bij het vinden van hoe u de parseerfout kunt oplossen.
1. Selecteer de gegevenswaarden in het bronbestand en druk op de Ctrl + C-toetsen samen om het bestand te kopiëren.
2. Open de Excelleren app met behulp van de Windows-zoekbalk.

3. Klik op de A1 cel en druk op de Ctrl + V-toetsen tegelijkertijd om de gekopieerde tekst te plakken.
4. Selecteer de A1 cel, navigeer naar de Gegevens tabblad en klik op de Tekst naar kolommen optie in de Gegevenshulpmiddelen sectie.
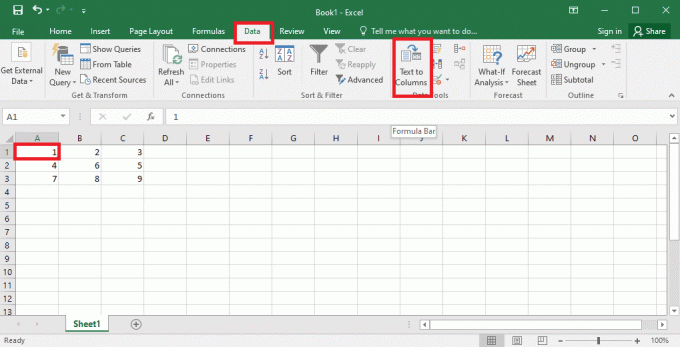
5A. Selecteer de afgebakend optie als een komma of tabblad spatie wordt gebruikt als scheidingsteken en klik op de Volgende En Finish toetsen.

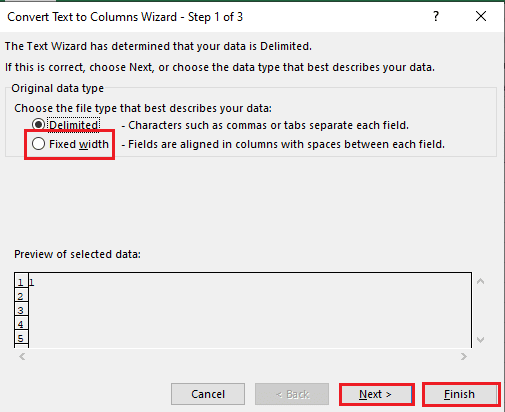
5B. Selecteer de Vaste breedte optie, wijs een waarde toe voor het scheidingsteken en klik op de Volgende En Finish toetsen.
Lees ook:Hoe Fix Move Excel Column Error
Er kan een fout optreden in het parseren van tekst x op Android-apparaten als Parseerfout: er is een probleem opgetreden bij het parseren van het pakket. Dit gebeurt meestal wanneer de app niet kan worden geïnstalleerd vanuit de Google Play Store of wanneer een app van derden wordt uitgevoerd.
De fouttekst x kan optreden als de lijst met tekenvectoren wordt herhaald en andere functies een lineair model vormen voor het berekenen van de gegevenswaarden. De foutmelding is Error in parse (text = x, keep.source = FALSE):
U kunt het artikel lezen op hoe parseerfout op Android op te lossen om de oorzaken en methoden te leren om de fout te verhelpen.
Afgezien van de oplossingen in de gids, kunt u de volgende oplossingen proberen.
Aanbevolen:
Het artikel helpt bij het lesgeven hoe tekst te ontleden en om te leren hoe u parseerfouten kunt oplossen. Laat ons weten welke methode heeft geholpen bij het oplossen van de fout in het parseren van tekst x en welke methode van parseren de voorkeur heeft. Deel uw suggesties en vragen in de opmerkingen hieronder.

