
0
Wyświetlenia

Jeśli nauczyłeś się kilku języków programowania komputerów, być może słyszałeś termin analizowanie tekstu. Służy to uproszczeniu złożonych wartości danych w pliku. Artykuł pomoże ci dowiedzieć się, jak analizować tekst za pomocą języka. Oprócz tego, jeśli napotkałeś błąd w analizie tekstu x, będziesz wiedział, jak naprawić błąd analizy w artykule.
Spis treści
W tym artykule pokazaliśmy pełny przewodnik po analizie tekstu na różne sposoby, a także krótko przedstawiliśmy wprowadzenie do analizy tekstu.
Zanim zagłębisz się, aby poznać koncepcje analizowania tekstu przy użyciu dowolnego kodu. Ważne jest, aby znać podstawy języka i kodowania.
Aby przeanalizować tekst, wykorzystuje się przetwarzanie języka naturalnego lub NLP, które jest poddziedziną domeny sztucznej inteligencji. Język Python, który jest jednym z języków należących do tej kategorii, służy do analizowania tekstu.
Kody NLP umożliwiają komputerom rozumienie i przetwarzanie ludzkich języków w celu dostosowania ich do różnych zastosowań. Aby zastosować techniki ML lub uczenia maszynowego w języku, nieustrukturyzowane dane tekstowe muszą zostać przekonwertowane na ustrukturyzowane dane tabelaryczne. Aby zakończyć czynność analizowania, język Python jest używany do zmiany kodów programu.
Analizowanie tekstu oznacza po prostu konwersję danych z jednego formatu na inny. Format, w jakim plik jest zapisany, zostanie poddany analizie lub przekonwertowany na plik w innym formacie, aby umożliwić użytkownikowi wykorzystanie go w różnych aplikacjach.
Powody, dla których tekst musi być analizowany, są podane w tej sekcji i jest to wstępna wiedza, zanim nauczysz się analizować tekst.
Klasa DataFrame języka Python ma wszystkie wymagane funkcje do analizowania tekstu. Ta wbudowana biblioteka zawiera niezbędne kody do analizowania danych w dowolnym formacie do innego formatu.
Krótkie wprowadzenie do klasy DataFrame
DataFrame Class to bogata w funkcje struktura danych, która jest używana jako narzędzie do analizy danych. Jest to potężne narzędzie do analizy danych, którego można użyć do analizy danych przy minimalnym wysiłku.
Pandy języka Python pomagają w wykonywaniu operacji SQL lub bazodanowych z najwyższą perfekcją, aby uniknąć błędów w parsowaniu tekstu x. Zawiera również narzędzia IO, które pomagają w analizie plików CSV, MS Excel, JSON, HDF5 i innych formatów danych.
Przeczytaj także:Napraw błąd, który wystąpił podczas próby żądania proxy
Proces parsowania tekstu przy użyciu klasy DataFrame
Aby dowiedzieć się, jak analizować tekst, możesz użyć standardowego procesu przy użyciu klasy DataFrame podanej w tej sekcji.
Notatka: Pisanie kodu na pustej ramce DataFrame może być żmudne i złożone. Pandy pozwalają na tworzenie danych w klasie DataFrame z tych typów danych. W związku z tym dane w pierwotnym typie danych można łatwo przeanalizować do wymaganego formatu danych.
Opcja I: Format standardowy
Standardowa metoda formatowania dowolnego pliku z określonym formatem danych, takim jak CSV, została wyjaśniona tutaj.
Notatka: Tutaj zmienna o nazwie rez służy do wykonywania Czytać funkcja danych w pliku dane.txt przy użyciu importowanych pand pd. Format danych tekstu wejściowego jest określony w pliku CSV format.
Przykładowy kod procesu wyjaśnionego powyżej znajduje się poniżej i pomoże w zrozumieniu, jak analizować tekst.
importuj pandy jako pdres = pd.read_csv('dane.txt')rez
W takim przypadku, jeśli wprowadzisz wartości danych w pliku dane.txt Jak na przykład [1,2,3], zostanie przeanalizowany i wyświetlony jako 1 2 3.
Opcja II: Metoda łańcuchowa
Jeśli tekst podany w kodzie zawiera tylko ciągi lub znaki alfanumeryczne, znaki specjalne w ciągu, takie jak przecinek, spacja itp., mogą zostać użyte do oddzielenia i przeanalizowania tekstu. Proces jest podobny do typowych wewnętrznych operacji na łańcuchach. Aby dowiedzieć się, jak naprawić błąd analizy, musisz postępować zgodnie z procesem analizowania tekstu za pomocą tej opcji, wyjaśnionym poniżej.
Na przykład w kodzie podanym poniżej znaki specjalne w ciągu mój_string, które są, ',' I ':’ są identyfikowane. Ten proces należy wykonać ostrożnie, aby uniknąć błędu w analizie tekstu x.
Na przykład łańcuch jest dzielony na wartości danych tekstowych na podstawie znaków specjalnych identyfikowanych za pomocą polecenia split.
Przykładowy kod procesu wyjaśnionego powyżej podano poniżej.
my_string = „Nazwy: technika, komputer”sfinal = [name.strip() dla nazwy w my_string.split(':')[1].split(',')]print("Nazwy: {}".format (sfinal))
W takim przypadku wynik przeanalizowanego łańcucha zostanie wyświetlony w sposób pokazany poniżej.
Nazwy: [„Tech”, „komputer”]
Aby uzyskać lepszą przejrzystość i wiedzieć, jak analizować tekst podczas używania tekstu ciągu, a Do używana jest pętla, a kod jest modyfikowany w następujący sposób.
my_string = „Nazwy: technika, komputer”s1 = my_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [name.strip() dla imienia w s3]dla idx, pozycja w enumerate([s1, s2, s3, s4]):print("Krok {}: {}".format (idx, pozycja))
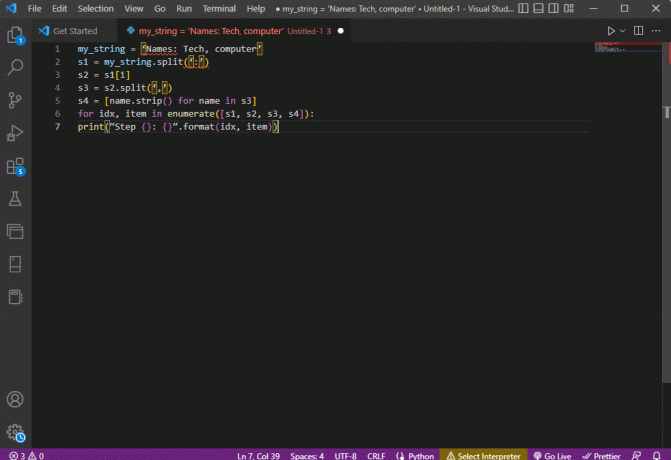
Wynik przeanalizowanego tekstu dla każdego z tych kroków jest wyświetlany w sposób podany poniżej. Możesz zauważyć, że w kroku 0 łańcuch jest rozdzielany na podstawie znaku specjalnego : a wartości danych tekstowych są rozdzielane na podstawie znaku w dalszych krokach.
Krok 0: [„Imiona”, „Technologia, komputer”]Krok 1: technika, komputerKrok 2: [„Technologia”, „komputer”]Krok 3: [„Technologia”, „komputer”]
Opcja III: Analiza złożonego pliku
W większości przypadków dane pliku, które należy przeanalizować, zawierają różne typy danych i wartości danych. W takim przypadku analiza pliku przy użyciu metod wyjaśnionych wcześniej może być trudna.
Funkcje analizowania złożonych danych w pliku polegają na wyświetlaniu wartości danych w formacie tabelarycznym.
Zanim zagłębimy się w naukę parsowania tekstu w tej metodzie, konieczne jest poznanie kilku podstawowych pojęć. Analiza wartości danych odbywa się na podstawie wyrażeń regularnych lub Regex.
Wzorce wyrażeń regularnych
Aby wiedzieć, jak naprawić błąd analizy, musisz upewnić się, że wzorce wyrażeń regularnych w wyrażeniach są prawidłowe. Kod służący do analizowania wartości danych ciągów obejmowałby typowe wzorce wyrażeń regularnych wymienione poniżej w tej sekcji.
Wyrażenia regularne
Moduły wyrażeń regularnych są główną częścią pakietu pandas w języku Python i błędny re może prowadzić do błędu w parsowaniu tekstu x. Jest to mały język osadzony w Pythonie, aby znaleźć wzorzec ciągu w wyrażeniu. Wyrażenia regularne lub wyrażenia regularne to ciągi znaków o specjalnej składni. Pozwala użytkownikowi dopasować wzorce w innych ciągach na podstawie wartości w ciągach.
Regex jest tworzony na podstawie typu danych i wymagań wyrażenia w ciągu, na przykład Ciąg znaków = (.*)\n. Wyrażenie regularne jest używane przed wzorcem w każdym wyrażeniu. Symbole używane w wyrażeniach regularnych są wymienione poniżej i pomogą w zrozumieniu, jak analizować tekst.
Obiekty wyrażeń regularnych
RegexObject jest wartością zwracaną przez funkcję kompilacji i służy do zwracania obiektu MatchObject, jeśli wyrażenie pasuje do wartości dopasowania.
1. Dopasuj obiekt
Ponieważ wartość logiczna MatchObject jest zawsze True, możesz użyć an Jeśli instrukcja identyfikująca pozytywne dopasowania w obiekcie. W przypadku korzystania z Jeśli instrukcja, grupa, do której odnosi się indeks, jest używana do znalezienia dopasowania obiektu w wyrażeniu.
2. Metody MatchObject
Podczas znajdowania sposobu analizowania tekstu ważne jest, aby wiedzieć, że obiekt MatchObject ma dwie podstawowe metody wymienione poniżej. Jeśli MatchObject zostanie znaleziony w określonym wyrażeniu, zwróci jego instancję, w przeciwnym razie zwróci None.
Funkcje wyrażeń regularnych
Funkcje wyrażeń regularnych to wiersze kodu, które są używane do wykonywania określonej funkcji określonej przez użytkownika z zestawu wartości danych.
Notatka: Aby napisać funkcje, dla wyrażeń regularnych używane są surowe łańcuchy, aby uniknąć błędów w analizie tekstu x. Odbywa się to poprzez dodanie indeksu dolnego R przed każdym wzorcem w wyrażeniu.
Typowe funkcje używane w wyrażeniach wyjaśniono poniżej.
1. re.findall()
Ta funkcja zwraca wszystkie wzorce w łańcuchu, jeśli zostanie znalezione dopasowanie, i zwraca pustą listę, jeśli nie zostanie znalezione dopasowanie. Na przykład funkcja, string = re.findall('[aeiou]', regex_filename) służy do wyszukiwania samogłosek w nazwie pliku.
2. ponownie podzielić()
Ta funkcja służy do dzielenia łańcucha w przypadku znalezienia dopasowania do określonego znaku, takiego jak spacja. W przypadku braku dopasowania zwraca pusty ciąg.
3. ponownie sub()
Funkcja zastępuje dopasowany tekst zawartością podanej zmiennej zamiany. W przeciwieństwie do innych funkcji, jeśli nie zostanie znaleziony żaden wzorzec, zwracany jest oryginalny łańcuch.
4. badania()
Jedną z podstawowych funkcji pomagających w nauce parsowania tekstu jest funkcja wyszukiwania. Pomaga w wyszukaniu wzorca w łańcuchu i zwróceniu obiektu dopasowania. Jeśli wyszukiwanie nie powiedzie się w zidentyfikowaniu dopasowania, nie zostanie zwrócona żadna wartość.
5. re.compile (wzorzec)
Ta funkcja służy do kompilowania wzorców wyrażeń regularnych do RegexObject, co zostało omówione wcześniej.
Inne wymagania
Wymienione wymagania są dodatkową funkcją wykorzystywaną przez zaawansowanych programistów w analizie danych.
Przeczytaj także:Jak zainstalować NumPy w systemie Windows 10
Proces analizowania tekstu
Metoda analizowania tekstu w tej złożonej opcji jest opisana poniżej.
Komenda dane = pd. DataFrame (dane) służy do tworzenia Pandas DataFrame z wartości dict. Alternatywnie możesz użyć następujących poleceń do odpowiednich celów, jak podano poniżej.
Ostatnim krokiem, aby dowiedzieć się, jak analizować tekst, jest przetestowanie parsera za pomocą Jeśli stwierdzenie poprzez przypisanie wartości do zmiennej dane i wydrukować go za pomocą drukować (dane) Komenda.
Przykładowy kod dla powyższego wyjaśnienia znajduje się tutaj.
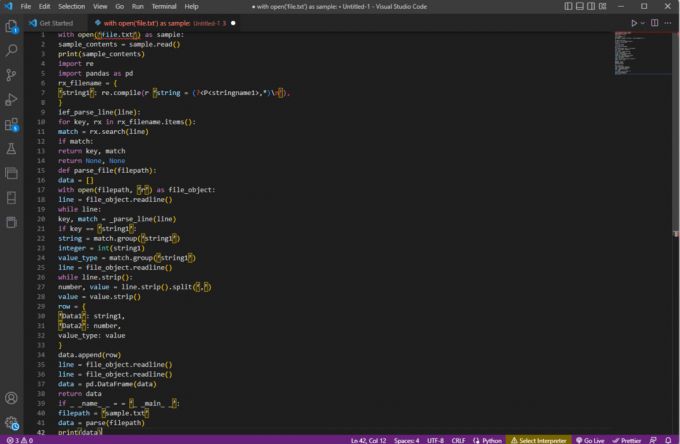
z open('file.txt') jako próbką:zawartość_próbki = próbka.odczytaj()drukuj (sample_contents)import reimportuj pandy jako pdnazwa_pliku rx = {‘string1’: re.compile (r ‘string = (?,*)\N'),
}ief_parse_line (linia):dla klucza rx w rx_filename.items():dopasowanie = rx.szukaj (linia)jeśli pasuje:klawisz powrotu, dopasujzwróć Brak, Brakdef parse_file (ścieżka do pliku):dane = []z open (ścieżka do pliku, „r”) jako obiekt_pliku:linia = obiekt_pliku.readline()natomiast linia:klucz, dopasowanie = _parse_line (linia)jeśli klucz == „łańcuch1”:string = match.group('string1')liczba całkowita = int (łańcuch1)typ_wartości = match.group('string1')linia = obiekt_pliku.readline()podczas gdy linia.strip():liczba, wartość = linia.strip().split(‘,’)wartość = wartość.pasek()wiersz = {„Dane1”: ciąg1,„Dane2”: liczba,typ_wartości: wartość}data.append (wiersz)linia = obiekt_pliku.readline()linia = obiekt_pliku.readline()dane = pd. DataFrame (dane)zwróć danejeśli _ _nazwa_ _ = = „_ _główna_ _”:ścieżka do pliku = „przykład.txt”dane = parsowanie (ścieżka do pliku)drukować (dane)
Proces przekształcania tekstu lub korpusu w tokeny lub mniejsze fragmenty w oparciu o określone zasady nazywa się tokenizacją. Aby dowiedzieć się, jak naprawić błąd parsowania, ważne jest przeanalizowanie poleceń tokenizacji słów w kodzie. Podobnie jak w przypadku wyrażenia regularnego, w tej metodzie można tworzyć własne reguły, co pomaga w zadaniach wstępnego przetwarzania tekstu, takich jak mapowanie części mowy. W tej metodzie wykonywane są również działania, takie jak znajdowanie i dopasowywanie typowych słów, czyszczenie tekstu i przygotowywanie danych do zaawansowanych technik analizy tekstu, takich jak analiza tonacji. Jeśli tokenizacja jest niewłaściwa, może wystąpić błąd w tekście analizy x.
Biblioteka NLTK
W procesie tym pomaga popularna biblioteka narzędzi językowych o nazwie NLTK, która posiada bogaty zestaw funkcji do wykonywania wielu zadań NLP. Można je pobrać za pośrednictwem pakietów instalacyjnych Pip lub Pip. Aby wiedzieć, jak analizować tekst, możesz użyć pakietu podstawowego dystrybucji Anaconda, który domyślnie zawiera bibliotekę.
Formy tokenizacji
Powszechnymi formami tej metody są tokenizacja słów i tokenizacja zdań. Dzięki tokenowi na poziomie słowa, ten pierwszy drukuje jedno słowo tylko raz, podczas gdy drugi drukuje słowo na poziomie zdania.
Proces analizowania tekstu
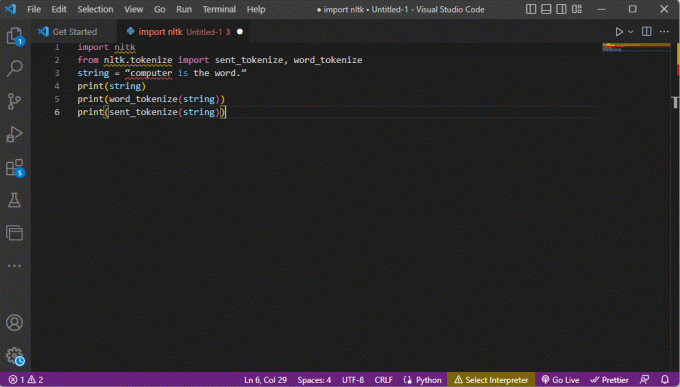
Kod wyjaśniający powyższe kroki tokenizacji znajduje się tutaj.
importuj nltkz nltk.tokenize zaimportuj sent_tokenize, word_tokenizestring = „komputer to słowo”.drukuj (ciąg znaków)print (word_tokenize (string))print (sent_tokenize (string))
Przeczytaj także:Jak naprawić błąd javascript: void (0).
Podobnie jak w przypadku klasy DataFrame, klasa DocParser może służyć do analizowania tekstu w kodzie. Klasa pozwala na wywołanie funkcji parsowania ze ścieżką do pliku.
Proces analizowania tekstu
Aby dowiedzieć się, jak analizować tekst przy użyciu klasy DocParser, postępuj zgodnie z instrukcjami podanymi poniżej.
Notatka: Aby wiedzieć, jak naprawić błąd analizy, ta funkcja musi być poprawnie zaimplementowana.
Narzędzie tekstowe Parse służy do wyodrębniania określonych danych ze zmiennych i mapowania ich na inne zmienne. Jest to niezależne od jakichkolwiek innych narzędzi używanych w zadaniu, a narzędzie platformy BPA służy do konsumowania i wyprowadzania zmiennych. Użyj linku podanego tutaj, aby uzyskać dostęp do Analizuj narzędzie tekstowe online i skorzystaj z podanych wcześniej odpowiedzi na temat parsowania tekstu.

TextFieldParser wykorzystywał obiekty do analizowania i przetwarzania bardzo dużych plików, które mają określoną strukturę i granice. W tej metodzie można użyć szerokości i kolumny tekstu, takiego jak pliki dziennika lub informacje o starszej bazie danych. Metoda analizowania jest podobna do iteracji kodu w pliku tekstowym i jest używana głównie do wyodrębniania pól tekstu, podobnie jak metody manipulacji łańcuchami. Odbywa się to w celu tokenizacji rozdzielonych ciągów i pól o różnych szerokościach przy użyciu zdefiniowanego ogranicznika, takiego jak przecinek lub spacja tabulacji.
Funkcje do analizowania tekstu
Następujące funkcje mogą służyć do analizowania tekstu w tej metodzie.
Metody znajdowania obiektu MatchObject
Istnieją dwie podstawowe metody znajdowania obiektu MatchObject w kodzie lub analizowanym tekście.
W obu przypadkach, jeśli pole nie pasuje do określonego formatu podczas analizowania lub znajdowania sposobu analizowania tekstu, Wyjątek zniekształconej linii zwracany jest wyjątek.
Jako ostateczną i prostą metodę analizy tekstu możesz użyć metody MSExcel app jako parser do tworzenia plików rozdzielanych tabulatorami i przecinkami. Pomogłoby to w sprawdzeniu krzyżowym z przeanalizowanym wynikiem i pomogłoby w znalezieniu sposobu naprawienia błędu analizy.
1. Wybierz wartości danych w pliku źródłowym i naciśnij Klawisze Ctrl + C razem, aby skopiować plik.
2. Otworzyć Przewyższać aplikację za pomocą paska wyszukiwania systemu Windows.

3. Kliknij na A1 komórkę i naciśnij Klawisze Ctrl + V jednocześnie, aby wkleić skopiowany tekst.
4. Wybierz A1 komórkę, przejdź do Dane zakładkę i kliknij na Tekst do kolumn opcja w Narzędzia danych Sekcja.
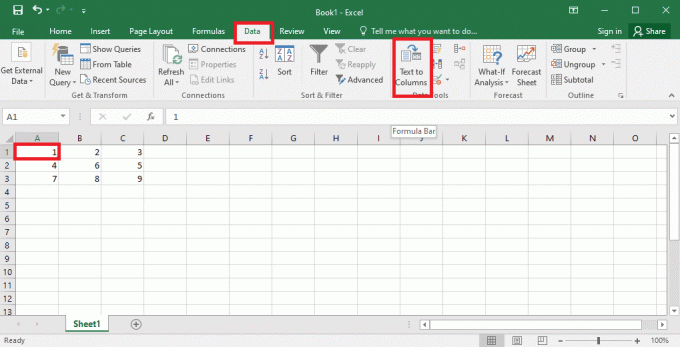
5A. Wybierz Rozgraniczony opcja, jeśli a przecinek Lub patka spacja jest używana jako separator i kliknij na Następny I Skończyć guziki.

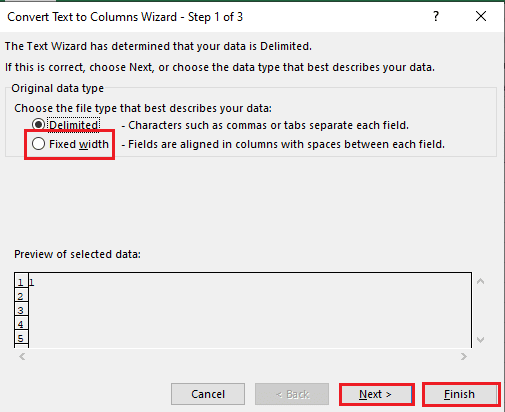
5B. Wybierz Stała szerokość opcję, przypisz wartość separatora i kliknij na Następny I Skończyć guziki.
Przeczytaj także:Jak naprawić błąd przenoszenia kolumny programu Excel
Błąd analizy tekstu x może wystąpić na urządzeniach z Androidem, ponieważ Błąd analizy: Wystąpił problem podczas analizowania pakietu. Zwykle dzieje się tak, gdy nie udaje się zainstalować aplikacji ze Sklepu Google Play lub podczas uruchamiania aplikacji innej firmy.
Tekst błędu x może wystąpić, jeśli lista wektorów znaków jest zapętlona, a inne funkcje tworzą model liniowy do obliczania wartości danych. Komunikat o błędzie to Błąd w analizie (text = x, keep.source = FALSE):
Możesz przeczytać artykuł nt jak naprawić błąd analizy w systemie Android poznać przyczyny i metody naprawy błędu.
Oprócz rozwiązań w przewodniku możesz wypróbować następujące poprawki.
Zalecana:
Artykuł pomaga w nauczaniu jak analizować tekst i dowiedzieć się, jak naprawić błąd analizy. Daj nam znać, która metoda pomogła naprawić błąd w parsowaniu tekstu x i która metoda analizy jest preferowana. Podziel się swoimi sugestiami i zapytaniami w sekcji komentarzy poniżej.

