
0
Visualizações

Se você aprendeu algumas linguagens de programação de computador, pode ter ouvido o termo, análise de texto. Isso é usado para simplificar os valores de dados complexos do arquivo. O artigo ajuda você a saber como analisar o texto usando o idioma. Além disso, se você encontrou um erro na análise do texto x, saberá como corrigir o erro de análise no artigo.
Índice
Neste artigo, mostramos um guia completo para analisar texto de várias maneiras e também apresentamos brevemente uma introdução à análise de texto.
Antes de mergulhar para aprender os conceitos de análise de texto usando qualquer código. É importante saber sobre o básico da linguagem e da codificação.
Para analisar o texto, utiliza-se o Processamento de Linguagem Natural ou NLP, que é um subcampo do domínio da Inteligência Artificial. A linguagem Python, que é uma das linguagens que pertencem à categoria, é usada para analisar o texto.
Os códigos NLP permitem que os computadores entendam e processem linguagens humanas para torná-los adequados para várias aplicações. Para aplicar técnicas de ML ou Machine Learning ao idioma, os dados de texto não estruturados devem ser convertidos em dados tabulares estruturados. Para completar a atividade de análise, a linguagem Python é usada para alterar os códigos do programa.
Analisar texto significa simplesmente converter os dados de um formato para outro formato. O formato no qual o arquivo é salvo deve ser analisado ou convertido em um arquivo em um formato diferente para permitir que o usuário o use em vários aplicativos.
As razões pelas quais o texto deve ser analisado são dadas nesta seção e é um pré-requisito de conhecimento antes de saber como analisar o texto.
A classe DataFrame da linguagem Python possui todas as funções necessárias para analisar o texto. Esta biblioteca embutida abriga os códigos necessários para analisar dados de qualquer formato para outro formato.
Breve introdução da classe DataFrame
DataFrame Class é uma estrutura de dados rica em recursos, que é usada como uma ferramenta de análise de dados. Esta é uma poderosa ferramenta de análise de dados que pode ser usada para analisar dados com o mínimo de esforço.
Os pandas da linguagem Python ajudam na execução das operações SQL ou no estilo de banco de dados com a máxima perfeição para evitar erros na análise do texto x. Ele também contém algumas ferramentas de IO que ajudam na análise de arquivos CSV, MS Excel, JSON, HDF5 e outros formatos de dados.
Leia também:Corrigir o erro ocorrido ao tentar a solicitação de proxy
Processo de análise de texto usando a classe DataFrame
Para saber como analisar o texto, você pode usar o processo padrão usando a classe DataFrame fornecida nesta seção.
Observação: Escrever o código em um DataFrame vazio pode ser tedioso e complexo. Os pandas permitem criar os dados na classe DataFrame a partir desses tipos de dados. Portanto, os dados no tipo de dados primitivo podem ser facilmente analisados para o formato de dados necessário.
Opção I: Formato Padrão
O método padrão para formatar qualquer arquivo com um determinado formato de dados, como CSV, é explicado aqui.
Observação: Aqui, a variável chamada res é usado para realizar o ler função dos dados no arquivo dados.txt usando os pandas importados em pd. O formato de dados do texto de entrada é especificado no CSV formatar.
Um código de exemplo para o processo explicado acima é fornecido abaixo e ajudará a entender como analisar o texto.
importar pandas como pdres = pd.read_csv('data.txt')res
Nesse caso, se você inserir os valores de dados no arquivo dados.txt como [1,2,3], seria analisado e exibido como 1 2 3.
Opção II: Método String
Se o texto fornecido ao código contiver apenas strings ou caracteres alfa, os caracteres especiais na string, como vírgulas, espaço etc., podem ser usados para separar e analisar o texto. O processo é semelhante às operações de string internas comuns. Para descobrir como corrigir o erro de análise, você deve seguir o processo de análise do texto usando esta opção explicada abaixo.
Por exemplo, no código abaixo, os caracteres especiais na string minha_cadeia, que são, ',' e ':’ são identificados. Este processo deve ser feito com cuidado para evitar erros na análise do texto x.
Por exemplo, a string é dividida em valores de dados de texto com base nos caracteres especiais identificados usando o comando split.
O código de exemplo para o processo explicado acima é fornecido abaixo.
my_string = 'Nomes: Tecnologia, computador'sfinal = [name.strip() para nome em my_string.split(':')[1].split(',')]print(“Nomes: {}”.formato (sfinal))
Nesse caso, o resultado da string analisada seria exibido conforme mostrado abaixo.
Nomes: ['Tecnologia', 'computador']
Para obter melhor clareza e saber como analisar o texto enquanto usa a string text, um para loop é utilizado e o código é modificado da seguinte maneira.
my_string = 'Nomes: Tecnologia, computador's1 = minha_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [name.strip() para nome em s3]para idx, item em enumerate([s1, s2, s3, s4]):print(“Etapa {}: {}”.format (idx, item))
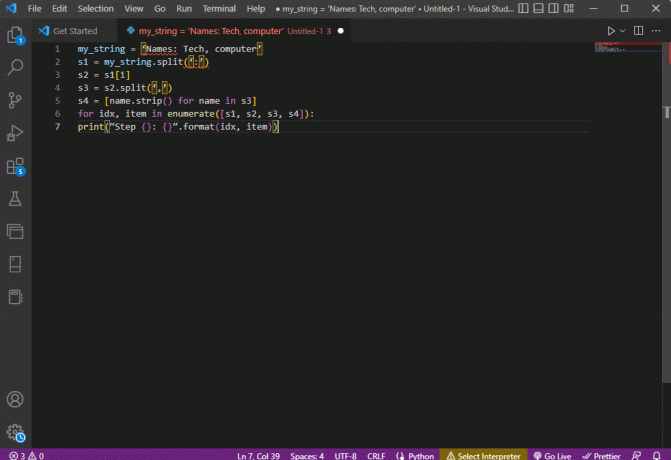
O resultado do texto analisado para cada uma dessas etapas é exibido conforme abaixo. Você pode notar que, na Etapa 0, a string é separada com base no caractere especial : e os valores de dados de texto são separados com base no caractere em etapas posteriores.
Etapa 0: ['Nomes', 'Tecnologia, computador']Passo 1: Tecnologia, computadorEtapa 2: [‘Tecnologia’, ‘computador’]Etapa 3: ['Tecnologia', 'computador']
Opção III: Analisando Arquivo Complexo
Na maioria dos casos, os dados do arquivo que precisam ser analisados contêm vários tipos de dados e valores de dados. Nesse caso, pode ser difícil analisar o arquivo usando os métodos explicados anteriormente.
Os recursos de análise dos dados complexos no arquivo são para fazer com que os valores dos dados sejam exibidos em um formato tabular.
Antes de mergulhar no aprendizado de como analisar texto neste método, é necessário aprender alguns conceitos básicos. A análise dos valores dos dados é feita com base em expressões regulares ou Regex.
Padrões Regex
Para saber como corrigir o erro de análise, você deve garantir que os padrões regex nas expressões sejam adequados. O código para analisar os valores de dados das strings envolveria os padrões Regex comuns listados abaixo nesta seção.
Expressões regulares
Os módulos de expressão regular são uma parte importante do pacote pandas na linguagem Python e um re errado pode levar a um erro na análise do texto x. É uma pequena linguagem embutida dentro do Python para encontrar o padrão de string na expressão. Expressões Regulares ou Regex são strings com sintaxe especial. Ele permite que o usuário combine padrões em outras strings com base nos valores das strings.
O Regex é criado com base no tipo de dados e no requisito da expressão na string, como String = (.*)\n. O regex é usado antes do padrão em todas as expressões. Os símbolos usados nas expressões regulares estão listados abaixo e ajudarão a saber como analisar o texto.
Objetos Regex
O RegexObject é um valor de retorno para a função de compilação e é usado para retornar um MatchObject se a expressão corresponder ao valor de correspondência.
1. MatchObject
Como o valor booleano do MatchObject é sempre True, você pode usar um se para identificar as correspondências positivas no objeto. No caso de usar o se declaração, o grupo referido pelo índice é usado para descobrir a correspondência do objeto na expressão.
2. Métodos de MatchObject
Ao descobrir como analisar o texto, é importante saber que o MatchObject tem dois métodos básicos listados abaixo. Se o MatchObject for encontrado na expressão especificada, ele retornará sua instância, caso contrário, retornará None.
Funções de Expressão Regular
Funções Regex são linhas de código usadas para executar uma determinada função conforme especificado pelo usuário a partir do conjunto de valores de dados adquiridos.
Observação: Para escrever as funções, strings brutas são usadas para as expressões regulares para evitar erros na análise do texto x. Isso é feito adicionando o subscrito r antes de cada padrão na expressão.
As funções comuns usadas nas expressões são explicadas abaixo.
1. re.encontrar()
Esta função retorna todos os padrões na string se uma correspondência for encontrada e retorna uma lista vazia se nenhuma correspondência for encontrada. Por exemplo, a função, string = re.findall('[aeiou]', regex_filename) é usado para localizar a ocorrência de vogal no nome do arquivo.
2. re.split()
Esta função é usada para dividir a string caso seja encontrada uma correspondência com um caractere especificado, como espaço. Caso nenhuma correspondência seja encontrada, ele retorna uma string vazia.
3. re.sub()
A função substitui o texto correspondente pelo conteúdo da variável de substituição fornecida. Ao contrário de outras funções, se nenhum padrão for encontrado, a string original é retornada.
4. pesquisar()
Uma das funções básicas para ajudar a aprender a analisar o texto é a função de pesquisa. Isso ajuda a pesquisar o padrão na string e retornar o objeto de correspondência. Se a pesquisa falhar na identificação da correspondência, nenhum valor será retornado.
5. re.compile (padrão)
Essa função é usada para compilar padrões de expressão regular em um RegexObject, que foi discutido anteriormente.
Outros requerimentos
Os requisitos listados são um recurso adicional usado por programadores avançados na análise de dados.
Leia também:Como instalar o NumPy no Windows 10
Processo de análise de texto
O método para analisar o texto nesta opção complexa é descrito abaixo.
O comando dados = pd. DataFrame (dados) é usado para criar um DataFrame pandas a partir dos valores dict. Como alternativa, você pode usar os seguintes comandos para a respectiva finalidade, conforme indicado abaixo.
A etapa final para saber como analisar o texto é testar o analisador usando o se declaração atribuindo os valores a uma variável dados e imprimi-lo usando o imprimir (dados) comando.
O código de exemplo para a explicação acima é fornecido aqui.
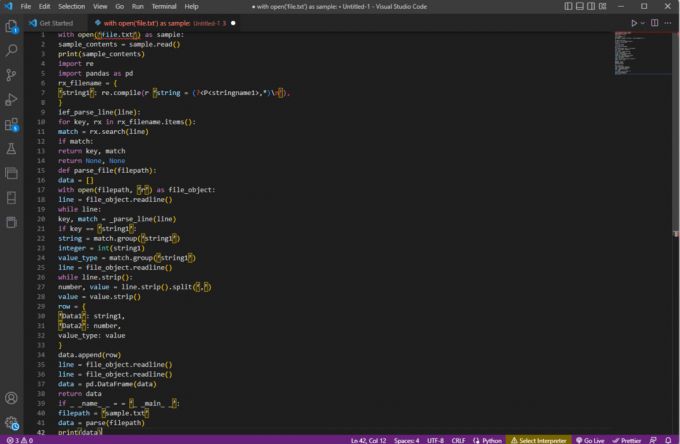
com open('file.txt') como exemplo:sample_contents = sample.read()imprimir (sample_contents)importar reimportar pandas como pdrx_filename = {‘string1’: re.compile (r ‘string = (?,*)\n'),
}ief_parse_line (linha):para chave, rx em rx_filename.items():match = rx.search (linha)se corresponder:chave de retorno, correspondênciaretornar Nenhum, Nenhumdef parse_file (arquivo):dados = []com open (filepath, ‘r’) como file_object:linha = file_object.readline()enquanto linha:chave, correspondência = _parse_line (linha)if chave == ‘string1’:string = match.group('string1')inteiro = int (string1)value_type = match.group('string1')linha = file_object.readline()while line.strip():número, valor = line.strip().split(',')valor = valor.strip()linha = {'Dados1': string1,'Dados2': número,value_type: valor}data.append (linha)linha = file_object.readline()linha = file_object.readline()dados = pd. DataFrame (dados)dados de retornoif _ _name_ _ = = ‘_ _main_ _’:caminho do arquivo = ‘amostra.txt’data = parse (arquivo)imprimir (dados)
O processo de converter um texto ou corpus em tokens ou pedaços menores com base em certas regras é chamado de tokenização. Para saber como corrigir o erro de parse, é importante analisar os comandos de tokenização de palavras no código. Semelhante ao regex, regras próprias podem ser criadas neste método e ajudam em tarefas de pré-processamento de texto, como mapeamento de partes do discurso. Além disso, atividades como localizar e combinar palavras comuns, limpar texto e preparar os dados para técnicas avançadas de análise de texto, como análise de sentimentos, são realizadas neste método. Se a tokenização for imprópria, pode ocorrer um erro na análise do texto x.
Biblioteca NLTK
O processo conta com a ajuda da popular biblioteca de kits de ferramentas de linguagem chamada NLTK, que possui um rico conjunto de funções para realizar muitos trabalhos de NLP. Eles podem ser baixados por meio dos pacotes Pip ou Pip Installs. Para saber como analisar o texto, você pode usar o pacote base da distribuição Anaconda que inclui a biblioteca por padrão.
Formas de Tokenização
As formas comuns desse método são a tokenização de palavras e a tokenização de sentenças. Devido ao token de nível de palavra, o primeiro imprime uma palavra apenas uma vez, enquanto o último imprime a palavra no nível de sentença.
Processo de análise de texto
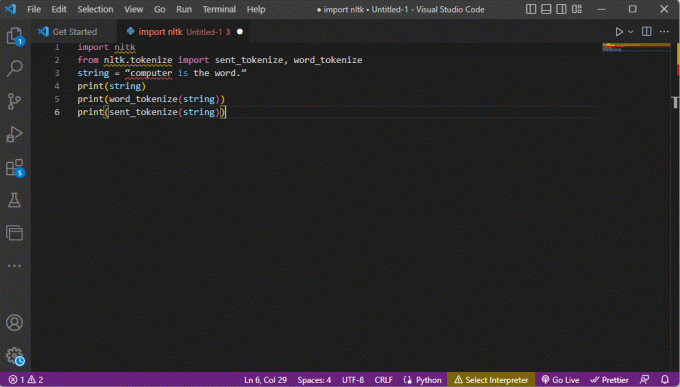
O código que explica as etapas para tokenização acima é fornecido aqui.
importar nltkde nltk.tokenize import sent_tokenize, word_tokenizestring = “computador é a palavra.”imprimir (corda)imprimir (word_tokenize (string))imprimir (sent_tokenize (string))
Leia também:Como corrigir javascript: void (0) Error
Semelhante à classe DataFrame, a classe DocParser pode ser usada para analisar o texto no código. A classe permite que você chame a função de análise com o caminho de arquivo.
Processo de análise de texto
Para saber como analisar texto usando a classe DocParser, siga as instruções abaixo.
Observação: Para saber como corrigir o erro de análise, esta função deve ser implementada corretamente.
A ferramenta Analisar texto é usada para extrair dados específicos de variáveis e mapeá-los para outras variáveis. Isso é independente de quaisquer outras ferramentas usadas em uma tarefa e a ferramenta BPA Platform é usada para consumir e gerar variáveis. Use o link fornecido aqui para acessar o Analisar ferramenta de texto on-line e use as respostas fornecidas anteriormente sobre como analisar o texto.

O TextFieldParser utilizou objetos para analisar e processar arquivos muito grandes que são estruturados e delimitados. A largura e a coluna de texto, como arquivos de log ou informações do banco de dados herdado, podem ser usadas neste método. O método de análise é semelhante à iteração do código em um arquivo de texto e é usado principalmente para extrair campos de texto semelhantes aos métodos de manipulação de strings. Isso é feito para tokenizar strings delimitadas e campos de várias larguras usando o delimitador definido, como vírgula ou espaço de tabulação.
Funções para Analisar Texto
As seguintes funções podem ser usadas para analisar o texto neste método.
Métodos para localizar MatchObject
Existem dois métodos básicos para localizar o MatchObject no código ou no texto analisado.
Em ambos os casos, se um campo não corresponder ao formato especificado ao executar a análise ou descobrir como analisar o texto, um MalformedLineException exceção é retornada.
Como um método final e simples para analisar o texto, você pode usar o Excel app como um analisador para criar arquivos delimitados por tabulações e delimitados por vírgulas. Isso ajudaria na verificação cruzada com o resultado analisado e ajudaria a descobrir como corrigir o erro de análise.
1. Selecione os valores de dados no arquivo de origem e pressione o botão Teclas Ctrl + C juntos para copiar o arquivo.
2. Abra o excel aplicativo usando a barra de pesquisa do Windows.

3. Clique no A1 célula e pressione a tecla Teclas Ctrl + V simultaneamente para colar o texto copiado.
4. Selecione os A1 celular, navegue até o Dados guia e clique no botão Texto para colunas opção no Ferramentas de Dados seção.
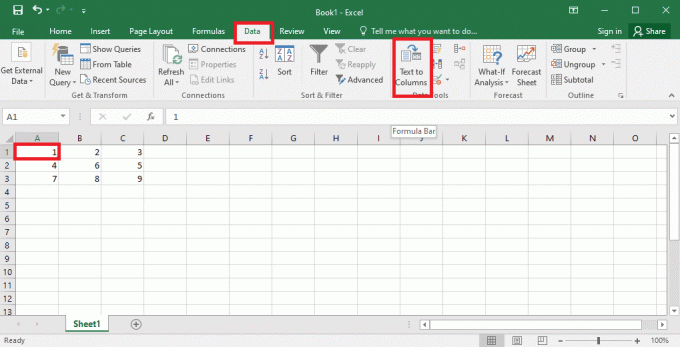
5A. Selecione os delimitado opção se um vírgula ou aba espaço é usado como separador e clique no botão Próximo e Terminar botões.

5B. Selecione os Largura fixa opção, atribua um valor para o separador e clique no botão Próximo e Terminar botões.
Leia também:Como Corrigir o Erro de Coluna Mover do Excel
Erro na análise de texto x pode ocorrer em dispositivos Android como, Erro de análise: houve um problema ao analisar o pacote. Isso geralmente ocorre quando o aplicativo falha na instalação da Google Play Store ou durante a execução de um aplicativo de terceiros.
O texto de erro x pode ocorrer se a lista de vetores de caracteres estiver em loop e outras funções formarem um modelo linear para calcular os valores dos dados. A mensagem de erro é Error in parse (text = x, keep.source = FALSE):
Você pode ler o artigo em como corrigir erro de parse no Android para aprender as causas e métodos para corrigir o erro.
Além das soluções do guia, você pode tentar as seguintes correções.
Recomendado:
O artigo ajuda no ensino como analisar texto e aprender como corrigir erros de análise. Deixe-nos saber qual método ajudou a corrigir o erro na análise do texto x e qual método de análise é o preferido. Por favor, compartilhe suas sugestões e dúvidas na seção de comentários abaixo.

