
0
Виевс

Ако сте научили неколико језика за компјутерско програмирање, можда сте чули термин, рашчлањивање текста. Ово се користи за поједностављење сложених вредности података датотеке. Чланак вам помаже да сазнате како да рашчланите текст користећи језик. Поред овога, ако сте се суочили са грешком у рашчлањивању текста к, знаћете како да исправите грешку при рашчлањивању текста у чланку.
Преглед садржаја
У овом чланку смо показали комплетан водич за рашчлањивање текста на различите начине, а такође смо укратко дали увод у рашчлањивање текста.
Пре него што се удубите да научите концепте рашчлањивања текста помоћу било ког кода. Важно је знати основе језика и кодирања.
За рашчлањивање текста користи се обрада природног језика или НЛП, што је потпоље домена вештачке интелигенције. Језик Питхон, који је један од језика који припадају овој категорији, користи се за рашчлањивање текста.
НЛП кодови омогућавају рачунарима да разумеју и обрађују људске језике како би их учинили погодним за различите примене. Да бисте применили технике МЛ или машинског учења на језик, неструктурирани текстуални подаци морају да се конвертују у структуриране табеларне податке. За завршетак активности рашчлањивања, језик Питхон се користи за измену програмских кодова.
Рашчлањивање текста једноставно значи претварање података из једног формата у други формат. Формат у коме је датотека сачувана биће рашчлањена или конвертована у датотеку у другом формату како би се кориснику омогућило да је користи у различитим апликацијама.
Разлози због којих се текст мора рашчланити дати су у овом одељку и то је предуслов да бисте сазнали како да рашчланите текст.
ДатаФраме класа језика Питхон има све потребне функције за рашчлањивање текста. Ова уграђена библиотека садржи потребне кодове за рашчлањивање података било ког формата у други формат.
Кратко представљање класе ДатаФраме
ДатаФраме Цласс је структура података богата функцијама, која се користи као алат за анализу података. Ово је моћан алат за анализу података који се може користити за анализу података уз минималан напор.
Панде језика Питхон помажу у извођењу СКЛ или операција у стилу базе података са највећом савршеношћу како би се избегла грешка у рашчлањивању текста к. Такође садржи неке ИО алате који помажу у анализи датотека ЦСВ, МС Екцел, ЈСОН, ХДФ5 и других формата података.
Такође прочитајте:Исправите грешку која је настала приликом покушаја прокси захтева
Процес рашчлањивања текста помоћу класе ДатаФраме
Да бисте знали како да рашчланите текст, можете користити стандардни процес користећи класу ДатаФраме дату у овом одељку.
Белешка: Писање кода на празном ДатаФраме-у може бити заморно и сложено. Панде дозвољавају креирање података у класи ДатаФраме од ових типова података. Дакле, подаци у примитивном типу података могу се лако рашчланити на потребан формат података.
Опција И: Стандардни формат
Овде је објашњен стандардни метод за форматирање било које датотеке са одређеним форматом података као што је ЦСВ.
Белешка: Овде је променљива именована рес се користи за обављање читати функцију података у датотеци дата.ткт користећи панде увезене у пд. Формат података за унос текста је наведен у ЦСВ формату.
Пример кода за процес објашњен изнад је дат у наставку и помоћи ће у разумевању како да рашчланите текст.
увоз панде као пдрес = пд.реад_цсв(‘дата.ткт’)рес
У овом случају, ако унесете вредности података у датотеку дата.ткт као такав [1,2,3], био би рашчлањен и приказан као 1 2 3.
Опција ИИ: Стринг метода
Ако текст који је дат коду садржи само низове или алфа знакове, посебни знакови у стрингу као што су зарези, размак итд., могу се користити за раздвајање и рашчлањивање текста. Процес је сличан уобичајеним интерним стринг операцијама. Да бисте пронашли како да поправите грешку рашчлањивања, морате да пратите процес рашчлањивања текста помоћу ове опције који је објашњен у наставку.
На пример, у коду датом испод, специјални знакови у стрингу мој_стринг, који су, ',' и ':“ су идентификовани. Овај процес се мора обавити пажљиво како би се избегла грешка у рашчлањивању текста к.
На пример, стринг се дели на вредности текстуалних података на основу специјалних знакова идентификованих помоћу команде сплит.
Пример кода за процес који је горе објашњен је дат у наставку.
ми_стринг = 'Имена: Техника, рачунар'сфинал = [наме.стрип() за име у ми_стринг.сплит(‘:’)[1].сплит(‘,’)]принт(“Имена: {}”.формат (коначно))
У овом случају, резултат рашчлањеног низа ће бити приказан као што је приказано испод.
Имена: [„Техника“, „компјутер“]
Да бисте добили бољу јасноћу и знали како да рашчланите текст док користите текст стринга, а за петља се користи и код се мења на следећи начин.
ми_стринг = 'Имена: Техника, рачунар'с1 = мој_стринг.сплит(‘:’)с2 = с1[1]с3 = с2.сплит(‘,’)с4 = [наме.стрип() за име у с3]за идк, ставка у енумерате([с1, с2, с3, с4]):принт(“Корак {}: {}”.формат (идк, итем))
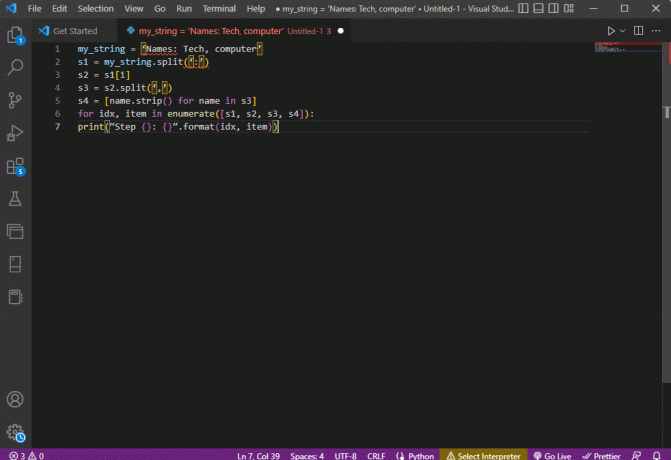
Резултат рашчлањеног текста за сваки од ових корака је приказан као што је дато у наставку. Можете приметити да је у кораку 0 стринг одвојен на основу специјалног знака : а вредности текстуалних података се одвајају на основу карактера у даљим корацима.
Корак 0: [„Имена“, „Техника, рачунар“]Корак 1: Техника, рачунарКорак 2: [„Техника“, „компјутер“]Корак 3: [„Техника“, „компјутер“]
Опција ИИИ: рашчлањивање сложене датотеке
У већини случајева, подаци датотеке које треба рашчланити садрже различите типове података и вредности података. У овом случају, можда ће бити тешко рашчланити датотеку користећи методе објашњене раније.
Карактеристике рашчлањивања сложених података у датотеци су да се вредности података прикажу у табеларном формату.
Пре него што уђете у учење како да рашчланите текст овом методом, потребно је да научите неколико основних концепата. Рашчлањивање вредности података се врши на основу регуларних израза или редовног израза.
Регек Паттернс
Да бисте знали како да поправите грешку рашчлањивања, морате да се уверите да су обрасци регуларног израза у изразима исправни. Код за рашчлањивање вредности података низова укључивао би уобичајене обрасце регуларног израза који су наведени испод у овом одељку.
Регуларни изрази
Модули регуларног израза су главни део пакета пандас у језику Питхон и погрешно ре може довести до грешке у рашчлањивању текста к. То је мали језик уграђен у Питхон да би се пронашао образац стрингова у изразу. Регуларни изрази или Регек су стрингови са посебном синтаксом. Омогућава кориснику да усклади обрасце у другим стринговима на основу вредности у стринговима.
Регек се креира на основу типа података и захтева израза у стрингу, као што је Стринг = (.*)\н. Редовни израз се користи пре шаблона у сваком изразу. Симболи који се користе у регуларним изразима наведени су у наставку и помоћи ће вам да знате како да рашчланите текст.
РегекОбјецтс
РегекОбјецт је повратна вредност за функцију компајлирања и користи се за враћање МатцхОбјецт ако израз одговара вредности подударања.
1. МатцхОбјецт
Како је Боолеан вредност МатцхОбјецт-а увек Тачна, можете користити ако изјава за идентификацију позитивних подударања у објекту. У случају коришћења ако израз, група на коју упућује индекс се користи за проналажење подударања објекта у изразу.
2. Методе МатцхОбјецт-а
Док проналазите како да рашчланите текст, важно је знати да МатцхОбјецт има две основне методе као што су наведене у наставку. Ако је МатцхОбјецт пронађен у наведеном изразу, вратио би своју инстанцу, у супротном би вратио Ноне.
Функције регуларног израза
Регек функције су линије кода које се користе за обављање одређене функције коју је одредио корисник из скупа набављених вредности података.
Белешка: За писање функција, необрађени стрингови се користе за регуларне изразе да би се избегла грешка у рашчлањивању текста к. Ово се ради додавањем индекса р пре сваког узорка у изразу.
Уобичајене функције које се користе у изразима су објашњене у наставку.
1. ре.финдалл()
Ова функција враћа све обрасце у стрингу ако се пронађе подударање и враћа празну листу ако није пронађено подударање. На пример, функција, стринг = ре.финдалл(‘[аеиоу]’, име_датотеке регуларног израза) се користи за проналажење самогласника у имену датотеке.
2. ре.сплит()
Ова функција се користи за раздвајање стринга у случају подударања са одређеним карактером као што је размак. У случају да није пронађено подударање, враћа празан стринг.
3. ре.суб()
Функција замењује одговарајући текст са садржајем дате променљиве замене. За разлику од других функција, ако се не пронађе образац, враћа се оригинални стринг.
4. ре.сеарцх()
Једна од основних функција која помаже у учењу рашчлањивања текста је функција претраге. Помаже у претраживању шаблона у низу и враћању објекта подударања. Ако претрага не успе да идентификује подударање, вредност се не враћа.
5. ре.цомпиле (паттерн)
Ова функција се користи за компајлирање образаца регуларних израза у РегекОбјецт, о чему је било речи раније.
Други захтеви
Наведени захтеви су додатна карактеристика коју користе напредни програмери у анализи података.
Такође прочитајте:Како инсталирати НумПи на Виндовс 10
Процес рашчлањивања текста
Метода за рашчлањивање текста у овој сложеној опцији је описана на следећи начин.
Команда подаци = пд. ДатаФраме (подаци) се користи за креирање пандас ДатаФраме-а од вредности дицт. Алтернативно, можете користити следеће команде за одговарајућу сврху као што је наведено у наставку.
Последњи корак да знате како да рашчланите текст је да тестирате парсер користећи иф изјава додељивањем вредности променљивој података и штампање помоћу штампа (подаци) команда.
Пример кода за објашњење изнад је дат овде.
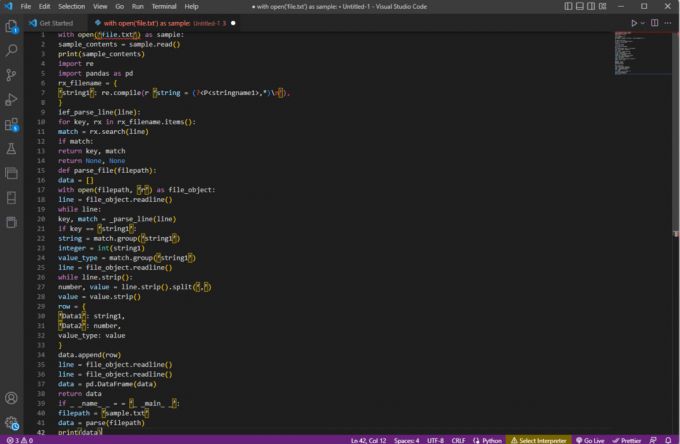
са опен('филе.ткт') као пример:сампле_цонтентс = сампле.реад()штампа (сампле_цонтентс)импорт реувоз панде као пдрк_филенаме = {'стринг1': ре.цомпиле (р 'стринг = (?,*)\н’),
}иеф_парсе_лине (линија):за кључ, рк у рк_филенаме.итемс():матцх = рк.сеарцх (линија)ако се подудара:врати кључ, подударањеврати Ништа, Ништадеф парсе_филе (фајлопат):подаци = []са отвореним (фајлопут, 'р') као филе_објецт:линија = филе_објецт.реадлине()док линија:кључ, подударање = _парсе_лине (ред)ако је кључ == 'стринг1':стринг = матцх.гроуп(‘стринг1’)цео број = инт (стринг1)валуе_типе = матцх.гроуп(‘стринг1’)линија = филе_објецт.реадлине()док лине.стрип():број, вредност = линија.стрип().сплит(‘,’)вредност = вредност.стрип()ред = {'Подаци1': стринг1,„Подаци2“: број,валуе_типе: вредност}дата.аппенд (ред)линија = филе_објецт.реадлине()линија = филе_објецт.реадлине()подаци = пд. ДатаФраме (подаци)врати податкеако _ _име_ _ = = '_ _главни_ _':филепатх = 'сампле.ткт'подаци = рашчлањивање (фајлопут)штампа (подаци)
Процес претварања текста или корпуса у токене или мање делове на основу одређених правила назива се токенизација. Да бисте научили како да поправите грешку рашчлањивања, важно је анализирати команде за токенизацију речи у коду. Слично редовном изразу, у овом методу се могу креирати сопствена правила и она помаже у задацима пре обраде текста као што је мапирање делова говора. Такође, активности као што су проналажење и подударање уобичајених речи, чишћење текста и припрема података за напредне технике анализе текста као што је анализа сентимента се изводе у овој методи. Ако је токенизација неисправна, може доћи до грешке у рашчлањивању текста к.
НЛТК библиотека
Процес захтева помоћ популарне библиотеке језичких алата под називом НЛТК, која има богат скуп функција за обављање многих НЛП послова. Они се могу преузети преко Пип или Пип Инсталлс пакета. Да бисте знали како да рашчланите текст, можете користити основни пакет дистрибуције Анацонда који подразумевано укључује библиотеку.
Облици токенизације
Уобичајени облици ове методе су токенизација речи и токенизација реченица. Захваљујући лексему на нивоу речи, први штампа једну реч само једном, док други штампа реч на нивоу реченице.
Процес рашчлањивања текста
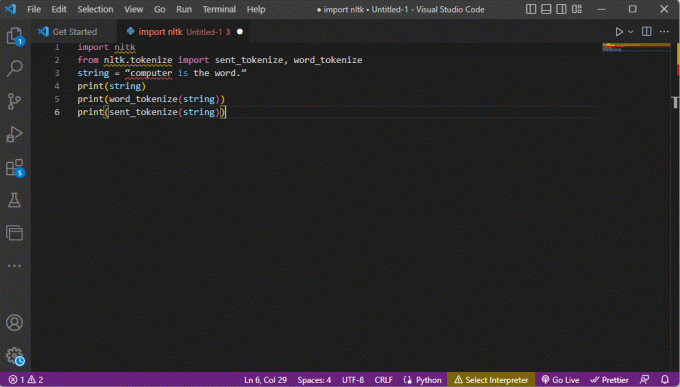
Код који објашњава горе наведене кораке за токенизацију је дат овде.
импорт нлткфром нлтк.токенизе импорт сент_токенизе, ворд_токенизестринг = „компјутер је реч.“штампа (стринг)принт (ворд_токенизе (стринг))принт (сент_токенизе (стринг))
Такође прочитајте:Како да поправите јавасцрипт: грешка воид (0).
Слично класи ДатаФраме, Цласс ДоцПарсер се може користити за рашчлањивање текста у коду. Класа вам омогућава да позовете функцију рашчлањивања помоћу путање датотеке.
Процес рашчлањивања текста
Да бисте знали како да рашчланите текст помоћу класе ДоцПарсер, пратите упутства дата у наставку.
Белешка: Да бисте знали како да поправите грешку рашчлањивања, ова функција мора бити правилно имплементирана.
Алат за рашчлањивање текста се користи за издвајање одређених података из променљивих и мапирање у друге варијабле. Ово је независно од других алата који се користе у задатку, а алат БПА платформе се користи за конзумирање и излаз варијабли. Користите линк који је овде дат да приступите Алат за рашчлањивање текста на мрежи и користите одговоре дате раније о томе како рашчланити текст.

ТектФиелдПарсер је користио објекте за рашчлањивање и обраду веома великих датотека које су структуриране и разграничене. Ширина и колона текста као што су датотеке евиденције или информације о застарелим базама података могу се користити у овој методи. Метода рашчлањивања је слична понављању кода преко текстуалне датотеке и углавном се користи за издвајање поља текста слично методама манипулације стринговима. Ово се ради да би се токенизирали разграничени стрингови и поља различитих ширина користећи дефинисани граничник као што је зарез или размак табулатора.
Функције за рашчлањивање текста
Следеће функције се могу користити за рашчлањивање текста у овој методи.
Методе за проналажење МатцхОбјецт
Постоје две основне методе за проналажење МатцхОбјецт у коду или рашчлањеном тексту.
У оба случаја, ако се поље не подудара са наведеним форматом током рашчлањивања или проналажења како да рашчланим текст, МалформедЛинеЕкцептион изузетак се враћа.
Као коначан и једноставан метод за рашчлањивање текста, можете користити МС Екцел апликацију као парсер за креирање датотека раздвојених табулаторима и зарезима. Ово би помогло у унакрсној провери са вашим рашчлањеним резултатом и помогло у проналажењу како да поправите грешку рашчлањивања.
1. Изаберите вредности података у изворној датотеци и притисните Цтрл + Ц тастери заједно да бисте копирали датотеку.
2. Отвори Екцел апликацију користећи Виндовс траку за претрагу.

3. Кликните на А1 ћелију и притисните тастер Тастери Цтрл + В истовремено да налепите копирани текст.
4. Изаберите А1 ћелије, идите на Подаци картицу и кликните на Текст у колонама опција у Дата Тоолс одељак.
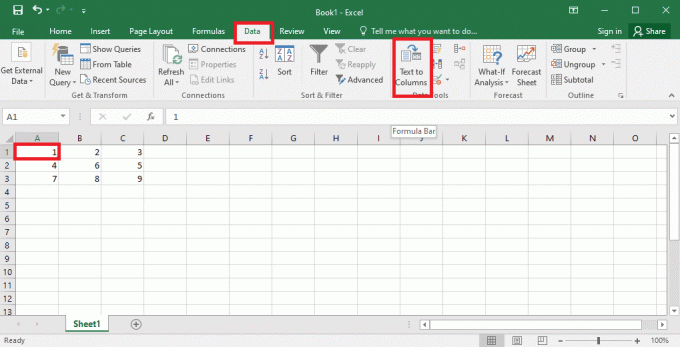
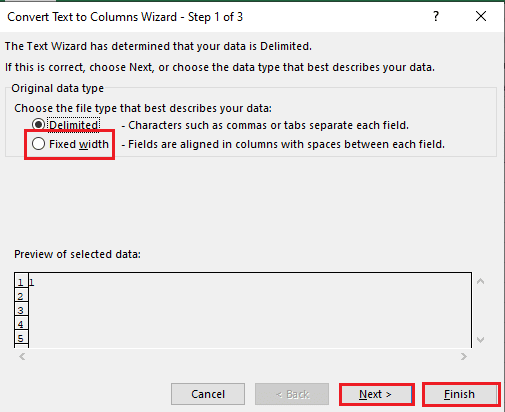
5А. Изаберите Раздвојено опција ако а зарез или таб размак се користи као сепаратор и кликните на Следећи и Заврши дугмад.

5Б. Изаберите Фиксна ширина опцију, доделите вредност за сепаратор и кликните на Следећи и Заврши дугмад.
Такође прочитајте:Како да поправите грешку при премештању Екцел колоне
Грешка у рашчлањивању текста к може се појавити на Андроид уређајима као, Грешка рашчлањивања: Дошло је до проблема при рашчлањивању пакета. Ово се обично дешава када апликација не успе да се инсталира из Гоогле Плаи продавнице или док је покренута апликација треће стране.
Текст грешке к може се појавити ако је листа вектора знакова запетља и друге функције формирају линеарни модел за израчунавање вредности података. Порука о грешци је Грешка у рашчлањивању (текст = к, кееп.соурце = ФАЛСЕ):
Можете прочитати чланак на како поправити грешку рашчлањивања на Андроиду да научите узроке и методе за отклањање грешке.
Осим решења у водичу, можете испробати следеће исправке.
Препоручено:
Чланак помаже у настави како рашчланити текст и да научите како да поправите грешку у рашчлањивању. Обавестите нас који метод је помогао да се исправи грешка у рашчлањивању текста к и који метод рашчлањивања је пожељнији. Молимо вас да поделите своје предлоге и упите у одељку за коментаре испод.

