
0
Görüntüleme

Birkaç bilgisayar programlama dili öğrendiyseniz, metin ayrıştırma terimini duymuş olabilirsiniz. Bu, dosyanın karmaşık veri değerlerini basitleştirmek için kullanılır. Makale, dili kullanarak metni nasıl ayrıştıracağınızı bilmenize yardımcı olur. Buna ek olarak, x metin ayrıştırma hatasıyla karşılaştıysanız, makaledeki ayrıştırma hatasını nasıl düzelteceğinizi bileceksiniz.
İçindekiler
Bu makalede, metni çeşitli yollarla ayrıştırmak için eksiksiz bir kılavuz gösterdik ve ayrıca metin ayrıştırmaya kısaca bir giriş yaptık.
Herhangi bir kod kullanarak metni ayrıştırma kavramlarını öğrenmeden önce. Dilin temellerini ve kodlamayı bilmek önemlidir.
Metni ayrıştırmak için Yapay Zeka alanının bir alt alanı olan Doğal Dil İşleme veya NLP'den yararlanılır. Kategoriye ait dillerden biri olan Python dili, metni ayrıştırmak için kullanılır.
NLP kodları, bilgisayarların insan dillerini çeşitli uygulamalara uygun hale getirmek için anlamasını ve işlemesini sağlar. Dile Makine Öğrenimi veya Makine Öğrenimi tekniklerini uygulamak için yapılandırılmamış metin verilerinin yapılandırılmış tablo verilerine dönüştürülmesi gerekir. Ayrıştırma etkinliğini tamamlamak için, program kodlarını değiştirmek için Python dili kullanılır.
Metni ayrıştırmak, verileri bir biçimden başka bir biçime dönüştürmek anlamına gelir. Dosyanın kaydedildiği format, kullanıcının çeşitli uygulamalarda kullanabilmesi için ayrıştırılmalı veya farklı bir formatta dosyaya dönüştürülmelidir.
Metnin ayrıştırılmasının gerekli olmasının nedenleri bu bölümde verilmektedir ve metnin nasıl ayrıştırılacağını bilmeden önce ön koşul bilgisidir.
Python dilinin DataFrame Sınıfı, metni ayrıştırmak için gerekli tüm işlevlere sahiptir. Bu yerleşik kitaplık, herhangi bir biçimdeki verileri başka bir biçime ayrıştırmak için gerekli kodları barındırır.
DataFrame Sınıfının Kısa Tanıtımı
DataFrame Sınıfı, veri analiz aracı olarak kullanılan, zengin özelliklere sahip bir veri yapısıdır. Bu, verileri minimum çabayla analiz etmek için kullanılabilen güçlü bir veri analiz aracıdır.
Python dilinin pandaları, x ayrıştırma metnindeki hatayı önlemek için SQL veya veritabanı stili işlemleri en üst düzeyde mükemmellikle gerçekleştirmeye yardımcı olur. Ayrıca CSV, MS Excel, JSON, HDF5 ve diğer veri biçimlerindeki dosyaların analizine yardımcı olan bazı IO araçları içerir.
Ayrıca Oku:Proxy İsteği Denenirken Oluşan Hatayı Düzeltin
DataFrame Sınıfını Kullanarak Metni Ayrıştırma İşlemi
Metnin nasıl ayrıştırılacağını bilmek için, bu bölümde verilen DataFrame Sınıfını kullanan standart işlemi kullanabilirsiniz.
Not: Kodu boş bir DataFrame üzerine yazmak sıkıcı ve karmaşık olabilir. Pandalar, bu veri türlerinden DataFrame sınıfında veri oluşturmaya izin verir. Dolayısıyla, ilkel veri tipindeki veriler, gerekli veri formatına kolayca ayrıştırılabilir.
Seçenek I: Standart Format
Herhangi bir dosyayı CSV gibi belirli bir veri biçimiyle biçimlendirmenin standart yöntemi burada açıklanmaktadır.
Not: Burada adı geçen değişken res gerçekleştirmek için kullanılır Okumak dosyadaki verilerin işlevi veri.txt ithal edilen pandaları kullanarak pd. Giriş metninin veri formatı, CSV'ler biçim.
Yukarıda açıklanan işlem için örnek bir kod aşağıda verilmiştir ve metnin nasıl ayrıştırılacağını anlamanıza yardımcı olacaktır.
pandaları pd olarak içe aktarres = pd.read_csv('data.txt')res
Bu durumda, dosyaya veri değerlerini girerseniz veri.txt örneğin [1,2,3], ayrıştırılır ve şu şekilde görüntülenir: 1 2 3.
Seçenek II: String Yöntemi
Eğer koda verilen metin sadece karakter dizileri veya alfa karakterleri içeriyorsa, dizideki virgül, boşluk vb. özel karakterler metni ayırmak ve ayrıştırmak için kullanılabilir. İşlem, yaygın dahili dize işlemlerine benzer. Ayrıştırma hatasını nasıl düzelteceğinizi bulmak için, aşağıda açıklanan bu seçeneği kullanarak metni ayrıştırma işlemini izlemeniz gerekir.
Örneğin, aşağıda verilen kodda, dizedeki özel karakterler benim_dizem, hangileri, ',' Ve ':’ tanımlanır. Ayrıştırma metninde x hatasını önlemek için bu işlem dikkatli bir şekilde yapılmalıdır.
Örneğin, dize, split komutu kullanılarak tanımlanan özel karakterlere dayalı olarak metin veri değerlerine bölünür.
Yukarıda açıklanan işlem için örnek kod aşağıda verilmiştir.
my_string = 'İsimler: Teknoloji, bilgisayar'sfinal = [my_string.split(':')[1].split(',')] içindeki ad için [name.strip()]print(“İsimler: {}”.format (sfinal))
Bu durumda, ayrıştırılan dizenin sonucu aşağıda gösterildiği gibi görüntülenecektir.
İsimler: ['Teknoloji', 'bilgisayar']
Daha iyi netlik elde etmek ve dize metnini kullanırken metnin nasıl ayrıştırılacağını öğrenmek için, bir için döngü kullanılır ve kod aşağıdaki gibi değiştirilir.
my_string = 'İsimler: Teknoloji, bilgisayar's1 = my_string.split(':')s2 = s1[1]s3 = s2.split(',')s4 = [s3'teki isim için isim.strip()]idx için, numaralandırılan öğe([s1, s2, s3, s4]):print(“Adım {}: {}”.format (idx, öğe))
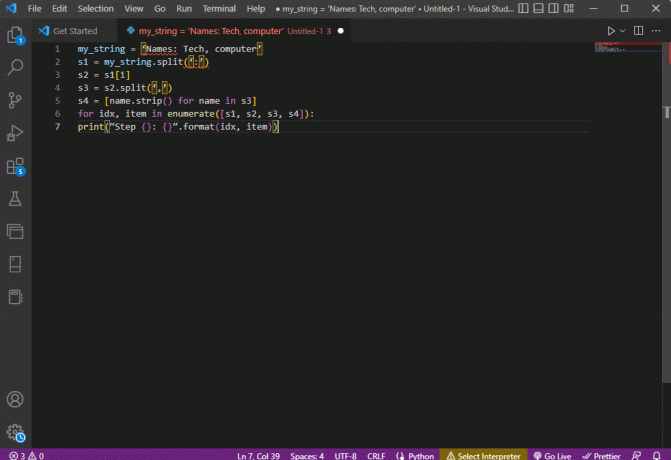
Bu adımların her biri için ayrıştırılan metnin sonucu aşağıda gösterildiği gibi görüntülenir. Adım 0'da dizenin özel karaktere göre ayrıldığını not edebilirsiniz. : ve metin verisi değerleri, sonraki adımlarda karaktere göre ayrılır.
Adım 0: ['İsimler', 'Teknoloji, bilgisayar']1. Adım: Teknoloji, bilgisayar2. Adım: ['Teknoloji', 'bilgisayar']3. Adım: ['Teknoloji', 'bilgisayar']
Seçenek III: Karmaşık Dosyayı Ayrıştırma
Çoğu durumda, ayrıştırılması gereken dosya verileri, değişen veri türleri ve veri değerleri içerir. Bu durumda, daha önce açıklanan yöntemleri kullanarak dosyayı ayrıştırmak zor olabilir.
Dosyadaki karmaşık verileri ayrıştırmanın özellikleri, veri değerlerinin tablo biçiminde görüntülenmesini sağlamaktır.
Bu yöntemde metnin nasıl ayrıştırılacağını öğrenmeye geçmeden önce, birkaç temel kavramı öğrenmek gerekir. Veri değerlerinin ayrıştırılması, normal ifadelere veya Regex'e göre yapılır.
Normal İfade Kalıpları
Ayrıştırma hatasını nasıl düzelteceğinizi bilmek için, ifadelerdeki normal ifade kalıplarının doğru olduğundan emin olmalısınız. Dizelerin veri değerlerini ayrıştırma kodu, bu bölümde aşağıda listelenen yaygın Normal İfade kalıplarını içerecektir.
Düzenli ifadeler
Düzenli ifade modülleri, Python dilindeki pandas paketinin önemli bir parçasıdır ve yanlış bir re, x ayrıştırma metninde bir hataya yol açabilir. İfadedeki dizi desenini bulmak için Python'un içine gömülü küçük bir dildir. Normal İfadeler veya Normal İfadeler, özel sözdizimine sahip dizelerdir. Kullanıcının, dizilerdeki değerlere göre diğer dizilerdeki kalıpları eşleştirmesine izin verir.
Normal ifade, veri türüne ve dizedeki ifadenin gereksinimlerine göre oluşturulur, örneğin: Dize = (.*)\n. Normal ifade, her ifadede kalıptan önce kullanılır. Normal ifadelerde kullanılan semboller aşağıda listelenmiştir ve metnin nasıl ayrıştırılacağını bilmenize yardımcı olacaktır.
Normal İfade Nesneleri
RegexObject, derleme işlevi için bir dönüş değeridir ve ifade eşleşme değeriyle eşleşirse bir MatchObject döndürmek için kullanılır.
1. MatchObject
MatchObject öğesinin Boolean değeri her zaman True olduğundan, bir eğer nesnedeki pozitif eşleşmeleri tanımlamak için ifade. kullanılması durumunda eğer ifadesinde, indeksin başvurduğu grup, ifadedeki nesnenin eşleşmesini bulmak için kullanılır.
2. MatchObject Yöntemleri
Metnin nasıl ayrıştırılacağını bulurken, MatchObject'in aşağıda listelenen iki temel yöntemi olduğunu bilmek önemlidir. Belirtilen ifadede MatchObject bulunursa örneğini döndürür, aksi takdirde Yok'u döndürür.
Normal İfade İşlevleri
Normal İfade İşlevleri, kullanıcı tarafından sağlanan veri değerleri kümesinden belirtilen belirli bir işlevi gerçekleştirmek için kullanılan kod satırlarıdır.
Not: İşlevleri yazmak için, x ayrıştırma metnindeki hatayı önlemek için normal ifadeler için ham dizeler kullanılır. Bu, alt simgeyi ekleyerek yapılır. R ifadedeki her kalıptan önce.
İfadelerde kullanılan ortak işlevler aşağıda açıklanmıştır.
1. re.findall()
Bu işlev, bir eşleşme bulunursa dizedeki tüm kalıpları döndürür ve eşleşme bulunmazsa boş bir liste döndürür. Örneğin, işlev, string = re.findall('[aeiou]', regex_filename) dosya adındaki sesli harfleri bulmak için kullanılır.
2. yeniden.bölünmüş()
Bu işlev, boşluk gibi belirtilen bir karakterle eşleşme olması durumunda dizeyi bölmek için kullanılır. Eşleşme bulunamazsa boş bir dizi döndürür.
3. yeniden.sub()
İşlev, eşleşen metni verilen değiştirme değişkeninin içeriğiyle değiştirir. Diğer fonksiyonların aksine eğer herhangi bir örüntü bulunamazsa orijinal diziye geri döner.
4. araştırma()
Metnin nasıl ayrıştırılacağını öğrenmeye yardımcı olan temel işlevlerden biri arama işlevidir. Dizedeki deseni aramaya ve eşleşen nesneyi döndürmeye yardımcı olur. Arama, eşleşmeyi belirlemede başarısız olursa, hiçbir değer döndürülmez.
5. yeniden derleme (desen)
Bu işlev, düzenli ifade kalıplarını daha önce tartışılan bir RegexObject'e derlemek için kullanılır.
Diğer gereklilikler
Listelenen gereksinimler, ileri düzey programcılar tarafından veri analizinde kullanılan ek bir özelliktir.
Ayrıca Oku:Windows 10'da NumPy Nasıl Kurulur?
Metni Ayrıştırma Süreci
Bu karmaşık seçenekte metni ayrıştırma yöntemi aşağıda verildiği gibi açıklanmıştır.
Komuta veri = pd. Veri Çerçevesi (veri) dict değerlerinden bir panda DataFrame oluşturmak için kullanılır. Alternatif olarak, aşağıda belirtilen ilgili amaç için aşağıdaki komutları kullanabilirsiniz.
Metnin nasıl ayrıştırılacağını bilmenin son adımı, if ifadesi değerleri bir değişkene atayarak veri ve kullanarak yazdırma yazdır (veri) emretmek.
Yukarıdaki açıklama için örnek kod burada verilmiştir.
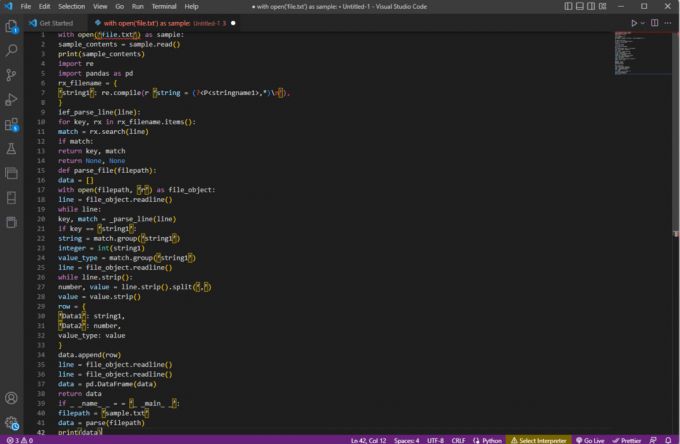
örnek olarak open('file.txt') ile:sample_contents = sample.read()yazdır (örnek_içerikler)yeniden içe aktarpandaları pd olarak içe aktarrx_dosyaadı = {"dize1": yeniden derleme (r "dize = (?,*)\N'),
}ief_parse_line (satır):anahtar için, rx_filename.items() içindeki rx:eşleşme = rx.search (satır)eşleşirse:dönüş anahtarı, maçHiçbiri, Hiçbiridef ayrıştırma_dosyası (dosya yolu):veri = []file_object olarak açık (filepath, 'r') ile:satır = dosya_object.readline()satır sırasında:anahtar, eşleşme = _parse_line (satır)key == 'string1' ise:string = match.group('string1')tamsayı = int (string1)value_type = match.group('string1')satır = dosya_object.readline()line.strip() sırasında:sayı, değer = line.strip().split(',')değer = değer.şerit()satır = {"Veri1": dizi1,'Veri2': sayı,değer_türü: değer}data.append (satır)satır = dosya_object.readline()satır = dosya_object.readline()veri = pd. Veri Çerçevesi (veri)veri döndürme_ _name_ _ = = '_ _main_ _' ise:dosyayolu = 'örnek.txt'veri = ayrıştırma (dosya yolu)yazdır (veri)
Bir metni veya derlemi belirli kurallara dayalı olarak belirteçlere veya daha küçük parçalara dönüştürme işlemine Simgeleştirme denir. Ayrıştırma hatasını nasıl düzelteceğinizi öğrenmek için, koddaki kelime belirteci komutlarını analiz etmek önemlidir. Normal ifadeye benzer şekilde, bu yöntemde kendi kuralları oluşturulabilir ve konuşmanın bölümlerinin eşlenmesi gibi metin ön işleme görevlerinde yardımcı olur. Ayrıca ortak kelimeleri bulma ve eşleştirme, metin temizleme, duygu analizi gibi ileri metin analizi teknikleri için veriyi hazır hale getirme gibi işlemler de bu yöntemde gerçekleştirilir. Belirteçlendirme uygun değilse, x ayrıştırma metninde hata oluşabilir.
NLTK Kitaplığı
Süreç, birçok NLP işini gerçekleştirmek için zengin bir dizi işleve sahip olan NLTK adlı popüler dil araç seti kitaplığının yardımını alır. Bunlar, Pip veya Pip Kurulum Paketleri aracılığıyla indirilebilir. Metnin nasıl ayrıştırılacağını bilmek için, varsayılan olarak kitaplığı içeren Anaconda dağıtımının temel paketini kullanabilirsiniz.
Belirteçleştirme Biçimleri
Bu yöntemin yaygın biçimleri, sözcük belirteçleştirme ve cümle belirteçleştirmedir. Sözcük düzeyinde belirteç sayesinde, ilki yalnızca bir kez bir sözcük yazdırırken, ikincisi sözcüğü cümle düzeyinde yazdırır.
Metni Ayrıştırma Süreci
Yukarıda belirteçleştirme adımlarını açıklayan kod burada verilmiştir.
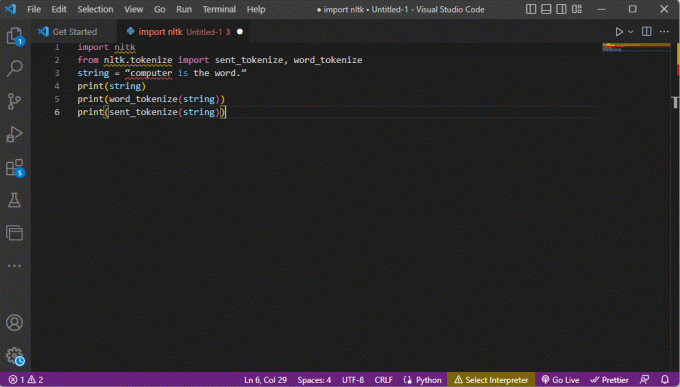
nltk'yi içe aktarnltk.tokenize'den içe aktarma sent_tokenize, word_tokenizestring = "bilgisayar kelimedir."yazdır (dize)yazdır (word_tokenize (dize))yazdır (sent_tokenize (dize))
Ayrıca Oku:JavaScript Nasıl Onarılır: geçersiz (0) Hatası
DataFrame Sınıfına benzer şekilde, Koddaki metni ayrıştırmak için DocParser Sınıfı kullanılabilir. Sınıf, filepath ile ayrıştırma işlevini çağırmanıza izin verir.
Metni Ayrıştırma Süreci
DocParser Sınıfını kullanarak metnin nasıl ayrıştırılacağını öğrenmek için aşağıda verilen talimatları izleyin.
Not: Ayrıştırma hatasını nasıl düzelteceğinizi bilmek için bu işlevin doğru şekilde uygulanması gerekir.
Metni Ayrıştır aracı, değişkenlerden belirli verileri çıkarmak ve bunları diğer değişkenlerle eşlemek için kullanılır. Bu, bir görevde kullanılan diğer araçlardan bağımsızdır ve değişkenleri tüketmek ve çıktısını almak için BPA Platform aracı kullanılır. erişmek için burada verilen bağlantıyı kullanın Çevrimiçi Metin Aracını Ayrıştır ve metnin nasıl ayrıştırılacağı konusunda daha önce verilen cevapları kullanın.

TextFieldParser, yapılandırılmış ve sınırlandırılmış çok büyük dosyaları ayrıştırmak ve işlemek için nesneleri kullandı. Günlük dosyaları veya eski veritabanı bilgileri gibi metnin genişliği ve sütunu bu yöntemde kullanılabilir. Ayrıştırma yöntemi, kodu bir metin dosyası üzerinde yinelemeye benzer ve esas olarak dize işleme yöntemlerine benzer metin alanlarını ayıklamak için kullanılır. Bu, virgül veya sekme alanı gibi tanımlanmış sınırlayıcıyı kullanarak çeşitli genişliklerdeki ayrılmış dizeleri ve alanları simgelemek için yapılır.
Metni Ayrıştırma İşlevleri
Bu yöntemde metni ayrıştırmak için aşağıdaki işlevler kullanılabilir.
MatchObject'i Bulma Yöntemleri
Kodda veya ayrıştırılmış metinde MatchObject'i bulmanın iki temel yöntemi vardır.
Her iki durumda da, ayrıştırma yapılırken veya metnin nasıl ayrıştırılacağını bulurken bir alan belirtilen formatla eşleşmezse, bir alan MalformedLineException istisna döndürülür.
Metni ayrıştırmak için son ve basit bir yöntem olarak, Excel sekmeyle ayrılmış ve virgülle ayrılmış dosyalar oluşturmak için ayrıştırıcı olarak kullanın. Bu, ayrıştırılan sonucunuzu çapraz kontrol etmenize ve ayrıştırma hatasını nasıl düzelteceğinizi bulmanıza yardımcı olur.
1. Kaynak dosyadaki veri değerlerini seçin ve Ctrl + C tuşları birlikte dosyayı kopyalamak için.
2. Aç excel Windows arama çubuğunu kullanarak uygulama.

3. Tıkla A1 hücreye basın ve Ctrl + V tuşları kopyalanan metni yapıştırmak için aynı anda
4. seçin A1 hücreye git Veri sekmesine tıklayın ve Sütunlara metin seçeneği Veri Araçları bölüm.
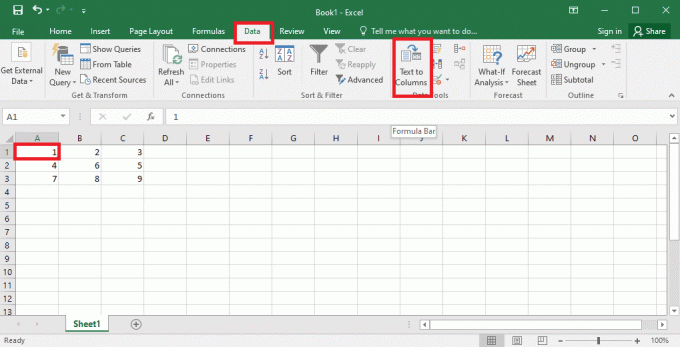
5A. seçin sınırlandırılmış seçenek eğer bir virgül veya sekme boşluk ayırıcı olarak kullanılır ve üzerine tıklayın Sonraki Ve Sona ermek düğmeler.

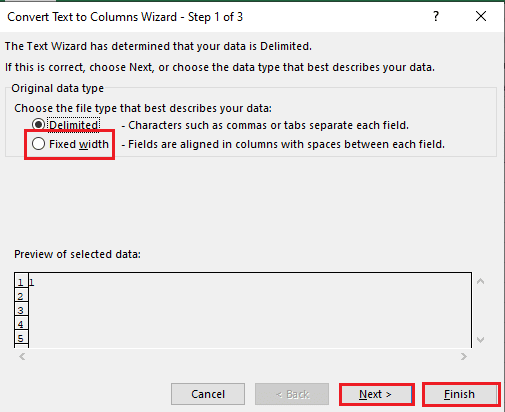
5B. seçin Sabit genişlik seçeneği, ayırıcı için bir değer atayın ve tıklayın Sonraki Ve Sona ermek düğmeler.
Ayrıca Oku:Excel Sütununu Taşı Hatası Nasıl Onarılır
Ayrıştırma metninde x hatası, Android cihazlarda şu şekilde oluşabilir: Ayrıştırma Hatası: Paket ayrıştırılırken bir sorun oluştu. Bu genellikle, uygulama Google Play Store'dan yüklenemediğinde veya üçüncü taraf bir uygulama çalıştırılırken meydana gelir.
Karakter vektörleri listesi döngü halindeyse ve diğer işlevler veri değerlerini hesaplamak için doğrusal bir model oluşturuyorsa x hata metni oluşabilir. Hata mesajı Ayrıştırmada hatadır (metin = x, keep.source = FALSE):
adresindeki makaleyi okuyabilirsiniz. Android'de ayrıştırma hatası nasıl düzeltilir hatanın nedenlerini ve düzeltme yöntemlerini öğrenmek.
Kılavuzdaki çözümlerin dışında aşağıdaki düzeltmeleri deneyebilirsiniz.
Tavsiye edilen:
Makale öğretmeye yardımcı olur metin nasıl ayrıştırılır ve ayrıştırma hatasını nasıl düzelteceğinizi öğrenmek için. X ayrıştırma metnindeki hatayı düzeltmeye hangi yöntemin yardımcı olduğunu ve hangi ayrıştırma yönteminin tercih edildiğini bize bildirin. Lütfen önerilerinizi ve sorularınızı aşağıdaki yorumlar bölümünde paylaşın.

