
16/02/2022

몇 가지 컴퓨터 프로그래밍 언어를 배웠다면 텍스트 구문 분석이라는 용어를 들었을 것입니다. 이것은 파일의 복잡한 데이터 값을 단순화하는 데 사용됩니다. 이 기사는 언어를 사용하여 텍스트를 구문 분석하는 방법을 아는 데 도움이 됩니다. 이 외에도 구문 분석 x에서 오류가 발생한 경우 문서에서 구문 분석 오류를 수정하는 방법을 알 수 있습니다.
목차
이 기사에서는 다양한 방법을 통해 텍스트를 파싱하는 전체 가이드를 보여주고 텍스트 파싱에 대한 간략한 소개도 제공했습니다.
코드를 사용하여 텍스트를 구문 분석하는 개념을 배우기 전에 탐구하십시오. 언어와 코딩의 기본에 대해 아는 것이 중요합니다.
텍스트를 파싱하기 위해서는 인공지능 영역의 하위 분야인 자연어 처리(Natural Language Processing, NLP)가 활용된다. 범주에 속하는 언어 중 하나인 Python 언어는 텍스트를 구문 분석하는 데 사용됩니다.
NLP 코드를 사용하면 컴퓨터가 인간의 언어를 이해하고 처리하여 다양한 응용 프로그램에 적합하도록 만들 수 있습니다. 언어에 ML 또는 기계 학습 기술을 적용하려면 구조화되지 않은 텍스트 데이터를 구조화된 테이블 형식 데이터로 변환해야 합니다. 구문 분석 활동을 완료하기 위해 Python 언어를 사용하여 프로그램 코드를 변경합니다.
텍스트 구문 분석은 단순히 데이터를 한 형식에서 다른 형식으로 변환하는 것을 의미합니다. 파일이 저장되는 형식은 사용자가 다양한 응용 프로그램에서 사용할 수 있도록 파싱되거나 다른 형식의 파일로 변환됩니다.
텍스트를 구문 분석해야 하는 이유는 이 섹션에 나와 있으며 텍스트를 구문 분석하는 방법을 알기 전에 전제 조건 지식입니다.
Python 언어의 DataFrame 클래스에는 텍스트를 구문 분석하는 데 필요한 모든 기능이 있습니다. 이 내장 라이브러리에는 모든 형식의 데이터를 다른 형식으로 구문 분석하는 데 필요한 코드가 있습니다.
DataFrame 클래스에 대한 간략한 소개
DataFrame 클래스는 기능이 풍부한 데이터 구조로 데이터 분석 도구로 사용됩니다. 이것은 최소한의 노력으로 데이터를 분석하는 데 사용할 수 있는 강력한 데이터 분석 도구입니다.
Python 언어의 pandas는 구문 분석 x에서 오류를 피하기 위해 SQL 또는 데이터베이스 스타일 작업을 완벽하게 수행하는 데 도움이 됩니다. 또한 CSV, MS Excel, JSON, HDF5 및 기타 데이터 형식의 파일을 분석하는 데 도움이 되는 몇 가지 IO 도구가 포함되어 있습니다.
또한 읽기:프록시 요청을 시도하는 동안 발생한 수정 오류
DataFrame 클래스를 이용한 텍스트 파싱 과정
텍스트를 구문 분석하는 방법을 알기 위해 이 섹션에 제공된 DataFrame 클래스를 사용하는 표준 프로세스를 사용할 수 있습니다.
메모: 빈 DataFrame에 코드를 작성하는 것은 지루하고 복잡할 수 있습니다. 팬더는 이러한 데이터 유형에서 DataFrame 클래스의 데이터를 생성할 수 있습니다. 따라서 기본 데이터 유형의 데이터를 필요한 데이터 형식으로 쉽게 구문 분석할 수 있습니다.
옵션 I: 표준 형식
CSV와 같은 특정 데이터 형식으로 파일을 형식화하는 표준 방법은 여기에서 설명합니다.
메모: 여기서 변수라는 이름은 입술 수행하는 데 사용됩니다. 읽다 파일에 있는 데이터의 기능 data.txt 에서 가져온 팬더 사용 pd. 입력 텍스트의 데이터 형식은 CSV 체재.
위에서 설명한 프로세스에 대한 예제 코드가 아래에 나와 있으며 텍스트를 구문 분석하는 방법을 이해하는 데 도움이 됩니다.
판다를 pd로 가져오기해상도 = pd.read_csv('data.txt')입술
이때 파일에 데이터 값을 입력하면 data.txt ~와 같은 [1,2,3], 구문 분석되어 다음과 같이 표시됩니다. 1 2 3.
옵션 II: 문자열 방법
코드에 주어진 텍스트가 문자열이나 알파 문자만 포함하는 경우 쉼표, 공백 등과 같은 문자열의 특수 문자를 사용하여 텍스트를 구분하고 구문 분석할 수 있습니다. 프로세스는 일반적인 내부 문자열 작업과 유사합니다. 구문 분석 오류를 수정하는 방법을 찾으려면 아래에 설명된 이 옵션을 사용하여 텍스트를 구문 분석하는 프로세스를 따라야 합니다.
예를 들어, 아래 제공된 코드에서 문자열의 특수 문자는 my_string, 이는 ',' 그리고 ':’로 식별된다. 이 프로세스는 구문 분석 텍스트 x에서 오류를 피하기 위해 신중하게 수행되어야 합니다.
예를 들어 문자열은 split 명령을 사용하여 식별된 특수 문자를 기반으로 텍스트 데이터 값으로 분할됩니다.
위에서 설명한 프로세스의 샘플 코드는 다음과 같습니다.
my_string = '이름: 기술, 컴퓨터'sfinal = [my_string.split(':')[1].split(',')의 이름에 대한 name.strip()]print("이름: {}".format(최종))
이 경우 파싱된 문자열의 결과는 아래와 같이 표시됩니다.
이름: ['기술', '컴퓨터']
명확성을 높이고 문자열 text를 사용하는 동안 텍스트를 구문 분석하는 방법을 알기 위해 ~을 위한 루프를 활용하여 다음과 같이 코드를 수정합니다.
my_string = '이름: 기술, 컴퓨터's1 = my_string.split(':')s2 = s1[1]s3 = s2.분할(',')s4 = [s3의 이름에 대한 name.strip()]idx의 경우 enumerate([s1, s2, s3, s4])의 항목:print(“{}단계: {}”.format(idx, 항목))
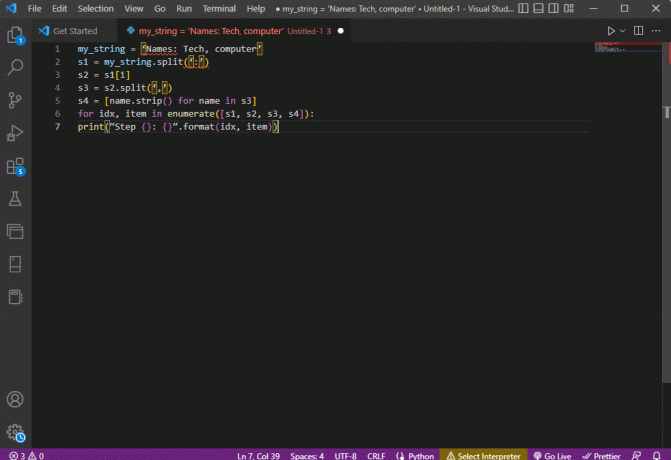
이러한 각 단계에 대한 구문 분석된 텍스트의 결과는 아래와 같이 표시됩니다. 0단계에서 특수 문자를 기준으로 문자열이 구분됨을 알 수 있습니다. : 텍스트 데이터 값은 추가 단계에서 문자를 기준으로 분리됩니다.
0단계: ['이름', '기술, 컴퓨터']1단계: 기술, 컴퓨터2단계: ['기술', '컴퓨터']3단계: ['기술', '컴퓨터']
옵션 III: 복잡한 파일 구문 분석
대부분의 경우 구문 분석해야 하는 파일 데이터에는 다양한 데이터 유형과 데이터 값이 포함됩니다. 이 경우 앞에서 설명한 방법을 사용하여 파일을 구문 분석하기 어려울 수 있습니다.
파일의 복잡한 데이터를 구문 분석하는 기능은 데이터 값을 표 형식으로 표시하는 것입니다.
이 방법으로 텍스트를 구문 분석하는 방법을 알아보기 전에 몇 가지 기본 개념을 배워야 합니다. 데이터 값의 구문 분석은 정규식 또는 Regex를 기반으로 수행됩니다.
정규식 패턴
구문 분석 오류를 수정하는 방법을 알려면 표현식의 정규식 패턴이 적절한지 확인해야 합니다. 문자열의 데이터 값을 구문 분석하는 코드에는 이 섹션 아래에 나열된 일반적인 Regex 패턴이 포함됩니다.
정규 표현식
정규식 모듈은 Python 언어의 pandas 패키지의 주요 부분이며 잘못된 re는 구문 분석 텍스트 x에서 오류로 이어질 수 있습니다. 표현식에서 문자열 패턴을 찾기 위해 Python에 내장된 작은 언어입니다. 정규식 또는 Regex는 특수 구문이 있는 문자열입니다. 이를 통해 사용자는 문자열의 값을 기반으로 다른 문자열의 패턴을 일치시킬 수 있습니다.
Regex는 다음과 같은 문자열의 표현식 요구 사항 및 데이터 유형을 기반으로 생성됩니다. 문자열 = (.*)\n. 정규식은 모든 식에서 패턴 앞에 사용됩니다. 정규식에 사용되는 기호는 아래에 나열되어 있으며 텍스트를 구문 분석하는 방법을 아는 데 도움이 됩니다.
Regex객체
RegexObject는 컴파일 함수의 반환 값이며 표현식이 일치 값과 일치하는 경우 MatchObject를 반환하는 데 사용됩니다.
1. MatchObject
MatchObject의 부울 값은 항상 True이므로 다음을 사용할 수 있습니다. 만약에 개체에서 긍정적인 일치 항목을 식별하는 문입니다. 를 사용하는 경우 만약에 문에서 인덱스가 참조하는 그룹은 식에서 개체의 일치를 찾는 데 사용됩니다.
2. MatchObject의 메서드
텍스트를 구문 분석하는 방법을 찾는 동안 MatchObject에는 아래 나열된 두 가지 기본 메서드가 있음을 아는 것이 중요합니다. MatchObject가 지정된 표현식에서 발견되면 해당 인스턴스를 반환하고 그렇지 않으면 None을 반환합니다.
정규 표현식 함수
Regex 함수는 조달된 데이터 값 세트에서 사용자가 지정한 특정 기능을 수행하는 데 사용되는 코드 라인입니다.
메모: 함수를 작성하기 위해 구문 분석 x에서 오류를 방지하기 위해 정규식에 원시 문자열이 사용됩니다. 이것은 아래 첨자를 추가하여 수행됩니다. 아르 자형 표현식의 각 패턴 앞에.
식에 사용되는 일반적인 함수는 아래에 설명되어 있습니다.
1. re.findall()
이 함수는 일치하는 항목이 있으면 문자열의 모든 패턴을 반환하고 일치하는 항목이 없으면 빈 목록을 반환합니다. 예를 들어, 함수, string = re.findall('[aeiou]', regex_filename) 파일 이름에서 모음 발생을 찾는 데 사용됩니다.
2. re.split()
이 기능은 공백과 같이 지정된 문자와 일치하는 경우 문자열을 분할하는 데 사용됩니다. 일치하는 항목이 없으면 빈 문자열을 반환합니다.
3. re.sub()
이 함수는 일치하는 텍스트를 주어진 대체 변수의 내용으로 대체합니다. 다른 함수와 달리 패턴이 없으면 원래 문자열이 반환됩니다.
4. 연구()
텍스트를 파싱하는 방법을 배우는 데 도움이 되는 기본 기능 중 하나는 검색 기능입니다. 문자열에서 패턴을 검색하고 일치 개체를 반환하는 데 도움이 됩니다. 검색에서 일치 항목 식별에 실패하면 값이 반환되지 않습니다.
5. 재컴파일(패턴)
이 함수는 앞에서 설명한 정규식 패턴을 RegexObject로 컴파일하는 데 사용됩니다.
기타 요구 사항
나열된 요구 사항은 데이터 분석에서 고급 프로그래머가 사용하는 추가 기능입니다.
또한 읽기:Windows 10에 NumPy를 설치하는 방법
텍스트 파싱 프로세스
이 복잡한 옵션에서 텍스트를 구문 분석하는 방법은 아래에 설명되어 있습니다.
명령 데이터 = pd. 데이터프레임(데이터) dict 값에서 pandas DataFrame을 만드는 데 사용됩니다. 또는 아래에 설명된 대로 각각의 목적에 따라 다음 명령을 사용할 수 있습니다.
텍스트를 구문 분석하는 방법을 알기 위한 마지막 단계는 다음을 사용하여 구문 분석기를 테스트하는 것입니다. if 문 변수에 값을 할당하여 데이터 그리고 그것을 사용하여 인쇄 인쇄(데이터) 명령.
위의 설명에 대한 예제 코드는 여기에 제공됩니다.
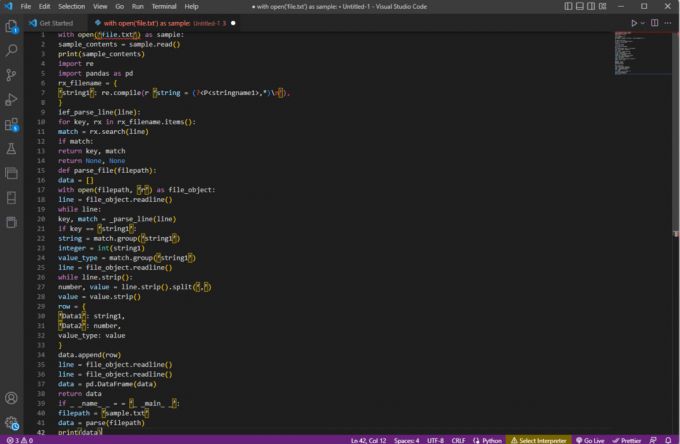
샘플로 open('file.txt') 포함:sample_contents = 샘플.읽기()인쇄(sample_contents)다시 가져오기판다를 pd로 가져오기rx_filename = {'문자열1': re.compile(r '문자열 = (?,*)\N'),
}ief_parse_line(라인):키의 경우 rx_filename.items()의 rx:일치 = rx.search(라인)일치하는 경우:리턴 키, 매치반환 없음, 없음def parse_file(파일 경로):데이터 = []open(파일 경로, 'r')을 file_object로 사용:라인 = file_object.readline()동안 라인:키, 일치 = _parse_line(라인)키 == '문자열1'인 경우:문자열 = 일치.그룹('문자열1')정수 = 정수(문자열1)value_type = match.group('문자열1')라인 = file_object.readline()동안 line.strip():숫자, 값 = line.strip().split(',')값 = 값.스트립()행 = {'데이터1': 문자열1,'데이터2': 숫자,값_유형: 값}데이터.추가(행)라인 = file_object.readline()라인 = file_object.readline()데이터 = pd. 데이터프레임(데이터)반환 데이터_ _name_ _ = = '_ _main_ _'인 경우:파일 경로 = 'sample.txt'데이터 = 구문 분석(파일 경로)인쇄(데이터)
특정 규칙에 따라 텍스트 또는 말뭉치를 토큰 또는 더 작은 조각으로 변환하는 프로세스를 토큰화라고 합니다. 구문 분석 오류를 수정하는 방법을 배우려면 코드에서 단어 토큰화 명령을 분석하는 것이 중요합니다. 정규식과 유사하게 이 방법으로 자체 규칙을 만들 수 있으며 품사 매핑과 같은 텍스트 사전 처리 작업에 도움이 됩니다. 또한 일반적인 단어 찾기 및 일치, 텍스트 정리, 감정 분석과 같은 고급 텍스트 분석 기술을 위한 데이터 준비와 같은 활동이 이 방법으로 수행됩니다. 토큰화가 부적절하면 파싱 텍스트 x에 오류가 발생할 수 있습니다.
NLTK 라이브러리
이 프로세스는 많은 NLP 작업을 수행하기 위한 풍부한 기능 세트가 있는 NLTK라는 인기 있는 언어 툴킷 라이브러리의 도움을 받습니다. Pip 또는 Pip 설치 패키지를 통해 다운로드할 수 있습니다. 텍스트를 구문 분석하는 방법을 알려면 기본적으로 라이브러리가 포함된 Anaconda 배포판의 기본 팩을 사용할 수 있습니다.
토큰화의 형태
이 방법의 일반적인 형태는 단어 토큰화와 문장 토큰화입니다. 단어 수준 토큰으로 인해 전자는 한 단어를 한 번만 인쇄하고 후자는 문장 수준에서 단어를 인쇄합니다.
텍스트 파싱 프로세스
위의 토큰화 단계를 설명하는 코드는 여기에 나와 있습니다.
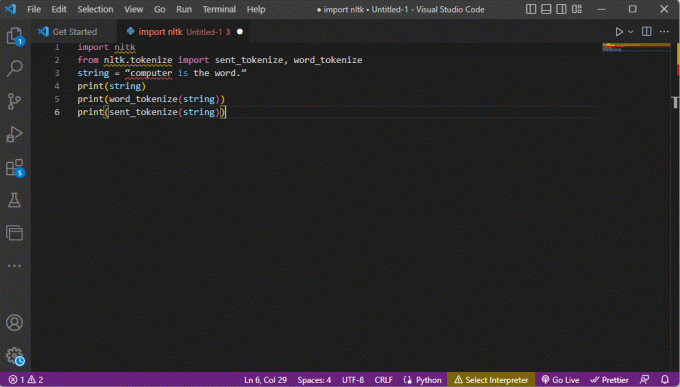
nltk 가져오기from nltk.tokenize 가져오기 sent_tokenize, word_tokenizestring = "컴퓨터가 곧 단어입니다."인쇄(문자열)인쇄(word_tokenize(문자열))인쇄(sent_tokenize(문자열))
또한 읽기:javascript 수정 방법: 무효(0) 오류
DataFrame 클래스와 마찬가지로 DocParser 클래스를 사용하여 코드의 텍스트를 구문 분석할 수 있습니다. 이 클래스를 사용하면 파일 경로로 구문 분석 함수를 호출할 수 있습니다.
텍스트 파싱 프로세스
DocParser 클래스를 사용하여 텍스트를 구문 분석하는 방법을 알려면 아래 지침을 따르십시오.
메모: 구문 분석 오류를 수정하는 방법을 알려면 이 기능을 올바르게 구현해야 합니다.
구문 분석 텍스트 도구는 변수에서 특정 데이터를 추출하고 다른 변수에 매핑하는 데 사용됩니다. 이것은 작업에 사용되는 다른 도구와 독립적이며 BPA 플랫폼 도구는 변수를 사용하고 출력하는 데 사용됩니다. 여기에 제공된 링크를 사용하여 텍스트 도구 온라인 분석 텍스트를 구문 분석하는 방법에 대해 이전에 제공된 답변을 사용하십시오.

TextFieldParser는 개체를 활용하여 구조화되고 구분된 매우 큰 파일을 구문 분석하고 처리합니다. 로그 파일이나 레거시 데이터베이스 정보와 같은 텍스트의 너비와 열을 이 방법으로 사용할 수 있습니다. 구문 분석 방법은 텍스트 파일에서 코드를 반복하는 것과 유사하며 주로 문자열 조작 방법과 유사한 텍스트 필드를 추출하는 데 사용됩니다. 이는 쉼표 또는 탭 공백과 같은 정의된 구분 기호를 사용하여 다양한 너비의 구분된 문자열 및 필드를 토큰화하기 위해 수행됩니다.
텍스트를 파싱하는 함수
다음 함수를 사용하여 이 메서드에서 텍스트를 구문 분석할 수 있습니다.
MatchObject를 찾는 방법
코드 또는 구문 분석된 텍스트에서 MatchObject를 찾는 두 가지 기본 방법이 있습니다.
두 경우 모두 구문 분석을 수행하거나 텍스트를 구문 분석하는 방법을 찾는 동안 필드가 지정된 형식과 일치하지 않으면 MalformedLineException 예외가 반환됩니다.
텍스트를 구문 분석하는 최종적이고 간단한 방법으로 다음을 사용할 수 있습니다. MS 엑셀 탭으로 구분된 파일과 쉼표로 구분된 파일을 생성하는 파서로서의 앱. 이렇게 하면 구문 분석된 결과와 교차 확인하고 구문 분석 오류를 수정하는 방법을 찾는 데 도움이 됩니다.
1. 소스 파일에서 데이터 값을 선택하고 Ctrl + C 키 함께 파일을 복사합니다.
2. 열기 뛰어나다 Windows 검색 창을 사용하는 앱.

3. 를 클릭하십시오 A1 셀을 누르고 Ctrl + V 키 복사한 텍스트를 동시에 붙여넣습니다.
4. 선택 A1 셀에서 다음으로 이동합니다. 데이터 탭을 클릭하고 텍스트를 열로 의 옵션 데이터 도구 부분.
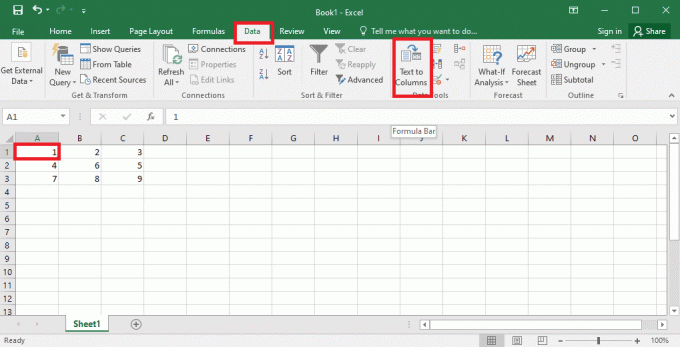
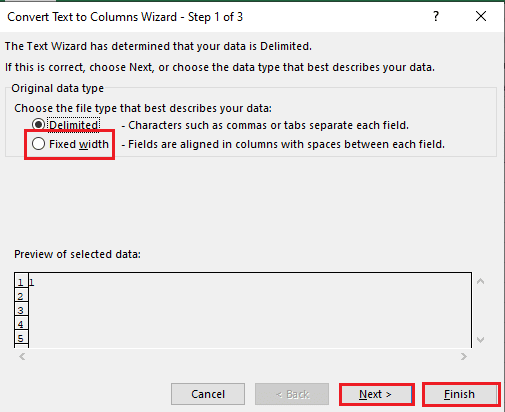
5A. 선택 구분 옵션인 경우 반점 또는 탭 공백이 구분 기호로 사용되며 다음 그리고 마치다 버튼.

5B. 선택 고정 폭 옵션에서 구분 기호에 대한 값을 할당하고 다음 그리고 마치다 버튼.
또한 읽기:Excel 열 이동 오류를 수정하는 방법
구문 분석 텍스트 x의 오류는 Android 장치에서 다음과 같이 발생할 수 있습니다. 구문 분석 오류: 패키지 구문 분석에 문제가 발생했습니다. 이는 일반적으로 앱이 Google Play 스토어에서 설치되지 않거나 타사 앱을 실행하는 동안 발생합니다.
오류 텍스트 x는 문자형 벡터 목록이 반복되고 다른 함수가 데이터 값을 계산하기 위한 선형 모델을 형성하는 경우 발생할 수 있습니다. 오류 메시지는 Error in parse(text = x, keep.source = FALSE)입니다.
에서 기사를 읽을 수 있습니다. Android에서 구문 분석 오류를 수정하는 방법 오류의 원인과 해결 방법을 알아봅니다.
가이드의 해결 방법 외에도 다음 수정 사항을 시도해 볼 수 있습니다.
추천:
이 기사는 교육에 도움이됩니다 텍스트를 파싱하는 방법 구문 분석 오류를 수정하는 방법을 배웁니다. 구문 분석 x에서 오류를 수정하는 데 어떤 방법이 도움이 되었으며 어떤 구문 분석 방법이 선호되는지 알려주세요. 아래 의견 섹션에서 제안 및 질문을 공유하십시오.

