
0
Názory

Ak ste sa naučili niekoľko počítačových programovacích jazykov, možno ste už počuli výraz analyzovať text. Používa sa na zjednodušenie komplexných dátových hodnôt súboru. Tento článok vám pomôže zistiť, ako analyzovať text pomocou jazyka. Okrem toho, ak ste narazili na chybu pri analýze textu x, budete vedieť, ako opraviť chybu analýzy v článku.
Obsah
V tomto článku sme ukázali úplného sprievodcu analýzou textu rôznymi spôsobmi a tiež stručne predstavili analýzu textu.
Pred ponorením sa naučte koncepty analýzy textu pomocou ľubovoľného kódu. Je dôležité vedieť o základoch jazyka a kódovaní.
Na analýzu textu sa používa spracovanie prirodzeného jazyka alebo NLP, čo je podpole domény umelej inteligencie. Na analýzu textu sa používa jazyk Python, ktorý je jedným z jazykov patriacich do tejto kategórie.
Kódy NLP umožňujú počítačom porozumieť a spracovať ľudské jazyky tak, aby boli vhodné pre rôzne aplikácie. Ak chcete na jazyk aplikovať techniky ML alebo strojového učenia, neštruktúrované textové údaje sa musia previesť na štruktúrované tabuľkové údaje. Na dokončenie aktivity analýzy sa na zmenu programových kódov používa jazyk Python.
Analýza textu jednoducho znamená konverziu údajov z jedného formátu do iného formátu. Formát, v ktorom je súbor uložený, sa musí analyzovať alebo previesť na súbor v inom formáte, aby ho používateľ mohol používať v rôznych aplikáciách.
Dôvody, pre ktoré musí byť text analyzovaný, sú uvedené v tejto časti a je to nevyhnutná znalosť predtým, ako budete vedieť, ako analyzovať text.
Trieda DataFrame jazyka Python má všetky potrebné funkcie na analýzu textu. Táto vstavaná knižnica obsahuje potrebné kódy na analýzu údajov akéhokoľvek formátu do iného formátu.
Stručné predstavenie triedy DataFrame
DataFrame Class je dátová štruktúra bohatá na funkcie, ktorá sa používa ako nástroj na analýzu dát. Ide o výkonný nástroj na analýzu údajov, ktorý možno použiť na analýzu údajov s minimálnym úsilím.
Pandy jazyka Python pomáhajú pri vykonávaní operácií v štýle SQL alebo databázy s maximálnou dokonalosťou, aby sa predišlo chybám pri analýze textu x. Obsahuje tiež niektoré IO nástroje, ktoré pomáhajú pri analýze súborov CSV, MS Excel, JSON, HDF5 a iných dátových formátov.
Prečítajte si tiež:Opravte chybu, ktorá sa vyskytla pri pokuse o proxy požiadavku
Proces analýzy textu pomocou triedy DataFrame
Ak chcete vedieť, ako analyzovať text, môžete použiť štandardný proces s použitím triedy DataFrame uvedenej v tejto časti.
Poznámka: Písanie kódu na prázdny DataFrame môže byť únavné a zložité. Pandy umožňujú vytvárať údaje v triede DataFrame z týchto typov údajov. Dáta v primitívnom dátovom type teda možno ľahko analyzovať na požadovaný dátový formát.
Možnosť I: Štandardný formát
Tu je vysvetlená štandardná metóda na formátovanie ľubovoľného súboru s určitým formátom údajov, ako je napríklad CSV.
Poznámka: Tu je pomenovaná premenná res sa používa na vykonávanie čítať funkcie údajov v súbore data.txt pomocou dovezených pand pd. Dátový formát vstupného textu je špecifikovaný v CSV formát.
Príklad kódu pre proces vysvetlený vyššie je uvedený nižšie a pomôže vám pochopiť, ako analyzovať text.
importovať pandy ako pdres = pd.read_csv(‘data.txt’)res
V tomto prípade, ak zadáte hodnoty údajov do súboru data.txt ako napr [1,2,3], bude analyzovaný a zobrazený ako 1 2 3.
Možnosť II: Reťazcová metóda
Ak text zadaný do kódu obsahuje iba reťazce alebo alfa znaky, špeciálne znaky v reťazci, ako sú čiarky, medzery atď., možno použiť na oddelenie a analýzu textu. Proces je podobný bežným operáciám s internými reťazcami. Ak chcete zistiť, ako opraviť chybu analýzy, musíte postupovať podľa procesu analýzy textu pomocou tejto možnosti, ktorá je vysvetlená nižšie.
Napríklad v nižšie uvedenom kóde sú to špeciálne znaky v reťazci môj_reťazec, ktoré sú, ',“ a „:“ sú identifikované. Tento proces je potrebné vykonať opatrne, aby sa predišlo chybám pri analýze textu x.
Napríklad reťazec je rozdelený na hodnoty textových údajov na základe špeciálnych znakov identifikovaných pomocou príkazu split.
Vzorový kód pre proces vysvetlený vyššie je uvedený nižšie.
my_string = 'Názvy: Technika, počítač'sfinal = [name.strip() pre meno v my_string.split(‘:’)[1].split(‘,’)]print(“Mená: {}”.formát (konečný))
V tomto prípade by sa výsledok analyzovaného reťazca zobrazil tak, ako je uvedené nižšie.
Mená: [‘Tech‘, ‚computer‘]
Ak chcete získať lepšiu prehľadnosť a vedieť, ako analyzovať text pri použití textu reťazca, a pre použije sa slučka a kód sa upraví nasledovne.
my_string = 'Názvy: Technika, počítač's1 = my_string.split(‘:’)s2 = s1[1]s3 = s2.split(‘,’)s4 = [name.strip() pre meno v s3]pre idx, položka v enumerate([s1, s2, s3, s4]):print(“Krok {}: {}”.format (idx, item))
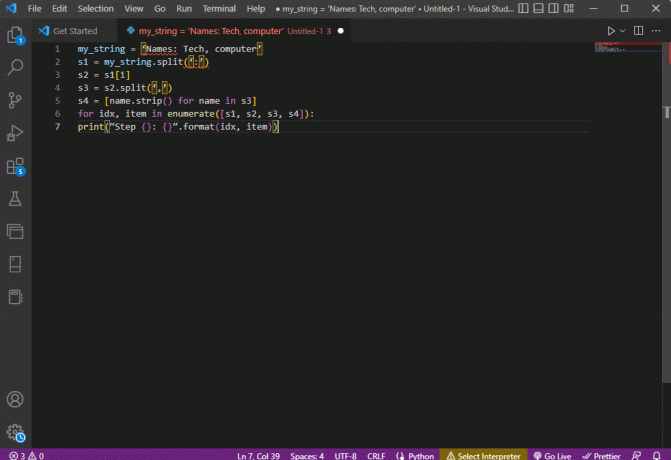
Výsledok analyzovaného textu pre každý z týchto krokov sa zobrazí, ako je uvedené nižšie. Môžete si všimnúť, že v kroku 0 je reťazec oddelený na základe špeciálneho znaku : a hodnoty textových údajov sa v ďalších krokoch oddelia na základe znaku.
Krok 0: [‚Mená‘, ‚Tech, počítač‘]Krok 1: Technika, počítačKrok 2: [‘ Tech‘, ‚ computer‘]Krok 3: [‚Tech‘, ‚computer‘]
Možnosť III: Analýza komplexného súboru
Vo väčšine prípadov údaje súboru, ktoré je potrebné analyzovať, obsahujú rôzne typy údajov a hodnoty údajov. V tomto prípade môže byť ťažké analyzovať súbor pomocou metód vysvetlených vyššie.
Funkciou analýzy komplexných údajov v súbore je umožniť zobrazenie údajových hodnôt v tabuľkovom formáte.
Predtým, ako sa ponoríme do toho, ako analyzovať text touto metódou, je potrebné naučiť sa niekoľko základných pojmov. Analýza hodnôt údajov sa vykonáva na základe regulárnych výrazov alebo regulárneho výrazu.
Vzory regulárneho výrazu
Ak chcete vedieť, ako opraviť chybu analýzy, musíte sa uistiť, že vzory regulárnych výrazov vo výrazoch sú správne. Kód na analýzu údajových hodnôt reťazcov by zahŕňal bežné vzory Regex uvedené nižšie v tejto časti.
Regulárne výrazy
Moduly regulárnych výrazov sú hlavnou súčasťou balíka pandas v jazyku Python a nesprávne re môže viesť k chybe pri analýze textu x. Je to malý jazyk vložený do Pythonu na nájdenie vzoru reťazca vo výraze. Regulárne výrazy alebo regulárny výraz sú reťazce so špeciálnou syntaxou. Umožňuje používateľovi porovnávať vzory v iných reťazcoch na základe hodnôt v reťazcoch.
Regex je vytvorený na základe dátového typu a požiadavky na výraz v reťazci, ako napr Reťazec = (.*)\n. Regulárny výraz sa používa pred vzorom v každom výraze. Symboly používané v regulárnych výrazoch sú uvedené nižšie a pomôžu vám zistiť, ako analyzovať text.
RegexObjects
RegexObject je návratová hodnota pre funkciu kompilácie a používa sa na vrátenie MatchObject, ak sa výraz zhoduje s hodnotou zhody.
1. MatchObject
Keďže boolovská hodnota MatchObject je vždy True, môžete použiť an ak na identifikáciu pozitívnych zhôd v objekte. V prípade použitia ak výraz, skupina, na ktorú sa index odkazuje, sa používa na zistenie zhody objektu vo výraze.
2. Metódy MatchObject
Pri hľadaní spôsobu analýzy textu je dôležité vedieť, že MatchObject má dve základné metódy, ako sú uvedené nižšie. Ak sa MatchObject nájde v zadanom výraze, vráti svoju inštanciu, inak by vrátil None.
Funkcie regulárnych výrazov
Funkcie regulárneho výrazu sú riadky kódu, ktoré sa používajú na vykonanie určitej funkcie špecifikovanej používateľom zo sady získaných údajových hodnôt.
Poznámka: Na písanie funkcií sa pre regulárne výrazy používajú nespracované reťazce, aby sa predišlo chybám pri analýze textu x. To sa vykonáva pridaním dolného indexu r pred každým vzorom vo výraze.
Bežné funkcie používané vo výrazoch sú vysvetlené nižšie.
1. re.findall()
Táto funkcia vráti všetky vzory v reťazci, ak sa nájde zhoda, a vráti prázdny zoznam, ak sa nenájde žiadna zhoda. Napríklad funkcia, string = re.findall(‘[aeiou]‘, názov_regulárneho_súboru) sa používa na nájdenie výskytu samohlásky v názve súboru.
2. re.split()
Táto funkcia sa používa na rozdelenie reťazca v prípade, že sa nájde zhoda so špecifikovaným znakom, napríklad medzera. V prípade, že sa nenájde žiadna zhoda, vráti prázdny reťazec.
3. re.sub()
Funkcia nahradí zhodný text obsahom danej premennej nahradenia. Na rozdiel od iných funkcií, ak sa nenájde žiadny vzor, vráti sa pôvodný reťazec.
4. re.search()
Jednou zo základných funkcií, ktoré vám pomôžu naučiť sa analyzovať text, je funkcia vyhľadávania. Pomáha pri vyhľadávaní vzoru v reťazci a vrátení objektu zhody. Ak vyhľadávanie zlyhá pri identifikácii zhody, nevráti sa žiadna hodnota.
5. re.compile (vzor)
Táto funkcia sa používa na zostavenie vzorov regulárneho výrazu do objektu RegexObject, o ktorom sme hovorili vyššie.
Iné požiadavky
Uvedené požiadavky sú ďalšou funkciou, ktorú používajú pokročilí programátori pri analýze údajov.
Prečítajte si tiež:Ako nainštalovať NumPy na Windows 10
Proces analýzy textu
Spôsob analýzy textu v tejto komplexnej možnosti je opísaný nižšie.
Príkaz údaje = pd. DataFrame (údaje) sa používa na vytvorenie dátového rámca pandas z hodnôt dict. Prípadne môžete na príslušný účel použiť nasledujúce príkazy, ako je uvedené nižšie.
Posledným krokom k tomu, aby ste vedeli, ako analyzovať text, je otestovať analyzátor pomocou ak vyhlásenie priradením hodnôt do premennej údajov a vytlačiť ho pomocou tlačiť (dáta) príkaz.
Príklad kódu pre vyššie uvedené vysvetlenie je uvedený tu.
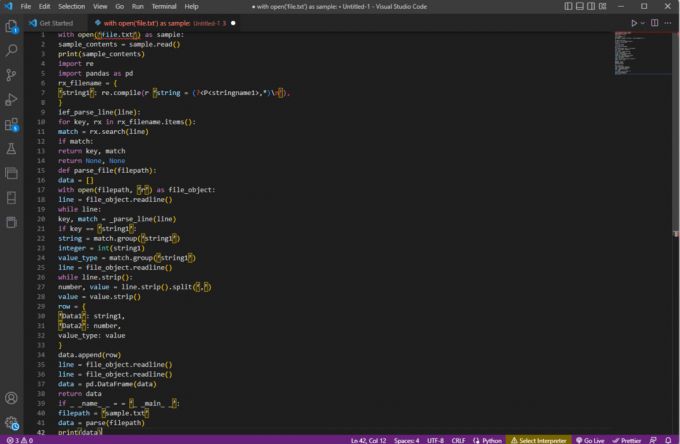
s open('file.txt') ako vzor:sample_contents = sample.read()vytlačiť (sample_contents)import reimportovať pandy ako pdrx_filename = {‘reťazec1’: re.compile (r ‘reťazec = (?,*)\n'),
}ief_parse_line (riadok):pre kľúč, rx v rx_filename.items():zhoda = rx.search (riadok)ak sa zhoduje:návratový kľúč, zápasnávrat Žiadne, Žiadnedef parse_file (cesta k súboru):údaje = []s otvoreným (cesta k súboru, „r“) ako objekt_súboru:riadok = file_object.readline()while line:kľúč, zhoda = _parse_line (riadok)if key == ‘reťazec1’:string = match.group(‘reťazec1’)celé číslo = int (reťazec1)value_type = match.group(‘reťazec1’)riadok = file_object.readline()while line.strip():číslo, hodnota = line.strip().split(‘,’)hodnota = hodnota.strip()riadok = {"Údaje1": reťazec1,"Data2": číslo,value_type: hodnota}data.append (riadok)riadok = file_object.readline()riadok = file_object.readline()údaje = pd. DataFrame (údaje)vrátiť údajeak _ _meno_ _ = = „_ _hlavný_ _“:cesta k súboru = ‘sample.txt’údaje = analyzovať (cesta k súboru)tlačiť (dáta)
Proces prevodu textu alebo korpusu na tokeny alebo menšie časti na základe určitých pravidiel sa nazýva tokenizácia. Ak sa chcete dozvedieť, ako opraviť chybu analýzy, je dôležité analyzovať príkazy tokenizácie slova v kóde. Podobne ako v prípade regulárneho výrazu je možné touto metódou vytvárať vlastné pravidlá a pomáha pri úlohách predbežného spracovania textu, ako je napríklad mapovanie slovných druhov. V tejto metóde sa vykonávajú aj činnosti, ako je vyhľadávanie a porovnávanie bežných slov, čistenie textu a príprava údajov na pokročilé techniky textovej analýzy, ako je analýza sentimentu. Ak je tokenizácia nesprávna, môže sa vyskytnúť chyba pri analýze textu x.
Knižnica NLTK
Proces využíva populárnu knižnicu jazykových nástrojov s názvom NLTK, ktorá má bohatú sadu funkcií na vykonávanie mnohých úloh NLP. Môžete si ich stiahnuť prostredníctvom balíkov Pip alebo Pip Installs Packages. Ak chcete vedieť, ako analyzovať text, môžete použiť základný balík distribúcie Anaconda, ktorý štandardne obsahuje knižnicu.
Formy tokenizácie
Bežné formy tejto metódy sú slovná tokenizácia a vetná tokenizácia. Vďaka tokenu na úrovni slova prvý vytlačí jedno slovo iba raz, zatiaľ čo druhý vytlačí slovo na úrovni vety.
Proces analýzy textu
Kód vysvetľujúci vyššie uvedené kroky na tokenizáciu je uvedený tu.
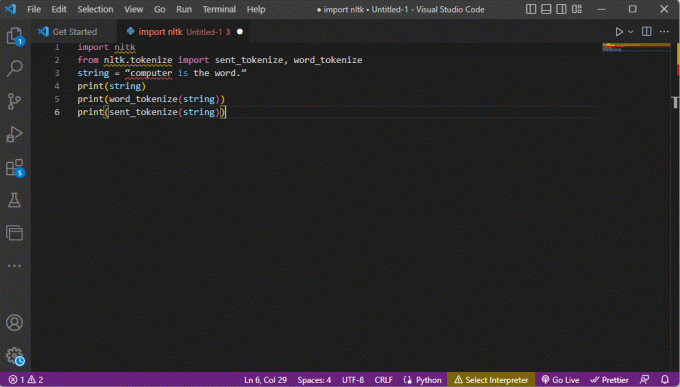
importovať nltkz nltk.tokenize importovať send_tokenize, word_tokenizestring = "počítač je slovo."tlač (reťazec)print (word_tokenize (reťazec))print (sent_tokenize (reťazec))
Prečítajte si tiež:Ako opraviť javascript: void (0) Chyba
Podobne ako trieda DataFrame, aj trieda DocParser sa dá použiť na analýzu textu v kóde. Trieda vám umožňuje volať funkciu parse s cestou k súboru.
Proces analýzy textu
Ak chcete vedieť, ako analyzovať text pomocou triedy DocParser, postupujte podľa pokynov uvedených nižšie.
Poznámka: Ak chcete vedieť, ako opraviť chybu analýzy, táto funkcia musí byť implementovaná správne.
Textový nástroj Parse sa používa na extrahovanie konkrétnych údajov z premenných a ich mapovanie na iné premenné. Toto je nezávislé od akýchkoľvek iných nástrojov používaných v úlohe a nástroj BPA Platform sa používa na spotrebu a výstup premenných. Použite tu uvedený odkaz na prístup k Nástroj na analýzu textu online a použite vyššie uvedené odpovede na to, ako analyzovať text.

TextFieldParser využíval objekty na analýzu a spracovanie veľmi veľkých súborov, ktoré sú štruktúrované a oddelené. V tejto metóde možno použiť šírku a stĺpec textu, ako sú protokolové súbory alebo informácie o starej databáze. Metóda analýzy je podobná iterácii kódu cez textový súbor a používa sa hlavne na extrahovanie polí textu podobných metódam manipulácie s reťazcami. Toto sa vykonáva na tokenizáciu oddelených reťazcov a polí rôznych šírok pomocou definovaného oddeľovača, ako je čiarka alebo tabulátor.
Funkcie na analýzu textu
Pri tejto metóde možno na analýzu textu použiť nasledujúce funkcie.
Metódy na nájdenie MatchObject
Existujú dva základné spôsoby, ako nájsť MatchObject v kóde alebo v analyzovanom texte.
V oboch prípadoch, ak pole nezodpovedá zadanému formátu počas vykonávania analýzy alebo hľadania spôsobu analýzy textu, a MalformedLineException sa vráti výnimka.
Ako poslednú a jednoduchú metódu na analýzu textu môžete použiť MS Excel aplikáciu ako analyzátor na vytváranie súborov oddelených tabulátormi a čiarkami. Pomohlo by to pri krížovej kontrole s vaším analyzovaným výsledkom a pomohlo by to nájsť spôsob, ako opraviť chybu analýzy.
1. Vyberte hodnoty údajov v zdrojovom súbore a stlačte tlačidlo Klávesy Ctrl + C spolu skopírovať súbor.
2. Otvor Excel pomocou vyhľadávacieho panela systému Windows.

3. Klikni na A1 bunku a stlačte tlačidlo Klávesy Ctrl + V súčasne vložiť skopírovaný text.
4. Vyberte A1 prejdite na bunku Údaje a kliknite na Text do stĺpcov možnosť v Dátové nástroje oddiele.
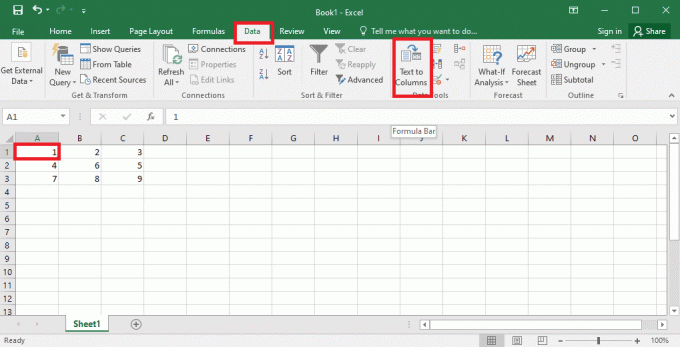
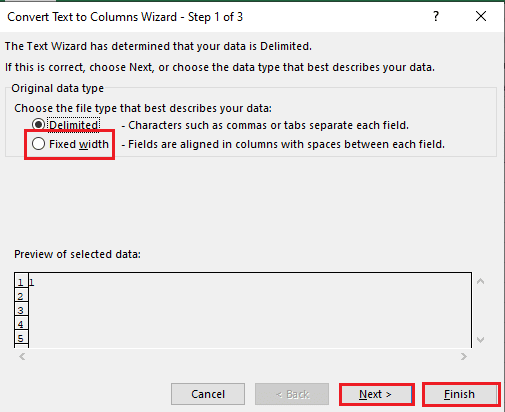
5A. Vyberte Vymedzené možnosť, ak a čiarka alebo tab ako oddeľovač sa použije medzera a kliknite na Ďalšie a Skončiť tlačidlá.

5B. Vyberte Pevná šírka možnosť, priraďte hodnotu pre oddeľovač a kliknite na Ďalšie a Skončiť tlačidlá.
Prečítajte si tiež:Ako opraviť chybu stĺpca Move Excel
Chyba pri analýze textu x sa môže vyskytnúť na zariadeniach so systémom Android, pretože: Chyba analýzy: Pri analýze balíka sa vyskytol problém. K tomu zvyčajne dochádza, keď sa aplikácia nepodarí nainštalovať z Obchodu Google Play alebo keď je spustená aplikácia tretej strany.
Chybový text x sa môže vyskytnúť, ak je zoznam znakových vektorov zacyklený a ostatné funkcie tvoria lineárny model na výpočet hodnôt údajov. Chybové hlásenie je Error in parse (text = x, keep.source = FALSE):
Článok si môžete prečítať na ako opraviť chybu analýzy v systéme Android zistiť príčiny a metódy na odstránenie chyby.
Okrem riešení v príručke môžete vyskúšať aj nasledujúce opravy.
Odporúčané:
Článok pomáha pri výučbe ako analyzovať text a zistiť, ako opraviť chybu analýzy. Dajte nám vedieť, ktorá metóda pomohla opraviť chybu v analýze textu x a ktorá metóda analýzy je uprednostňovaná. Podeľte sa o svoje návrhy a otázky v sekcii komentárov nižšie.

